Тази статия разглежда някои по-малко известни функции и ограничения на оптимизатора на заявки и обяснява причините за изключително лоша производителност на хеш присъединяване в конкретен случай.
Примерни данни
Примерният скрипт за създаване на данни, който следва, разчита на съществуваща таблица с числа. Ако вече нямате един от тях, скриптът по-долу може да се използва за ефективно създаване на такъв. Получената таблица ще съдържа една колона с цяло число с числа от един до един милион:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
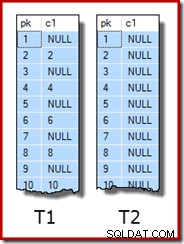
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Самите примерни данни се състоят от две таблици, T1 и T2. И двете имат колона с последователен целочислен първичен ключ, наречена pk, и втора колона с нула с име c1. Таблица T1 има 600 000 реда, където четните редове имат същата стойност за c1 като pk колоната, а редовете с нечетни номера са нулеви. Таблица c2 има 32 000 реда, където колона c1 е NULL във всеки ред. Следният скрипт създава и попълва тези таблици:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Първите десет реда примерни данни във всяка таблица изглеждат така:
Съединяване на двете таблици
Този първи тест включва свързване на двете таблици в колона c1 (не колоната pk) и връщане на pk стойността от таблица T1 за редове, които се съединяват:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Заявката всъщност няма да върне редове, защото колона c1 е NULL във всички редове на таблица T2, така че нито един ред не може да съответства на предиката за присъединяване на равенство. Това може да звучи като странно нещо, но съм уверен, че се основава на реална заявка за производство (значително опростена за по-лесно обсъждане).
Имайте предвид, че този празен резултат не зависи от настройката на ANSI_NULLS, защото това контролира само как се обработват сравненията с нулев литерал или променлива. За сравнения на колони предикатът за равенство винаги отхвърля нулеви стойности.
Планът за изпълнение на тази проста заявка за присъединяване има някои интересни функции. Първо ще разгледаме плана за предварително изпълнение („приблизителен“) в SQL Sentry Plan Explorer:
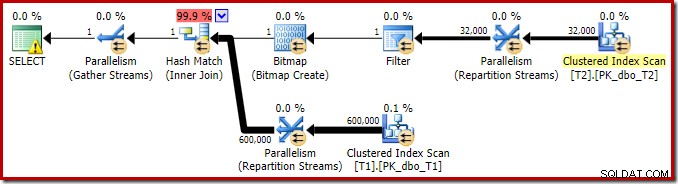
Предупреждението на иконата SELECT просто се оплаква от липсващ индекс в таблица T1 за колона c1 (с pk като включена колона). Предложението за индекс тук е без значение.
Първият истински интересен елемент в този план е филтърът:
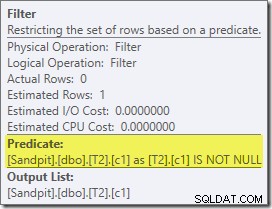
Този предикат IS NOT NULL не се появява в изходната заявка, въпреки че е подразбираща се в предиката на присъединяване, както беше споменато по-горе. Интересно е, че е разбит като изричен допълнителен оператор и поставен преди операцията за присъединяване. Имайте предвид, че дори и без филтъра, заявката пак ще даде правилни резултати – самото присъединяване пак ще отхвърли нулевите стойности.
Филтърът е любопитен и по други причини. Приблизителната му цена е точно нула (въпреки че се очаква да работи на 32 000 реда) и не е избутана надолу в Clustered Index Scan като остатъчен предикат. Оптимизаторът обикновено има голямо желание да направи това.
И двете неща се обясняват с факта, че този филтър е въведен при пренаписване след оптимизация. След като оптимизаторът на заявки завърши своята обработка, базирана на разходите, има относително малък брой пренаписвания на фиксиран план, които се разглеждат. Един от тях е отговорен за въвеждането на филтъра.
Можем да видим резултата от избора на базиран на разходите план (преди пренаписването) с помощта на недокументирани флагове за проследяване 8607 и познатия 3604 за насочване на текстово извеждане към конзолата (раздел за съобщения в SSMS):
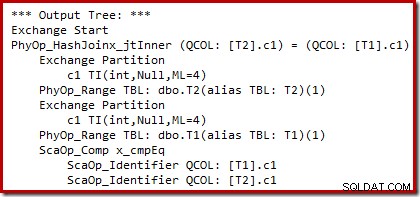
Изходното дърво показва хеш присъединяване, две сканирания и някои оператори на паралелизъм (обмен). Няма филтър с отхвърляне на нула в колоната c1 на таблица T2.
Конкретното пренаписване след оптимизация гледа изключително на входа за изграждане на хеш присъединяване. В зависимост от неговата оценка на ситуацията, той може да добави изричен филтър за отхвърляне на редове, които са нулеви в ключа за присъединяване. Ефектът на филтъра върху прогнозния брой редове също се записва в плана за изпълнение, но тъй като оптимизацията на базата на разходите вече е завършена, цената за филтъра не се изчислява. В случай, че не е очевидно, изчислителните разходи са загуба на усилия, ако всички решения, основани на разходите, вече са взети.
Филтърът остава директно върху входа за изграждане, вместо да бъде избутан надолу в сканирането на клъстериран индекс, тъй като основната оптимизационна дейност е приключила. Пренаписванията след оптимизация са ефективно промени в последната минута на завършен план за изпълнение.
Второ и доста отделно пренаписване след оптимизация е отговорно за оператора Bitmap в крайния план (може да сте забелязали, че липсва и в изхода 8607):
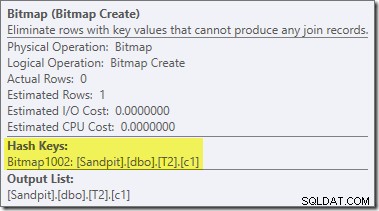
Този оператор също има нулева прогнозна цена както за I/O, така и за CPU. Другото нещо, което го идентифицира като оператор, въведен от късна настройка (вместо по време на оптимизация, базирана на разходите), е, че името му е Bitmap, последвано от число. Има и други типове растерни изображения, въведени по време на оптимизация въз основа на разходите, както ще видим малко по-късно.
Засега важното за това растерно изображение е, че записва c1 стойности, наблюдавани по време на фазата на изграждане на хеш присъединяването. Завършеното растерно изображение се изтласква към пробната страна на съединението, когато хешът преминава от фаза на изграждане към фаза на проба. Растерното изображение се използва за извършване на ранно намаляване на полусъединяване, елиминиране на редове от страната на сондата, които не могат да се присъединят. ако имате нужда от повече подробности за това, моля, вижте предишната ми статия по темата.
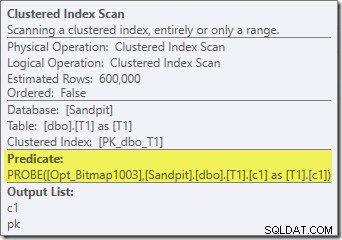
Вторият ефект на растерното изображение може да се види при сканирането на клъстериран индекс от страна на сондата:
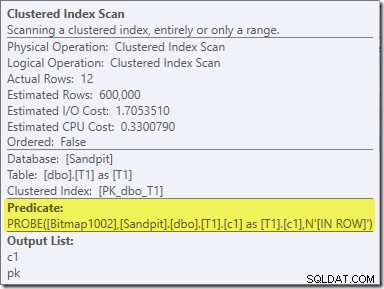
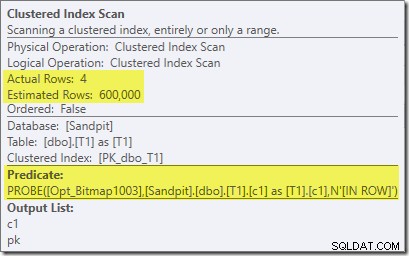
Екранната снимка по-горе показва завършеното растерно изображение, което се проверява като част от сканирането на клъстериран индекс на таблица T1. Тъй като колоната източник е цяло число (bigint също би работил), проверката на растерното изображение се изтласква докрай в механизма за съхранение (както е посочено от квалификатора 'INROW'), вместо да се проверява от процесора на заявки. По-общо казано, растерното изображение може да се приложи към всеки оператор от страната на сондата, от обмена надолу. Доколко процесорът на заявки може да изтласка растерната карта зависи от типа на колоната и версията на SQL Server.
За да завършим анализа на основните характеристики на този план за изпълнение, трябва да разгледаме плана след изпълнение („действителен“):
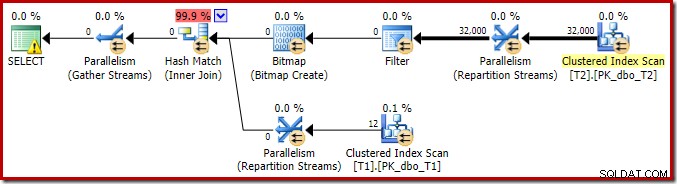
Първото нещо, което трябва да забележите, е разпределението на редовете между нишките между сканирането T2 и обмена на Repartition Streams непосредствено над него. При едно тестово изпълнение видях следната дистрибуция на система с четири логически процесора:
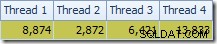
Разпределението не е особено равномерно, както често се случва при паралелно сканиране на сравнително малък брой редове, но поне всички нишки са получили известна работа. Разпределението на нишките между същия обмен на потоци за преразпределение и филтъра е много различно:
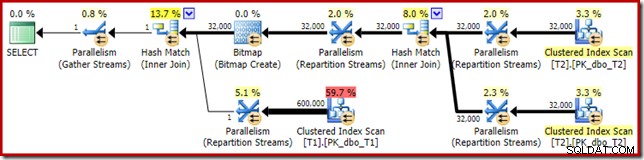
Това показва, че всичките 32 000 реда от таблица T2 са били обработени от една нишка. За да разберем защо, трябва да разгледаме свойствата на обмен:

Този обмен, подобно на този от страна на пробната страна на хеш присъединяването, трябва да гарантира, че редовете със същите стойности на ключа за присъединяване се озовават в същия екземпляр на хеш присъединяването. В DOP 4 има четири хеш обединения, всяко със собствена хеш таблица. За правилни резултати, редовете от страна на изграждане и редове от страна на сондата със същите ключове за свързване трябва да достигнат до едно и също хеш присъединяване; в противен случай може да проверим ред от страната на сондата спрямо грешната хеш таблица.
В паралелен план с редов режим SQL Server постига това чрез преразпределение на двата входа, използвайки една и съща хеш функция на колоните за свързване. В настоящия случай присъединяването е в колона c1, така че входните данни се разпределят между нишки чрез прилагане на хеш функция (тип на разделяне:хеш) към колоната на ключа за присъединяване (c1). Проблемът тук е, че колона c1 съдържа само една стойност – null – в таблица T2, така че на всички 32 000 реда се дава една и съща хеш стойност, тъй като всички се озовават в една и съща нишка.
Добрата новина е, че нищо от това наистина няма значение за тази заявка. Филтърът за презаписване след оптимизация елиминира всички редове, преди да е свършена много работа. На моя лаптоп заявката по-горе се изпълнява (не дава резултати, както се очаква) за около 70 мс .
Съединяване на три таблици
За втория тест добавяме допълнително присъединяване от таблица T2 към себе си на нейния първичен ключ:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Това не променя логическите резултати от заявката, но променя плана за изпълнение:
Както се очакваше, самообединяването на таблица T2 на нейния първичен ключ няма ефект върху броя на редовете, които отговарят на условията от тази таблица:
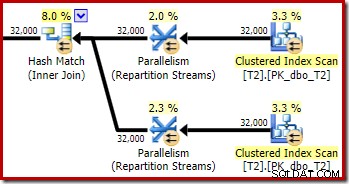
Разпределението на редовете между нишките също е добро в този раздел на плана. За сканирането е подобно на предишното, тъй като паралелното сканиране разпределя редове към нишки при поискване. Размените се преразпределят въз основа на хеш на ключа за присъединяване, който този път е колоната pk. Като се има предвид диапазона от различни стойности на pk, полученото разпределение на нишките също е много равномерно:
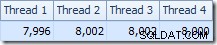
Обръщайки се към по-интересната част от прогнозния план, има някои разлики от теста с две таблици:

За пореден път обменът от страна на компилацията в крайна сметка насочва всички редове към една и съща нишка, защото c1 е ключът за присъединяване и следователно колоната за разделяне за обмените на Repartition Streams (не забравяйте, че c1 е нула за всички редове в таблица T2).
Има две други важни разлики в този раздел на плана в сравнение с предишния тест. Първо, няма филтър за премахване на null-c1 редове от страната на изграждане на хеш присъединяването. Обяснението за това е свързано с втората разлика – растерното изображение се е променило, макар че не е очевидно от снимката по-горе:
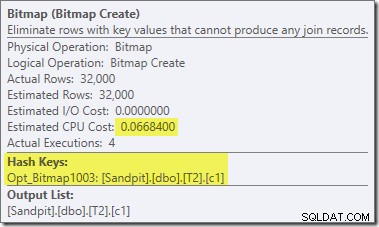
Това е Opt_Bitmap, а не растерно изображение. Разликата е, че това растерно изображение е въведено по време на оптимизация, базирана на разходите, а не чрез пренаписване в последната минута. Механизмът, който разглежда оптимизирани растерни изображения, е свързан с обработката на заявки за свързване със звезда. Логиката на свързване в звезда изисква поне три свързани таблици, така че това обяснява защо оптимизиран растерното изображение не беше взето предвид в примера за свързване с две таблици.
Тази оптимизирана растерна карта има ненулева прогнозна цена на процесора и пряко засяга цялостния план, избран от оптимизатора. Неговият ефект върху оценката за мощността от страна на сондата може да се види при оператора Repartition Streams:
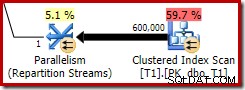
Обърнете внимание, че ефектът на кардиналността се вижда при обмена, въпреки че растерното изображение в крайна сметка се изтласква докрай в механизма за съхранение („INROW“), точно както видяхме в първия тест (но обърнете внимание на препратката Opt_Bitmap сега):
Планът след изпълнение („действителен“) е както следва:
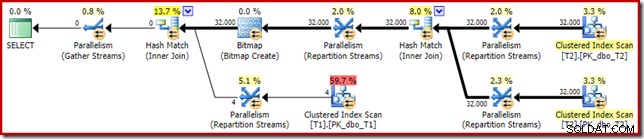
Прогнозната ефективност на оптимизираното растерно изображение означава, че отделното пренаписване след оптимизация за нулевия филтър не се прилага. Лично аз смятам, че това е жалко, защото елиминирането на нулевите стойности по-рано с филтър би отменило необходимостта от изграждане на растерното изображение, попълване на хеш таблиците и извършване на сканиране с подобрена растерна карта на таблица T1. Независимо от това, оптимизаторът решава друго и в този случай просто няма спор с него.
Въпреки допълнителното самообединяване на таблица T2 и допълнителната работа, свързана с липсващия филтър, този план за изпълнение все още дава очаквания резултат (без редове) за бързо време. Типичното изпълнение на моя лаптоп отнема около 200 мс .
Промяна на типа данни
За този трети тест ще променим типа данни на колона c1 в двете таблици от цяло число на десетично. Няма нищо особено специално в този избор; същият ефект може да се види с всеки числов тип, който не е целочислен или голям.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Повторно използване на заявката за три присъединяване:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Приблизителният план за изпълнение изглежда много познат:
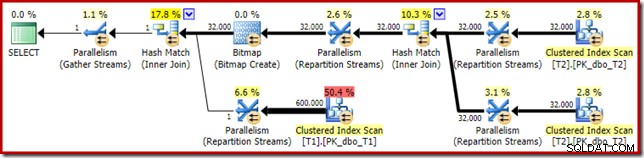
Освен факта, че оптимизираната растерна карта вече не може да се прилага „INROW“ от механизма за съхранение поради промяната на типа данни, планът за изпълнение е по същество идентичен. Заснемането по-долу показва промяната в свойствата на сканиране:
За съжаление, производителността е доста драматично засегната. Тази заявка се изпълнява не за 70 мс или 200 мс, а за около 20 минути . В теста, който създаде следния план след изпълнение, времето за изпълнение всъщност беше 22 минути и 29 секунди:

Най-очевидната разлика е, че Clustered Index Scan на таблица T1 връща 300 000 реда дори след прилагане на оптимизирания филтър за растерни изображения. Това има някакъв смисъл, тъй като растерното изображение е изградено върху редове, които съдържат само нулеви стойности в колоната c1. Растерната карта премахва ненулеви редове от T1 сканирането, оставяйки само 300 000 реда с нулеви стойности за c1. Не забравяйте, че половината редове в T1 са нулеви.
Въпреки това изглежда странно, че свързването на 32 000 реда с 300 000 реда трябва да отнеме над 20 минути. В случай, че се чудите, едно ядро на процесора беше фиксирано на 100% за цялото изпълнение. Обяснението за тази лоша производителност и екстремно използване на ресурси се основава на някои идеи, които проучихме по-рано:
Вече знаем, например, че въпреки иконите за паралелно изпълнение, всички редове от T2 се озовават в една и съща нишка. Като напомняне, паралелното хеш присъединяване в редов режим изисква преразпределение на колоните за свързване (c1). Всички редове от T2 имат една и съща стойност – нула – в колона c1, така че всички редове се озовават в една и съща нишка. По същия начин всички редове от T1, които преминават филтъра за растерни изображения, също имат нула в колона c1, така че те също се преразпределят в една и съща нишка. Това обяснява защо едно ядро върши цялата работа.
Все още може да изглежда неразумно хеш, свързващ 32 000 реда с 300 000 реда, да отнеме 20 минути, особено след като колоните за свързване от двете страни са нулеви и така или иначе няма да се присъединят. За да разберем това, трябва да помислим как работи това хеш присъединяване.
Входът за изграждане (32 000 реда) създава хеш таблица, използвайки колоната за присъединяване, c1. Тъй като всеки ред от страна на изграждане съдържа една и съща стойност (нула) за колона за присъединяване c1, това означава, че всичките 32 000 реда се озовават в една и съща хеш кофа. Когато хеш присъединяването се превключи на проучване за съвпадения, всеки ред от страната на сондата с нулева c1 колона също хешира към една и съща кофа. След това хеш присъединяването трябва да провери всички 32 000 записа в тази кофа за съвпадение.
Проверката на 300 000 реда сонда води до 32 000 сравнения, направени 300 000 пъти. Това е най-лошият случай за хеш присъединяване:Всички изграждат хеш от страничните редове към една и съща кофа, което води до това, което по същество е декартов продукт. Това обяснява дългото време за изпълнение и постоянното 100% използване на процесора, тъй като хешът следва дългата верига за хешове.
Тази лоша производителност помага да се обясни защо съществува пренаписване след оптимизация за елиминиране на нулеви стойности на входа за изграждане към хеш присъединяване. За съжаление филтърът не беше приложен в този случай.
Заобиколни решения
Оптимизаторът избира тази форма на план, защото неправилно преценява, че оптимизираното растерно изображение ще филтрира всички редове от таблица T1. Въпреки че тази оценка е показана в потоците за преразпределение вместо в сканирането на клъстерирания индекс, това все още е в основата на решението. Като напомняне тук отново е съответният раздел от плана за предварително изпълнение:
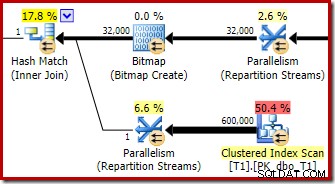
Ако това беше правилна оценка, не би отнело никакво време за обработка на хеш присъединяването. Жалко е, че оценката на селективността за оптимизираното растерно изображение е толкова много погрешна, когато типът на данните не е просто цяло число или голямо число. Изглежда, че растерната карта, изградена върху целочислен или bigint ключ, също може да филтрира нулеви редове, които не могат да се присъединят. Ако това наистина е така, това е основна причина да предпочетете колони с целочислени или големи числа.
Заобиколните решения, които следват, до голяма степен се основават на идеята за елиминиране на проблемните оптимизирани растерни изображения.
Серийно изпълнение
Един от начините да се предотврати разглеждането на оптимизирани растерни изображения е да се изисква непаралелен план. Операторите за Bitmap в режим на ред (оптимизирани или по друг начин) се виждат само в паралелни планове:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Тази заявка се изразява с помощта на малко по-различен синтаксис с подсказка FORCE ORDER за генериране на форма на план, която е по-лесно сравнима с предишните паралелни планове. Основната характеристика е подсказката MAXDOP 1.
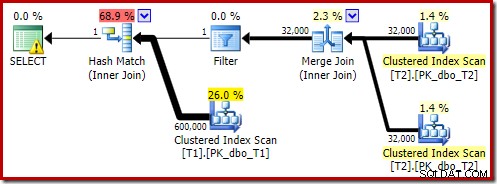
Този прогнозен план показва, че филтърът за пренаписване след оптимизация се възстановява:
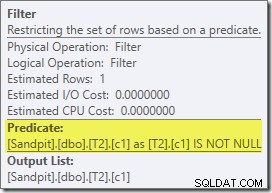
Версията на плана след изпълнение показва, че филтрира всички редове от входа за изграждане, което означава, че страничното сканиране на сондата може да бъде пропуснато напълно:
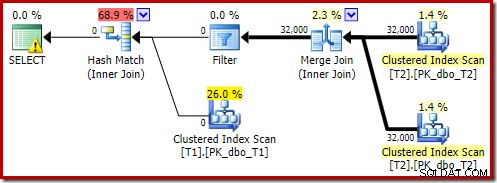
Както бихте очаквали, тази версия на заявката се изпълнява много бързо – около 20 ms средно за мен. Можем да постигнем подобен ефект без подсказката FORCE ORDER и пренаписването на заявката:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Оптимизаторът избира различна форма на план в този случай, като филтърът е поставен директно над сканирането на T2:
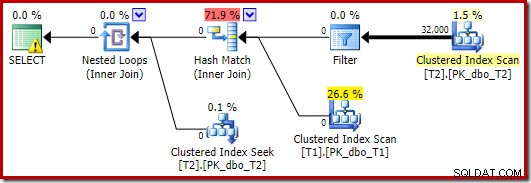
Това се изпълнява дори по-бързо – за около 10 мс – както може да се очаква. Естествено, това не би било добър избор, ако броят на наличните (и присъединяеми) редове беше много по-голям.
Изключване на оптимизирани растерни изображения
Няма намек за заявка за изключване на оптимизирани растерни изображения, но можем да постигнем същия ефект с помощта на няколко недокументирани флага за проследяване. Както винаги, това е само за лихвена стойност; не бихте искали да ги използвате в реална система или приложение:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Полученият план за изпълнение е:
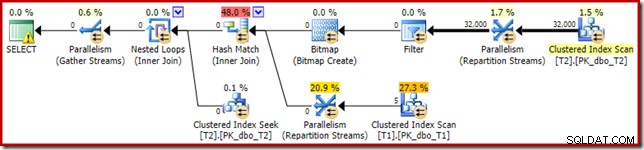
Растерното изображение има следоптимизационно пренаписано растерно изображение, а не оптимизирано растерно изображение:
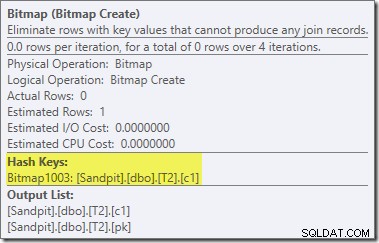
Обърнете внимание на нулевите оценки на разходите и името на растерното изображение (вместо Opt_Bitmap). без оптимизирано растерно изображение за изкривяване на оценките на разходите, се активира пренаписването след оптимизация, за да се включи филтър, отхвърлящ нула. Този план за изпълнение се изпълнява за около 70 мс .
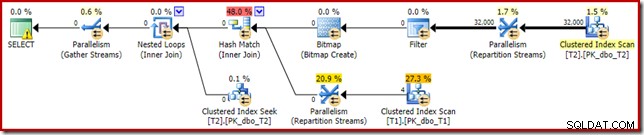
Същият план за изпълнение (с филтър и неоптимизирано растерно изображение) може също да бъде произведен чрез деактивиране на правилото за оптимизиране, отговорно за генериране на планове за растерни изображения със звезда (отново, строго недокументирани и не за употреба в реалния свят):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Включително изричен филтър
Това е най-простият вариант, но човек би си помислил да го направи само ако е наясно с обсъжданите досега проблеми. Сега, когато знаем, че трябва да елиминираме нули от T2.c1, можем да добавим това директно към заявката:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Полученият прогнозен план за изпълнение може би не е точно това, което може да очаквате:
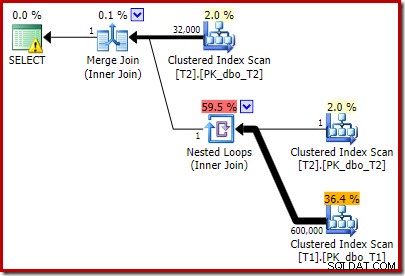
Допълнителният предикат, който добавихме, беше избутан в средното сканиране на клъстериран индекс на T2:
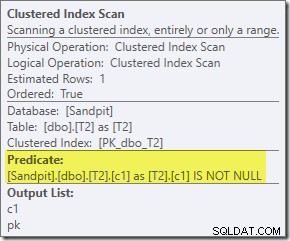
Планът след изпълнение е:
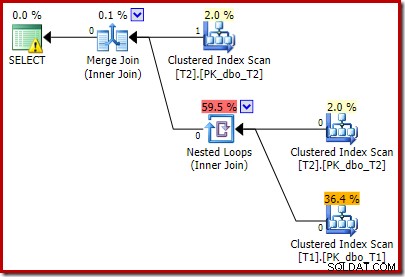
Забележете, че Merge Join се изключва, след като прочете един ред от горния си вход, след което не успява да намери ред на долния си вход, поради ефекта на предиката, който добавихме. Сканирането на клъстериран индекс на таблица T1 изобщо не се изпълнява, тъй като присъединяването с вложени цикли никога не получава ред на своя задвижващ вход. Този последен формуляр за заявка се изпълнява за една или две милисекунди.
Последни мисли
Тази статия обхваща доста място за изследване на някои по-малко известни поведения на оптимизатора на заявки и обяснява причините за изключително лоша производителност на хеш присъединяване в конкретен случай.
Може да е изкушаващо да попитате защо оптимизаторът не добавя рутинно филтри за отхвърляне на нула преди присъединяването на равенство. Може само да се предположи, че това не би било от полза в достатъчно често срещани случаи. Не се очаква повечето присъединявания да срещнат много отхвърляния null =null и рутинното добавяне на предикати може бързо да стане контрапродуктивно, особено ако присъстват много колони за присъединяване. За повечето обединения отхвърлянето на нулеви стойности в оператора за свързване вероятно е по-добър вариант (от гледна точка на модела на разходите), отколкото въвеждането на изричен филтър.
Изглежда, че има усилие да се предотврати проявата на най-лошите случаи чрез пренаписване след оптимизация, предназначено да отхвърля нулеви редове за присъединяване, преди да достигнат до входа за изграждане на хеш присъединяване. Изглежда, че съществува неудобно взаимодействие между ефекта на оптимизираните растерни филтри и приложението на това пренаписване. Също така е жалко, че когато този проблем с производителността възникне, е много трудно да се диагностицира само от плана за изпълнение.
Засега най-добрият вариант изглежда е наясно с този потенциален проблем с производителността с хеш обединения в колони с нула и да добавите изрични предикати за отхвърляне на нула (с коментар!), за да гарантирате, че е създаден ефективен план за изпълнение, ако е необходимо. Използването на подсказка MAXDOP 1 може също да разкрие алтернативен план с наличен сигнален филтър.
Като общо правило заявките, които се обединяват в колони от целочислен тип и търсят съществуващи данни, обикновено отговарят по-добре на модела на оптимизатора и възможностите на машината за изпълнение, отколкото алтернативите.
Признания
Искам да благодаря на SQL_Sasquatch (@sqL_handLe) за разрешението му да отговори на оригиналната си статия с технически анализ. Използваните тук примерни данни са до голяма степен базирани на тази статия.
Искам също така да благодаря на Роб Фарли (блог | twitter) за нашите технически дискусии през годините, и особено за една през януари 2015 г., където обсъдихме последиците от допълнителните предикати за отхвърляне на нула за екви-съединявания. Роб е писал по свързани теми няколко пъти, включително в Обратни предикати – погледнете и двете посоки, преди да пресечете.