В няколко от публикациите си през последната година използвах темата за хората, които виждат определен тип изчакване и след това реагират по „колене“ начин на чакането, което е там. Обикновено това означава да следвате някои лоши интернет съвети и да предприемете драстични, неподходящи действия или да направите прибързано заключение каква е основната причина за проблема и след това да загубите време и усилия в преследване на дива гъска.
Един от видовете чакане, при които реакциите на коляното са най-силни и където съществуват някои от най-лошите съвети, е изчакването на CXPACKET. Това е и типът на чакане, който най-често е най-голямото изчакване на сървърите на хората (според моите две големи проучвания за типа чакане от 2010 и 2014 г. – вижте тук за подробности), така че ще го покрия в тази публикация.
Какво означава типът на чакане CXPACKET?
Най-простото обяснение е, че CXPACKET означава, че заявките се изпълняват паралелно и вие *винаги* ще виждате, че CXPACKET чака паралелна заявка. Изчакването на CXPACKET НЕ означава, че имате проблемен паралелизъм – трябва да копаете по-дълбоко, за да определите това.
Като пример за паралелен оператор, разгледайте оператора Repartition Streams, който има следната икона в графичните планове за заявка:

И ето снимка, която показва какво се случва по отношение на паралелни нишки за този оператор, със степен на паралелизъм (DOP), равна на 4:
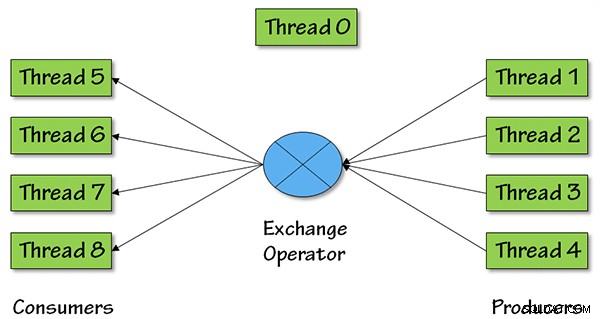
За DOP =4 ще има четири нишки производители, извличащи данни от по-рано в плана на заявката, след което данните се връщат обратно към останалата част от плана на заявката през четири потребителски нишки.
Можете да видите различните нишки в паралелен оператор, които чакат ресурс, като използвате sys.dm_os_waiting_tasks DMV, в exec_context_id колона (тази публикация има моя скрипт за това).
Винаги има „контролна“ нишка за всеки паралелен план, който по исторически случай винаги е идентификатор на нишка 0. Контролната нишка винаги регистрира CXPACKET чакане, с продължителност, равна на продължителността на времето, необходимо за изпълнение на плана. Пол Уайт има страхотно обяснение за нишките в паралелни планове тук.
Единственият път, когато неконтролиращите нишки ще регистрират изчакване на CXPACKET, е ако завършат преди другите нишки в оператора. Това може да се случи, ако една от нишките заседне в изчакване на ресурс за дълго време, така че вижте какъв е типът на изчакване на нишката, която не показва CXPACKET (използвайки моя скрипт по-горе) и отстранете по подходящ начин. Това може да се случи и поради изкривено разпределение на работата между нишките и ще се впусна по-задълбочено в този случай в следващата си публикация тук (причинено е от остарели статистически данни и други проблеми с оценката на мощността).
Имайте предвид, че в SQL Server 2016 SP2 и SQL Server 2017 RTM CU3 потребителските нишки вече не регистрират CXPACKET чакания. Те регистрират CXCONSUMER чакания, които са доброкачествени и могат да бъдат игнорирани. Това е да се намали броят на генерираните изчаквания на CXPACKET и е по-вероятно останалите да бъдат изпълними.
Неочакван паралелизъм?
Като се има предвид, че CXPACKET просто означава, че имате паралелизъм, първото нещо, което трябва да погледнете, е дали очаквате паралелизъм за заявката, която го използва. Моята заявка ще ви даде идентификатора на възела на плана на заявката, където се случва паралелизмът (извлича идентификатора на възела от XML плана на заявката, ако типът на изчакване на нишката е CXPACKET), така че потърсете този идентификационен номер на възел и определете дали паралелизмът има смисъл .
Един от често срещаните случаи на неочакван паралелизъм е, когато сканиране на таблица се случва, когато очаквате по-малко търсене или сканиране на индекс. Или ще видите това в плана на заявката, или ще видите много PAGEIOLATCH_SH изчаквания (обсъдени подробно тук) заедно с изчакванията CXPACKET (класически модел на статистически данни за чакане, за който да търсите). Има различни причини за неочаквано сканиране на таблицата, включително:
- Липсващ неклъстериран индекс, така че сканирането на таблица е единствената алтернатива
- Неактуални статистически данни, така че оптимизаторът на заявки смята, че сканирането на таблица е най-добрият метод за достъп до данни, който да се използва
- Неявно преобразуване поради несъответствие на типа данни между колона на таблица и променлива или параметър, което означава, че неклъстеризиран индекс не може да се използва
- Аритметика се извършва върху колона на таблица вместо променлива или параметър, което означава, че не може да се използва неклъстериран индекс
Във всички тези случаи решението е продиктувано от това какво смятате за основната причина.
Но какво, ако няма очевиден основен случай и заявката просто се счита за достатъчно скъпа, за да гарантира паралелен план?
Предотвратяване на паралелизъм
Наред с други неща, оптимизаторът на заявки решава да създаде паралелен план за заявка, ако серийният план има по-висока цена от cost threshold for parallelism , настройка на sp_configure за екземпляра. Прагът на разходите за паралелизъм (или CTFP) е зададен на пет по подразбиране, което означава, че планът не трябва да е много скъп, за да задейства създаването на паралелен план.
Един от най-лесните начини за предотвратяване на нежелан паралелизъм е да увеличите CTFP до много по-голямо число, като колкото по-високо го зададете, толкова по-малко вероятно ще бъдат създадени паралелни планове. Някои хора се застъпват за задаване на CTFP на някъде между 25 и 50, но както при всички настройки, които могат да се настройват, най-добре е да тествате различни стойности и да видите кое работи най-добре за вашата среда. Ако искате малко повече от програмен метод, който да ви помогне да изберете добра стойност на CTFP, Джонатан написа публикация в блог, показваща заявка за анализ на кеша на плана и генериране на предложена стойност за CTFP. Като примери имаме един клиент с CTFP, зададен на 200, а друг настроен на максимум – 32767 – като начин за принудително предотвратяване на какъвто и да е паралелизъм.
Може да се чудите защо вторият клиент трябваше да използва CTFP като метод на чук за предотвратяване на паралелизъм, когато смятате, че може просто да зададе на сървъра „максимална степен на паралелизъм“ (или MAXDOP) на 1. Е, всеки с някакво ниво на разрешение може посочете намек за заявка MAXDOP и заменете настройката MAXDOP на сървъра, но CTFP не може да бъде отменен.
И това е друг метод за ограничаване на паралелизма – задаване на MAXDOP намек за заявката, която не искате да вървите паралелно.
Можете също да намалите настройката MAXDOP на сървъра, но това е драстично решение, тъй като може да попречи на всичко да използва паралелизъм. В днешно време е обичайно сървърите да имат смесени натоварвания, например с някои OLTP заявки и някои заявки за отчитане. Ако намалите MAXDOP на сървъра, ще намалите производителността на заявките за отчитане.
По-добро решение, когато има смесено работно натоварване, би било да се използва CTFP, както описах по-горе, или да се използва Resource Governor (което се опасявам, че е само за предприятия). Можете да използвате Resource Governor, за да разделите натоварванията в групи натоварвания и след това да зададете MAX_DOP (долната черта не е печатна грешка) за всяка група натоварвания. И хубавото при използването на Resource Governor е, че MAX_DOP не може да бъде отменен от намек за заявка MAXDOP.
Резюме
Не попадайте в капана да си мислите, че CXPACKET изчаква автоматично означава, че имате лош паралелизъм и със сигурност не следвайте някои от съветите в Интернет, които съм виждал, за запушване на сървъра, като зададете MAXDOP на 1. Отделете време за да проучите защо виждате, че CXPACKET чака и дали това е нещо, което трябва да бъде адресирано, или просто артефакт на работно натоварване, което работи правилно.
Що се отнася до общата статистика за чакане, можете да намерите повече информация за използването им за отстраняване на неизправности в производителността в:
- Моята серия от публикации в блога на SQLskills, започваща със статистически данни за чакане или моля, кажете ми къде боли
- Моята библиотека за типове чакане и класове на заключване тук
- Моят онлайн курс за обучение на Pluralsight SQL Server:Отстраняване на проблеми с производителността с помощта на статистика за чакане
- Съветник за производителност на SQL Sentry
В следващата статия от поредицата ще обсъдя изкривения паралелизъм и ще ви дам прост начин да го видите как се случва. Дотогава, щастливо отстраняване на неизправности!