Параметрите с таблично значение съществуват от SQL Server 2008 и осигуряват полезен механизъм за изпращане на множество редове данни към SQL Server, събрани като едно параметризирано извикване. След това всички редове са налични в таблична променлива, която след това може да се използва в стандартното T-SQL кодиране, което елиминира необходимостта от писане на специализирана логика за обработка за повторно разбиване на данните. По самата им дефиниция параметрите с стойност на таблицата са строго типизирани към дефиниран от потребителя тип таблица, която трябва да съществува в базата данни, където се извършва извикването. Въпреки това, строго въведеното всъщност не е строго „строго въведено“, както бихте очаквали, както тази статия ще демонстрира, и в резултат на това производителността може да бъде засегната.
За да демонстрираме потенциалните въздействия върху производителността на неправилно въведени параметри с стойност на таблица със SQL Server, ще създадем примерен тип таблица, дефиниран от потребителя, със следната структура:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Тогава ще ни трябва .NET приложение, което ще използва този дефиниран от потребителя тип таблица като входен параметър за предаване на данни в SQL Server. За да се използва параметър със стойност на таблица от нашето приложение, обект DataTable обикновено се попълва и след това се предава като стойност за параметъра с тип SqlDbType.Structured. DataTable може да бъде създадена по няколко начина в .NET кода, но често срещаният начин за създаване на таблицата е нещо като следното:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Можете също да създадете DataTable, като използвате вградената дефиниция, както следва:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Всяко от тези дефиниции на обекта DataTable в .NET може да се използва като параметър с стойност на таблицата за дефинирания от потребителя тип данни, който е създаден, но обърнете внимание на дефиницията typeof(string) за различните колони низ; всички те може да са „правилно“ въведени, но всъщност не са строго въведени за типовете данни, внедрени в дефинирания от потребителя тип данни. Можем да попълним таблицата с произволни данни и да я предадем на SQL Server като параметър на много прост оператор SELECT, който ще върне обратно точно същите редове като таблицата, която сме предали, както следва:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} След това можем да използваме прекъсване за отстраняване на грешки, за да можем да проверим дефиницията на DefaultTable по време на изпълнение, както е показано по-долу:
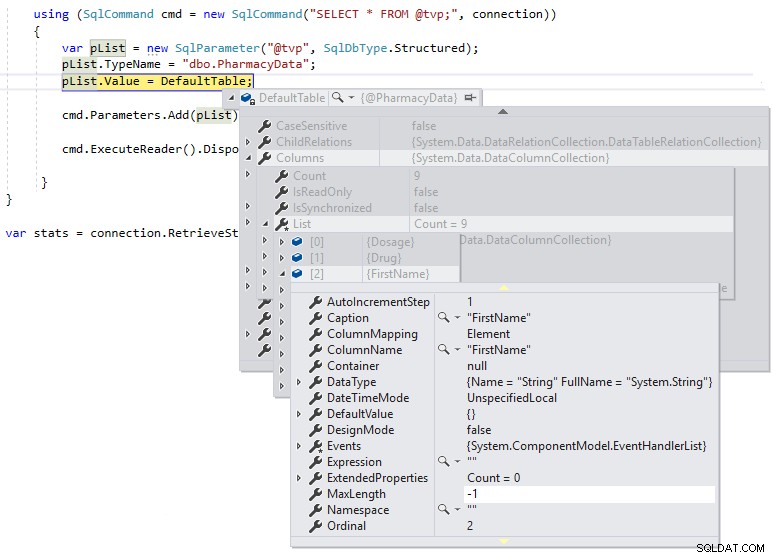
Можем да видим, че MaxLength за колоните с низове е зададено на -1, което означава, че те се предават през TDS към SQL Server като LOB (големи обекти) или по същество като MAX колони с тип данни и това може да повлияе на производителността по отрицателен начин. Ако променим дефиницията на .NET DataTable да бъде строго въведена към дефиницията на схемата на дефинирания от потребителя тип таблица, както следва и погледнем MaxLength на същата колона, използвайки прекъсване за отстраняване на грешки:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
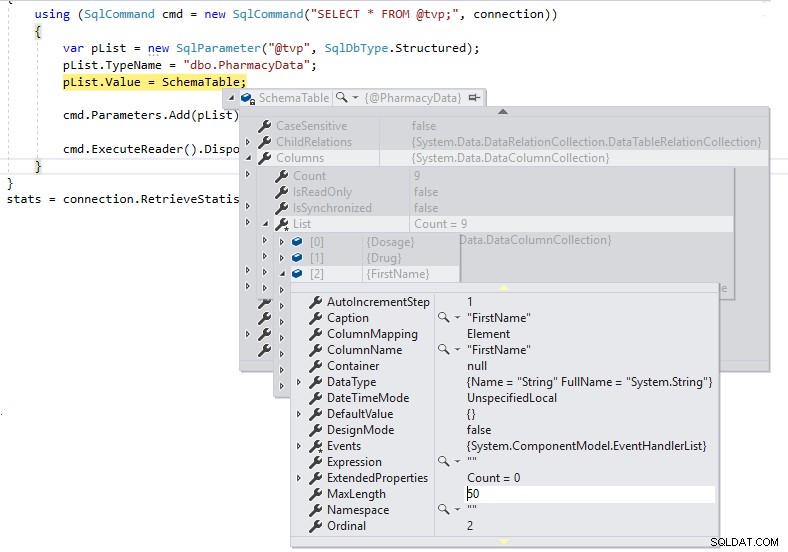
Вече имаме правилни дължини за дефинициите на колоните и няма да ги предаваме като LOB през TDS на SQL Server.
Как това се отразява на производителността, може да се чудите? Това влияе върху броя на TDS буферите, които се изпращат в мрежата към SQL Server, и също така влияе върху общото време за обработка на командите.
Използването на точно същия набор от данни за двете таблици с данни и използването на метода RetrieveStatistics върху обекта SqlConnection ни позволява да получим статистическите показатели за ExecutionTime и BuffersSent за извикванията към една и съща команда SELECT и просто използвайки двете различни дефиниции на DataTable като параметри и извикването на метода ResetStatistics на обекта SqlConnection позволява статистическите данни за изпълнение да бъдат изчистени между тестовете.
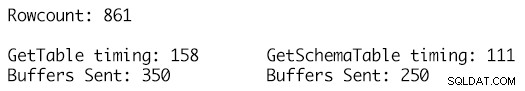
Дефиницията на GetSchemaTable определя правилно MaxLength за всяка от колоните на низовете, където GetTable просто добавя колони от тип string, които имат стойност MaxLength, зададена на -1, което води до изпращане на 100 допълнителни TDS буфера за 861 реда данни в таблицата и време на изпълнение на 158 милисекунди в сравнение със само 250 буфера, изпратени за строго въведената дефиниция на DataTable и време за изпълнение от 111 милисекунди. Макар че това може да не изглежда много в голямата схема на нещата, това е едно извикване, еднократно изпълнение и натрупаното въздействие с течение на времето за много хиляди или милиони такива екзекуции е мястото, където ползите започват да се събират и имат забележимо въздействие за производителността и производителността на работното натоварване.
Това, където това наистина може да направи разлика, е в облачните реализации, където плащате за повече от просто ресурси за изчисление и съхранение. В допълнение към фиксираните разходи за хардуерни ресурси за Azure VM, SQL база данни или AWS EC2 или RDS, има добавена цена за мрежов трафик към и от облака, която се свързва с таксуването за всеки месец. Намаляването на буферите, преминаващи през проводника, ще намали TCO за решението с течение на времето, а промените в кода, необходими за реализиране на тези спестявания, са сравнително прости.