[ Част 1 | Част 2 | Част 3 ]
В част 1 от тази серия изпробвах няколко начина за компресиране на таблица от 1TB. Въпреки че получих прилични резултати в първия си опит, исках да видя дали мога да подобря производителността в част 2. Там очертах няколко от нещата, които смятах, че може да са проблеми с производителността, и изложих как по-добре да разделя таблицата на местоназначението за оптимална компресия в columnstore. Вече:
- раздели таблицата на 8 дяла (по един на ядро);
- поставете файла с данни на всеки дял в собствена файлова група; и,
- задайте компресиране на архива на всички, освен на „активния“ дял.
Все още трябва да направя така, че всеки планировчик да пише изключително в своя собствен дял.
Първо, трябва да направя промени в пакетната таблица, която създадох. Имам нужда от колона за съхраняване на броя на добавените редове на партида (вид самопроверяваща се проверка за здравина) и начални/крайни времена за измерване на напредъка.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
След това трябва да създам таблица, за да осигуря афинитет – ние никога не искаме повече от един процес да работи на който и да е планировчик, дори ако това означава да загубим известно време за повторен опит на логиката. Така че имаме нужда от таблица, която ще следи всяка сесия на конкретен планировчик и ще предотврати подреждането:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Идеята е, че ще имам осем екземпляра на приложение (SQLQueryStress), всяко от които ще работи на специален планировчик, обработвайки само данните, предназначени за конкретен дял / файлова група / файл с данни, ~ 100 милиона реда наведнъж (щракнете, за да увеличите) :
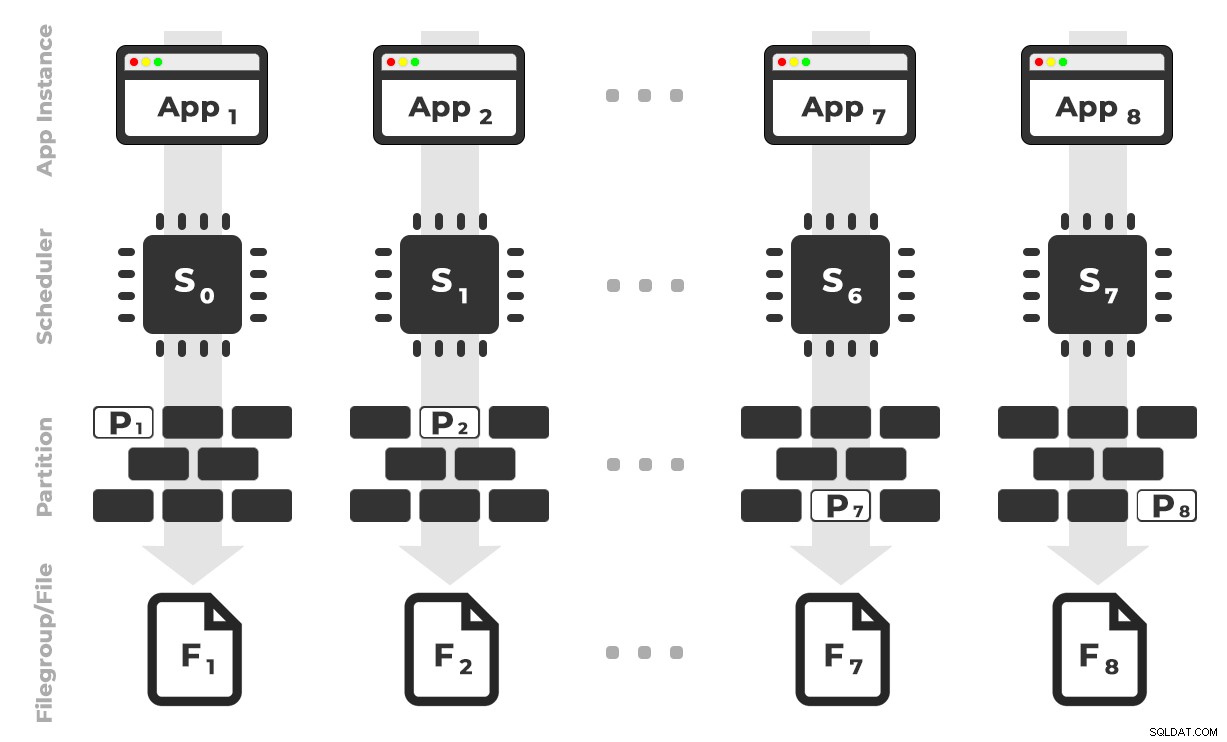 Приложение 1 получава планировчик 0 и записва в дял 1 във файлова група 1 и т.н. …
Приложение 1 получава планировчик 0 и записва в дял 1 във файлова група 1 и т.н. …
След това се нуждаем от съхранена процедура, която ще позволи на всеки екземпляр на приложението да резервира време за един планировчик. Както споменах в предишна публикация, това не е първоначалната ми идея (и никога нямаше да я намеря в това ръководство, ако не беше Джо Оббиш). Ето процедурата, която създадох в Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Просто, нали? Задействайте 8 екземпляра на SQLQueryStress и поставете тази партида във всеки:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
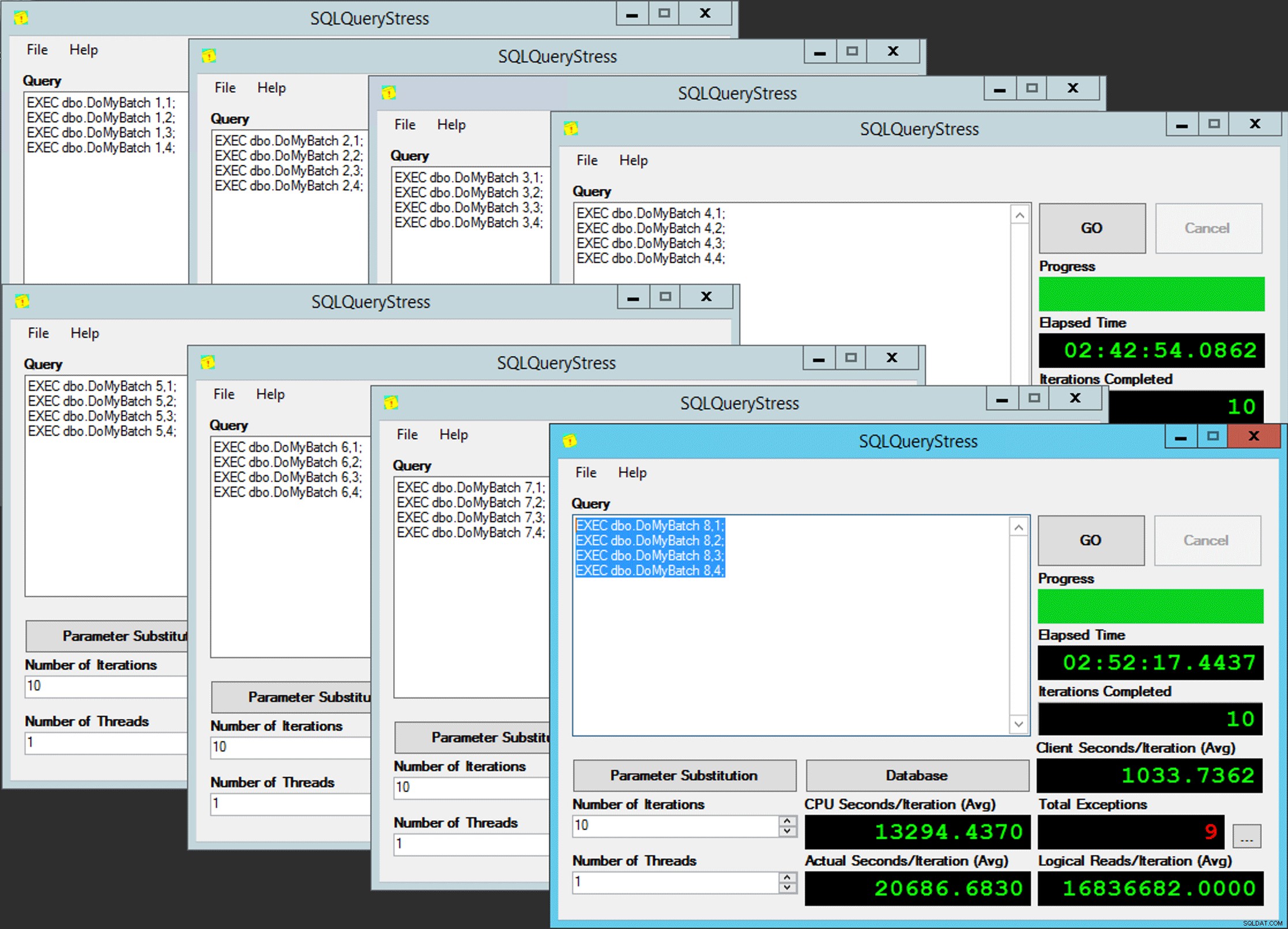 Паралелизъм на бедния човек
Паралелизъм на бедния човек
Само дето не е толкова просто, тъй като присвояването на графика е нещо като кутия шоколадови бонбони. Отне много опити, за да се получи всеки екземпляр на приложението в очаквания планировчик; Бих проверил изключенията във всеки даден екземпляр на приложението и бих променил PartitionID да съвпадне. Ето защо използвах повече от една итерация (но все пак исках само една нишка на екземпляр). Като пример, този екземпляр на приложението очакваше да бъде на планировчик 3, но получи планировчик 4:
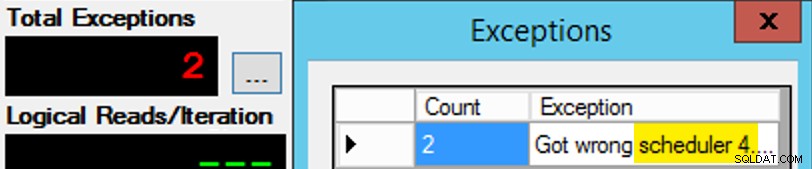 Ако отначало не успеете…
Ако отначало не успеете…
Промених 3s в прозореца на заявката на 4s и опитах отново. Ако бях бърз, заданието на планировщика беше достатъчно "лепкаво", че щеше да го вземе веднага и да започне да се отпуска. Но не винаги бях достатъчно бърз, така че беше нещо като удар на къртица да тръгвам. Вероятно бих могъл да измисля по-добра рутина за повторен опит/зацикляне, за да направя работата по-малко ръчна тук, и да съкратя забавянето, така че веднага да знам дали работи или не, но това беше достатъчно добро за моите нужди. Това също така доведе до неволно зашеметяване на началните времена за всеки процес, още един съвет от г-н Obbish.
Наблюдение
Докато афинитизираното копие се изпълнява, мога да получа намек за текущото състояние със следните две заявки:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Ако направих всичко правилно, и двете заявки ще върнат 8 реда и ще показват нарастващи логически четения и продължителност. Типовете изчакване ще се обръщат между PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , а понякога и RESERVED_MEMORY_ALLOCATION_EXT. Когато партидата беше завършена (мога да ги прегледам, като премахна коментара -- AND EndTime IS NULL , бих потвърдил, че RowsAdded = RowsInRange .
След като всички 8 екземпляра на SQLQueryStress бяха завършени, можех просто да извърша SELECT INTO <newtable> FROM dbo.BatchQueue за да регистрирате крайните резултати за по-късен анализ.
Други тестове
В допълнение към копирането на данните в вече съществуващия разделен клъстериран индекс на columnstore, използвайки афинитет, исках да опитам и няколко други неща:
- Копиране на данните в новата таблица, без да се опитвате да контролирате афинитета. Извадих логиката на афинитета от процедурата и просто оставих на случайността цялата работа с „надявам се да получите правилния плановик“. Това отне повече време, защото, разбира се, подреждането на планировщика направи възникне. Например, в този конкретен момент планировчик 3 изпълняваше два процеса, докато планировчик 0 беше в почивка за обяд:
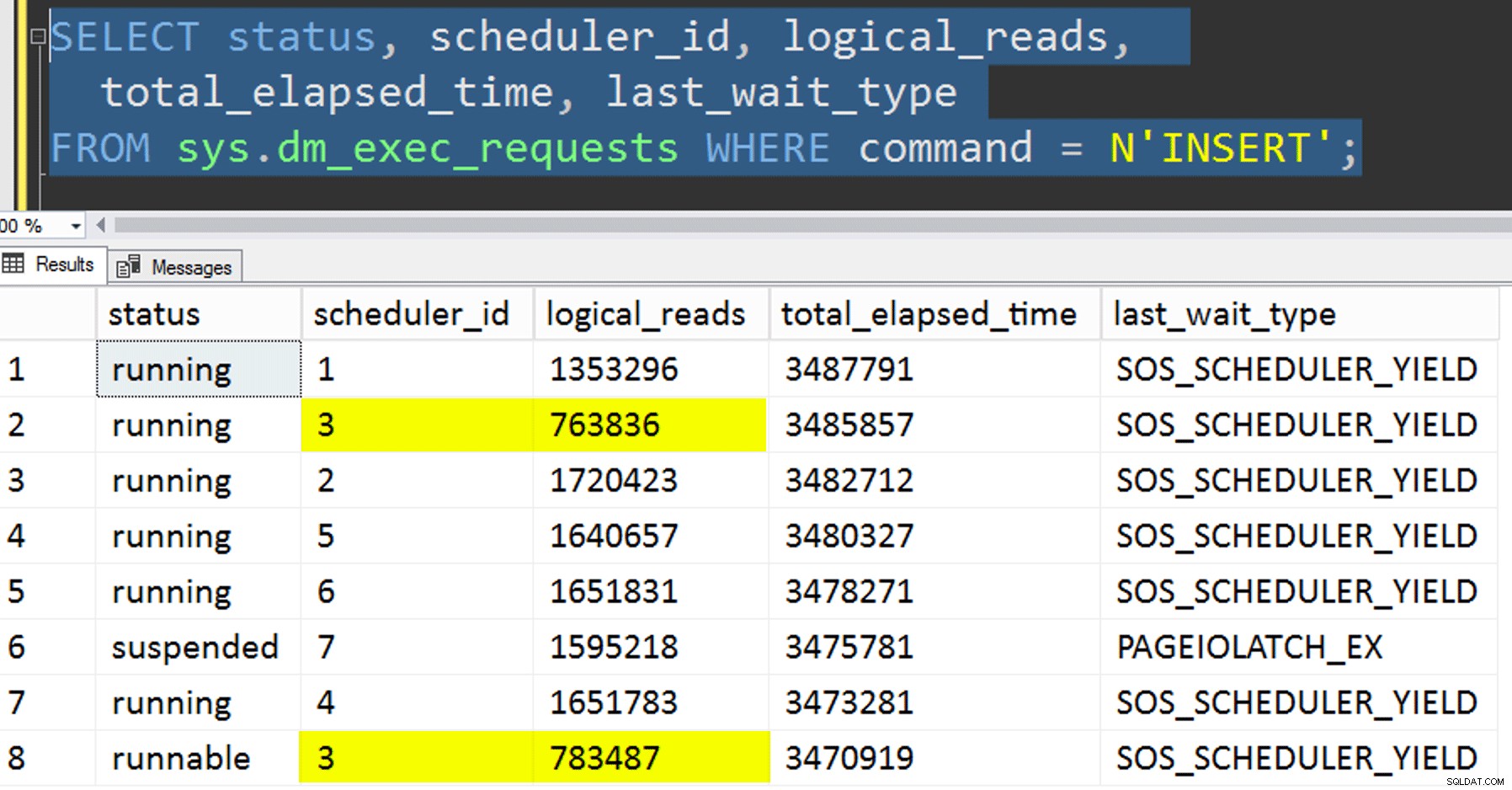 Къде си ти, планировчик номер 0?
Къде си ти, планировчик номер 0? - Прилагане на страница или ред компресиране (както онлайн, така и офлайн) до източника преди афинитизираното копие (офлайн), за да видите дали компресирането на данните първо може да ускори дестинацията. Имайте предвид, че копието може да бъде направено и онлайн, но като
intна Анди Малън къмbigintпреобразуването изисква известна гимнастика. Имайте предвид, че в този случай не можем да се възползваме от афинитета на процесора (въпреки че бихме могли, ако изходната таблица вече е разделена). Бях умен и направих резервно копие на оригиналния източник и създадох процедура за връщане на базата данни обратно в първоначалното й състояние. Много по-бързо и по-лесно, отколкото да се опитвате да се върнете към определено състояние ръчно.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- И накрая, първо изграждане на клъстерирания индекс върху схемата на дялове, след което изграждане на клъстерирания индекс на columnstore върху това. Недостатъкът на последното е, че в SQL Server 2017 не можете да стартирате това онлайн... но ще можете през 2019 г.
Тук първо трябва да премахнем ограничението PK; не можете да използвате
Съобщение 1907, ниво 16, състояние 1DROP_EXISTING, тъй като оригиналното уникално ограничение не може да бъде наложено от клъстерирания индекс на columnstore и не можете да замените уникален клъстериран индекс с неуникален клъстериран индекс.
Не може да се пресъздаде индекс 'pk_tblOriginal'. Новата дефиниция на индекс не съвпада с ограничението, което се налага от съществуващия индекс.Всички тези подробности правят този процес в три стъпки, само втората стъпка онлайн. Първата стъпка, която тествах изрично само
OFFLINE; който се изпълнява за три минути, докатоONLINEСпрях след 15 минути. Едно от онези неща, които може би не трябва да са операция за размер на данни и в двата случая, но ще оставя това за друг ден.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Резултати
Времетраене и степен на компресия:
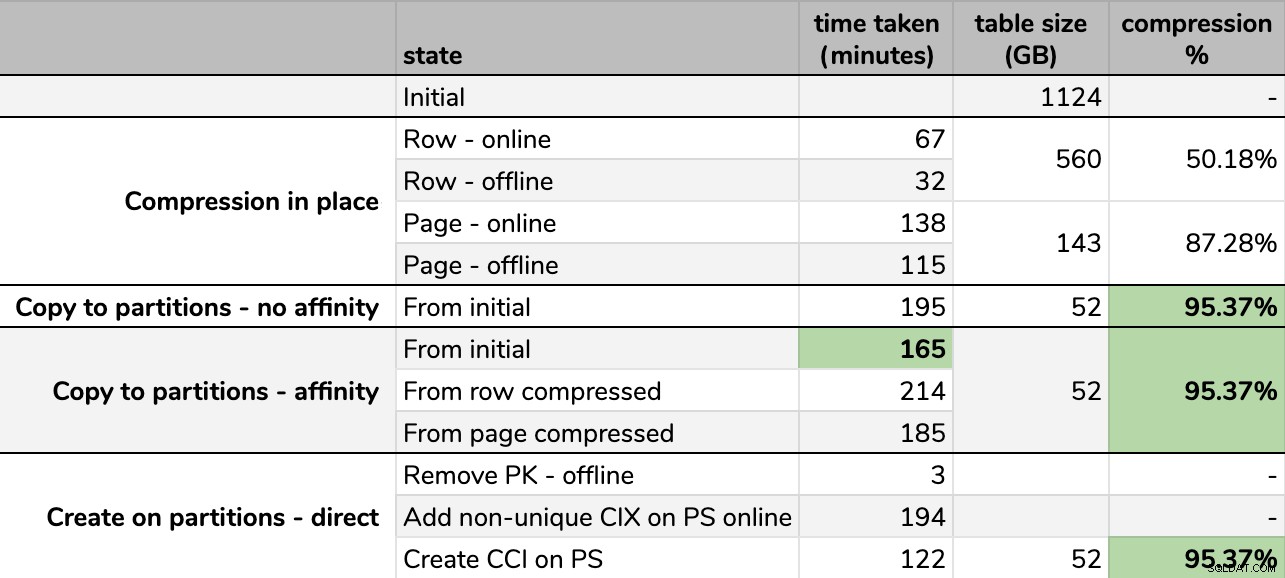 Някои опции са по-добри от други
Някои опции са по-добри от други
Имайте предвид, че закръглих до GB, защото ще има малки разлики в крайния размер след всяко изпълнение, дори при използване на същата техника. Също така, времето за методите за афинитет се основава на средното индивидуален планировчик/пакетно време за изпълнение, тъй като някои планировчици завършват по-бързо от други.
Трудно е да си представим точна картина от електронната таблица, както е показано, тъй като някои задачи имат зависимости, така че ще се опитам да покажа информацията като времева линия и да покажа колко компресия получавате в сравнение с прекараното време:
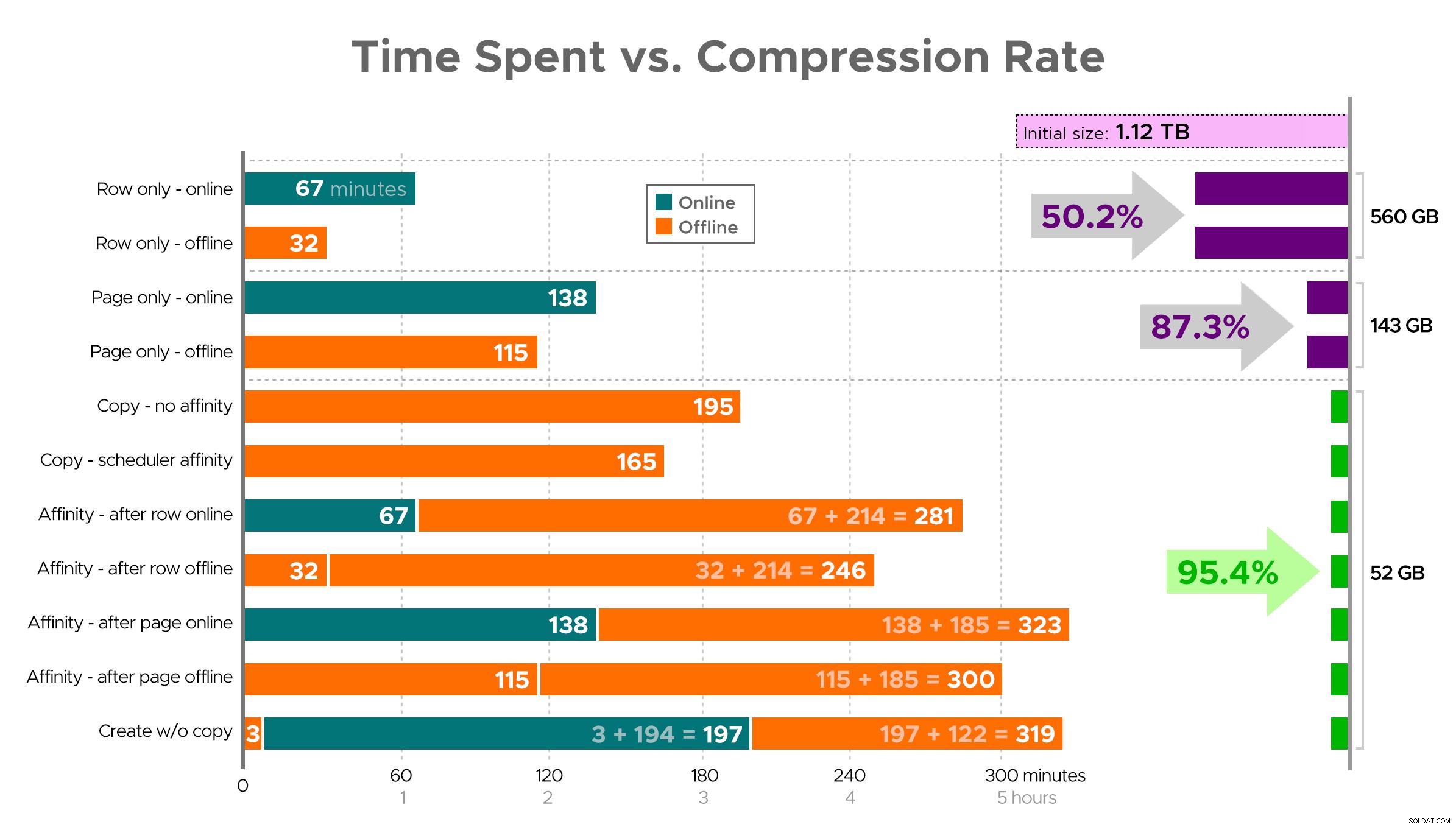 Прекарано време (минути) спрямо степента на компресия
Прекарано време (минути) спрямо степента на компресия
Няколко наблюдения от резултатите, с уговорката, че вашите данни може да се компресират по различен начин (и че онлайн операциите се отнасят само за вас, ако използвате Enterprise Edition):
- Ако вашият приоритет е да спестите малко място възможно най-бързо , най-добрият ви залог е да приложите компресия на ред на място. Ако искате да сведете до минимум прекъсването, използвайте онлайн; ако искате да оптимизирате скоростта, използвайте офлайн.
- Ако искате да максимизирате компресията с нулеви смущения , можете да достигнете до 90% намаляване на съхранението без никакво прекъсване, като използвате компресиране на страници онлайн.
- Ако искате да максимизирате компресията и прекъсването е добре , копирайте данните в нова, разделена версия на таблицата с клъстериран индекс на columnstore и използвайте процеса на афинитет, описан по-горе, за да мигрирате данните. (И отново, можете да премахнете това прекъсване, ако сте по-добър плановик от мен.)
Последният вариант работеше най-добре за моя сценарий, въпреки че все пак ще трябва да свалим гумите за работните натоварвания (да, множествено число). Също така имайте предвид, че в SQL Server 2019 тази техника може да не работи толкова добре, но можете да създавате клъстерни индекси на columnstore онлайн там, така че може да няма толкова голямо значение.
Някои от тези подходи може да са повече или по-малко приемливи за вас, защото може да предпочитате „да останете на разположение“ пред „приключването възможно най-бързо“ или „минимизиране на използването на диска“ пред „да останете на разположение“ или просто да балансирате производителността при четене и запис. .
Ако искате повече подробности относно някой аспект от това, просто попитайте. Отрязах част от мазнините, за да балансирам детайлите със смилаемостта и преди съм грешил за този баланс. Прощалната мисъл е, че ми е любопитно колко линейно е това – имаме друга маса с подобна структура, която е над 25 TB, и съм любопитен дали можем да окажем подобно въздействие там. Дотогава приятно компресиране!
[ Част 1 | Част 2 | Част 3 ]