Влизането в производство е много важна задача, която трябва да бъде внимателно обмислена и планирана предварително. Някои не толкова добри решения могат лесно да бъдат коригирани след това, но други не. Така че винаги е по-добре да отделите това допълнително време в четене на официални документи, книги и изследвания, направени от други рано, отколкото да съжалявате по-късно. Това е вярно за повечето внедрявания на компютърни системи и PostgreSQL не е изключение.
Първоначално планиране на системата
Някои решения трябва да се вземат рано, преди системата да заработи. PostgreSQL DBA трябва да отговори на редица въпроси:Ще работи ли DB на гол метал, виртуални машини или дори контейнеризирана? Ще работи ли в помещенията на организацията или в облака? Коя ОС ще се използва? Съхранението ще бъде от тип въртящи се дискове или SSD? За всеки сценарий или решение има плюсове и минуси и окончателното обаждане ще бъде направено в сътрудничество със заинтересованите страни в съответствие с изискванията на организацията. Традиционно хората са използвали PostgreSQL на гол метал, но това се промени драстично през последните години с все повече и повече облачни доставчици, предлагащи PostgreSQL като стандартна опция, което е знак за широкото приемане и резултат от нарастващата популярност на PostgreSQL. Независимо от конкретното решение, DBA трябва да гарантира, че данните ще бъдат безопасни, което означава, че базата данни ще може да оцелее при сривове и това е критерий №1 при вземане на решения за хардуер и съхранение. Така че това ни води до първия съвет!
Съвет 1
Без значение какво рекламира дисковият контролер или производителят на диск или доставчикът на облачно хранилище, винаги трябва да се уверите, че хранилището не лъже за fsync. След като fsync се върне ОК, данните трябва да са безопасни на носителя, независимо какво се случва след това (срив, прекъсване на захранването и т.н.). Един хубав инструмент, който ще ви помогне да тествате надеждността на кеша за обратно записване на вашите дискове, е diskchecker.pl.
Просто прочетете бележките:https://brad.livejournal.com/2116715.html и направете теста.
Използвайте една машина за слушане на събития и действителната машина за тестване. Трябва да видите:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0в края на отчета за тестваната машина.
Втората грижа след надеждността трябва да бъде свързана с производителността. Решенията относно системата (CPU, памет) бяха много по-важни, тъй като беше доста трудно да ги промените по-късно. Но в днешната, в облачната ера, можем да бъдем по-гъвкави относно системите, върху които работи DB. Същото важи и за съхранението, особено в ранния живот на системата и докато размерите са все още малки. Когато DB надхвърли цифрата на TB по размер, тогава става все по-трудно и по-трудно да се променят основните параметри за съхранение, без да е необходимо изцяло да се копира базата данни - или дори по-лошо, да се извърши pg_dump, pg_restore. Вторият съвет е за производителността на системата.
Съвет 2
Подобно на винаги да тествате обещанията на производителите по отношение на надеждността, същото трябва да направите и за хардуерната производителност. Bonnie++ е най-популярният еталон за производителност на съхранение за Unix-подобни системи. За цялостно тестване на системата (CPU, памет, а също и съхранение) нищо не е по-представително от производителността на DB. Така че основният тест за производителност на вашата нова система ще бъде стартирането на pgbench, официалния пакет за сравнение на PostgreSQL, базиран на TCP-B.
Започването с pgbench е сравнително лесно, всичко, което трябва да направите, е:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Винаги трябва да се консултирате с pgbench след всяка важна промяна, която искате да оцените и сравните резултатите.
Разгръщане, автоматизация и наблюдение на системата
След като пуснете на живо, е много важно основните ви системни компоненти да са документирани и възпроизводими, да имате автоматизирани процедури за създаване на услуги и повтарящи се задачи, както и да разполагате с инструментите за извършване на непрекъснат мониторинг.
Съвет 3
Един удобен начин да започнете да използвате PostgreSQL с всичките му разширени корпоративни функции е ClusterControl от Severalnines. Човек може да има PostgreSQL клъстер от корпоративен клас, само с няколко щраквания. ClusterControl предоставя всички гореспоменати услуги и много други. Настройването на ClusterControl е сравнително лесно, просто следвайте инструкциите в официалната документация. След като сте подготвили системите си (обикновено една за стартиране на CC и една за PostgreSQL за основна настройка) и извършите настройката на SSH, тогава трябва да въведете основните параметри (IPs, номера на портове и т.н.) и ако всичко върви добре, трябва вижте изход като следния:
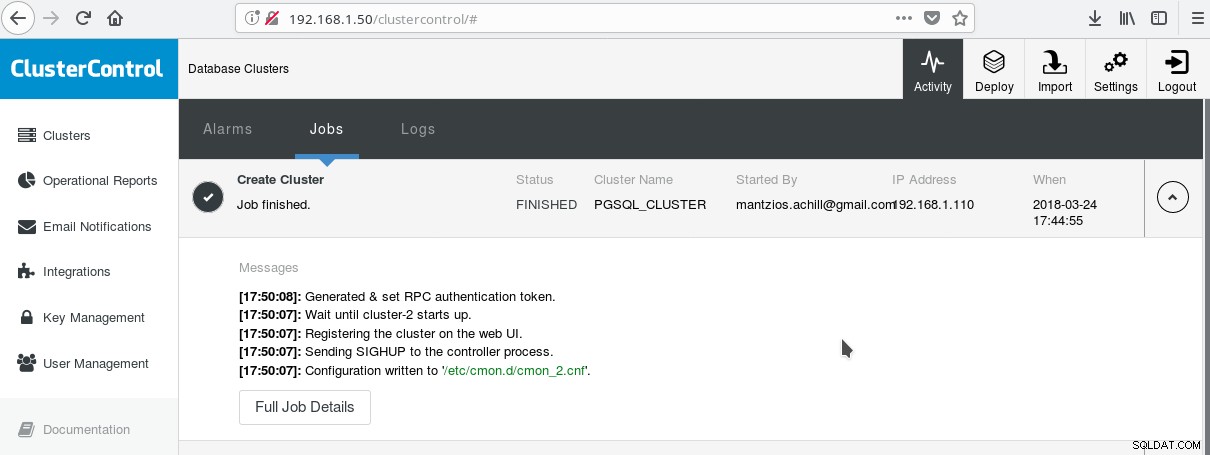
И в главния екран на клъстерите:
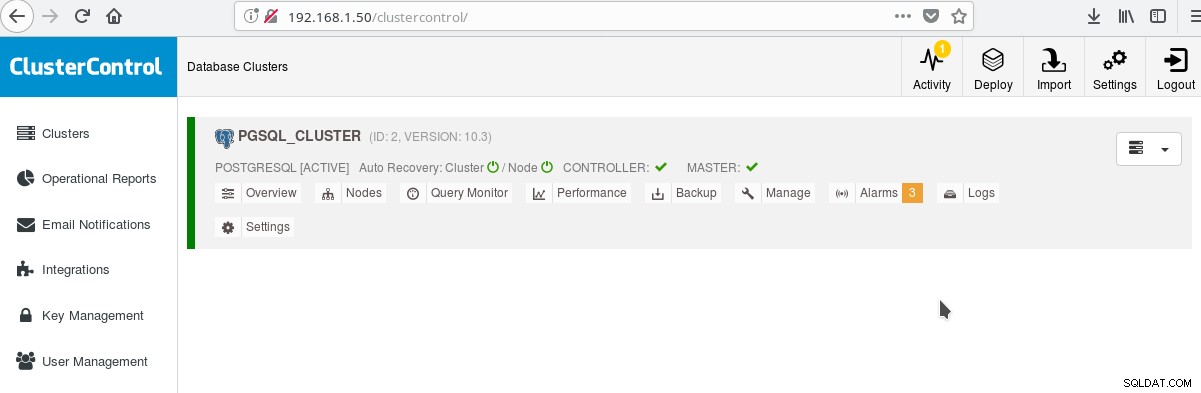
Можете да влезете във вашия главен сървър и да започнете да създавате вашата схема! Разбира се, можете да използвате като основа току-що създадения от вас клъстер за по-нататъшно изграждане на вашата инфраструктура (топология). Като цяло добра идея е да имате стабилно оформление на файловата система на сървъра и окончателна конфигурация на вашия PostgreSQL сървър и потребителски/приложни бази данни, преди да започнете да създавате клонинги и резерви (подчинени) въз основа на току-що създадения от вас чисто нов сървър.
Оформление, параметри и настройки на PostgreSQL
На фазата на инициализация на клъстера най-важното решение е дали да се използват контролни суми на данни на страниците с данни или не. Ако искате максимална безопасност на данните за вашите ценни (бъдещи) данни, тогава е моментът да го направите. Ако има шанс да искате тази функция в бъдеще и да пренебрегнете да я направите на този етап, няма да можете да я промените по-късно (без pg_dump/pg_restore това е). Това е следващият съвет:
Съвет 4
За да активирате контролните суми на данните, изпълнете initdb, както следва:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Имайте предвид, че това трябва да се направи по време на съвет 3, който описахме по-горе. Ако вече сте създали клъстера с ClusterControl, ще трябва да стартирате отново pg_createcluster на ръка, тъй като към момента на писане няма начин да кажете на системата или CC да включи тази опция.
Друга много важна стъпка, преди да влезете в производството, е планирането на оформлението на файловата система на сървъра. Повечето съвременни дистрибуции на Linux (поне базираните на debian) монтират всичко на / но с PostgreSQL обикновено не искате това. Полезно е вашето пространство за таблици да е(а) на отделен(и) том(ове), да имате един том, посветен за WAL файловете, а друг за pg log. Но най-важното е да преместите WAL на собствен диск. Това ни води до следващия съвет.
Съвет 5
С PostgreSQL 10 на Debian Stretch можете да преместите своя WAL на нов диск със следните команди (ако предположим, че новият диск се казва /dev/sdb):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlИзключително важно е да настроите правилно локала и кодирането на вашите бази данни. Пренебрегвайте това във фазата на createdb и ще съжалявате много за това, тъй като вашето приложение/БД се премести в териториите i18n, l10n. Следващият съвет показва как да направите това.
Съвет 6
Трябва да прочетете официалните документи и да вземете решение за вашите настройки COLLATE и CTYPE (createdb --locale=) (отговорни за реда на сортиране и класификация на знаците), както и настройката на набора от знаци (createdb --encoding=). Посочването на UTF8 като кодиране ще позволи на вашата база данни да съхранява многоезичен текст.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаВисока наличност на PostgreSQL
Тъй като PostgreSQL 9.0, когато стрийминг репликацията стана стандартна функция, стана възможно да има един или повече горещи режими на готовност само за четене, като по този начин се даде възможност за насочване на трафика само за четене към всеки от наличните подчинени устройства. Съществуват нови планове за многоглавна репликация, но към момента на писането (10.3) е възможно да има само един главен код за четене и запис, поне в официалния продукт с отворен код. За следващия съвет, който се занимава точно с това.
Съвет 7
Ще използваме нашия ClusterControl PGSQL_CLUSTER, създаден в Съвет 3. Първо създаваме втора машина, която ще действа като наш подчинен само за четене (горещ режим на готовност в терминологията на PostgreSQL). След това щракваме върху Add Replication slave и избираме нашия главен и новия slave. След като задачата приключи, трябва да видите този изход:
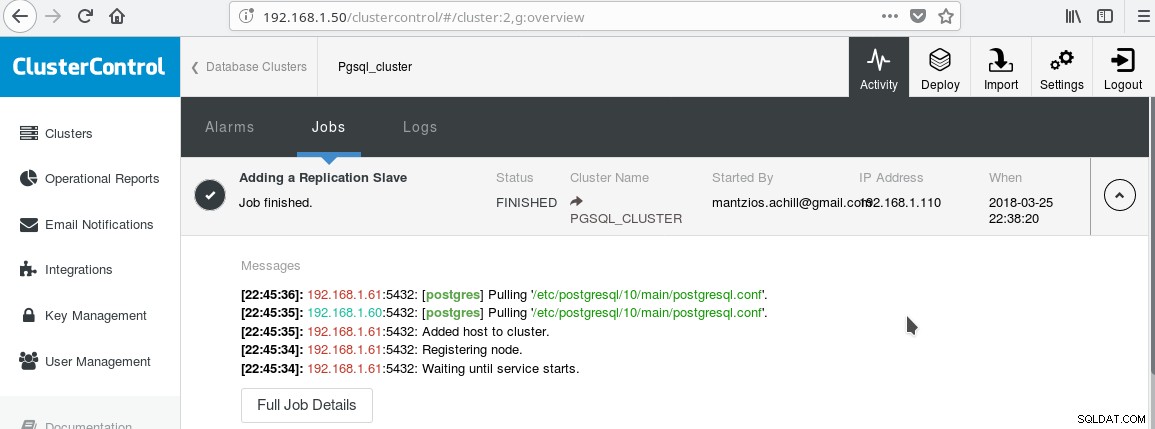
И сега клъстерът трябва да изглежда така:
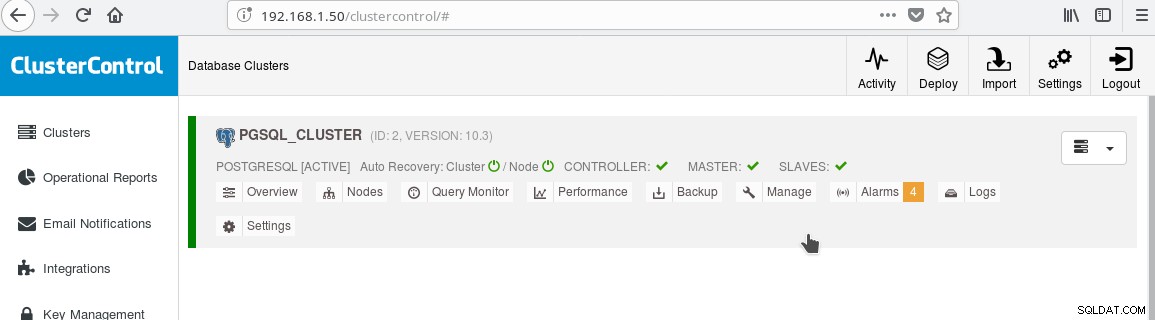
Обърнете внимание на зелената икона с отметка на етикета „SLAVES“ до „MASTER“. Можете да проверите дали репликацията на поточно предаване работи, като създадете обект на база данни (база данни, таблица и т.н.) или вмъкнете някои редове в таблица на главната страница и видите промяната в режим на готовност.
Наличието на режим на готовност само за четене ни позволява да извършваме балансиране на натоварването за клиентите, извършващи заявки само за избор между двата налични сървъра, главния и подчинения. Това ни отвежда до съвет 8.
Съвет 8
Можете да активирате балансиране на натоварването между двата сървъра с помощта на HAProxy. С ClusterControl това е доста лесно да се направи. Щракнете върху Управление-> Балансиране на натоварване. След като изберете вашия HAProxy сървър, ClusterControl ще инсталира всичко вместо вас:xinetd на всички инстанции, които сте посочили, и HAProxy на вашия сървър, определен от HAProxy. След като задачата приключи успешно, трябва да видите:
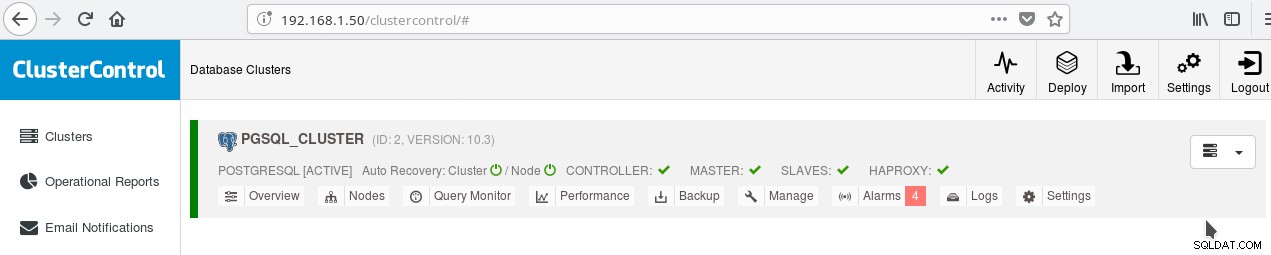
Обърнете внимание на зелената отметка HAPROXY до РОБИТЕ. Сега можете да тествате дали HAProxy работи:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Съвет 9
Освен конфигуриране за HA и балансиране на натоварването, винаги е полезно да имате някакъв пул за връзки пред сървъра на PostgreSQL. Pgpool и Pgbouncer са два проекта, идващи от общността на PostgreSQL. Много сървъри за корпоративни приложения също предоставят свои собствени пулове. Pgbouncer е много популярен поради своята простота, бързина и функцията „обединяване на транзакции“, чрез която връзката със сървъра се освобождава, след като транзакцията приключи, което я прави повторно използваема за следващи транзакции, които могат да дойдат от същата сесия или друга . Настройката за обединяване на транзакции нарушава някои функции за обединяване на сесии, но като цяло преобразуването към настройка, готова за „обединяване на транзакции“, е лесно и минусите не са толкова важни в общия случай. Често срещана настройка е да конфигурирате пула на сървъра на приложения с полу-постоянни връзки:Доста по-голям пул от връзки на потребител или на приложение (които се свързват с pgbouncer) с дълги изчаквания на неактивност. По този начин времето за свързване от приложението е минимално, докато pgbouncer ще ви помогне да запазите връзките със сървъра възможно най-малко.
Едно нещо, което най-вероятно ще бъде тревожно, след като започнете да работите с PostgreSQL, е разбирането и коригирането на бавни заявки. Инструментите за наблюдение, които споменахме в предишния блог като pg_stat_statements, както и екраните на инструменти като ClusterControl ще ви помогнат да идентифицирате и евентуално да предложите идеи за коригиране на бавни заявки. След като обаче идентифицирате бавната заявка, ще трябва да стартирате EXPLAIN или EXPLAIN ANALYZE, за да видите точно разходите и времето, включени в плана за заявка. Следващият съвет е за много полезен инструмент, за да направите това.
Съвет 10
Трябва да стартирате своя EXPLAIN ANALYZE във вашата база данни и след това да копирате изхода и да го поставите в онлайн инструмента за анализ на обяснения на depesz и щракнете върху изпращане. След това ще видите три раздела:HTML, TEXT и STATS. HTML съдържа цена, време и брой цикли за всеки възел в плана. Разделът СТАТИСТИКИ показва статистика за всеки тип възел. Трябва да наблюдавате колоната „% от заявката“, за да знаете къде точно се намира заявката ви.
Когато се запознаете по-добре с PostgreSQL, сами ще намерите много повече съвети!