[ Част 1 | Част 2 | Част 3 | Част 4 ]
През годините беше писано много за разбирането и оптимизирането на SELECT запитвания, но по-малко за промяна на данни. Тази серия от публикации разглежда проблем, който е специфичен за INSERT , UPDATE , DELETE и MERGE запитвания – проблемът за Хелоуин.
Фразата „Проблем с Хелоуин“ първоначално е измислена във връзка с SQL UPDATE заявка, която трябваше да даде 10% увеличение на всеки служител, който е спечелил по-малко от $25 000. Проблемът беше, че заявката продължаваше да дава 10% повишения до всички спечелил най-малко $25,000. Ще видим по-нататък в тази серия, че основният проблем се отнася и за INSERT , DELETE и MERGE заявки, но за този първи запис ще бъде полезно да разгледате UPDATE проблема в малко подробности.
Фон
Езикът SQL предоставя начин на потребителите да задават промени в базата данни с помощта на UPDATE изявление, но синтаксисът не казва нищо за как двигателят на базата данни трябва да извърши промените. От друга страна, стандартът на SQL определя, че резултатът от UPDATE трябва да бъде същото, сякаш беше изпълнено в три отделни и неприпокриващи се фази:
- Търсенето само за четене определя записите, които трябва да бъдат променени, и стойностите на новите колони
- Промените се прилагат към засегнатите записи
- Ограниченията за последователност на базата данни са проверени
Прилагането на тези три фази буквално в машина за база данни ще даде правилни резултати, но производителността може да не е много добра. Междинните резултати на всеки етап ще изискват системна памет, намалявайки броя на заявките, които системата може да изпълнява едновременно. Необходимата памет може също да надхвърли тази, която е налична, което изисква поне част от комплекта за актуализации да бъде записана на дисково съхранение и прочетена отново по-късно. Не на последно място, всеки ред в таблицата трябва да бъде докоснат няколко пъти при този модел на изпълнение.
Алтернативна стратегия е да се обработи UPDATE ред по ред. Това има предимството да докосва всеки ред само веднъж и обикновено не изисква памет за съхранение (въпреки че някои операции, като пълно сортиране, трябва да обработят пълния входен набор, преди да произведат първия изходен ред). Този итеративен модел е този, използван от машината за изпълнение на заявки на SQL Server.
Предизвикателството за оптимизатора на заявки е да намери итеративен (ред по ред) план за изпълнение, който отговаря на UPDATE семантика, изисквана от стандарта SQL, като същевременно се запазват предимствата на производителността и паралелността на конвейерното изпълнение.
Обработка на актуализация
За да илюстрираме първоначалния проблем, ще приложим увеличение от 10% за всеки служител, който печели по-малко от $25 000, използвайки Employees таблица по-долу:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Трифазна стратегия за актуализиране
Първата фаза само за четене намира всички записи, които отговарят на WHERE предикат на клауза и запазва достатъчно информация, за да може втората фаза да свърши своята работа. На практика това означава запис на уникален идентификатор за всеки квалифициращ ред (клъстерираните индексни ключове или идентификатор на ред на купчина) и новата стойност на заплатата. След като първата фаза приключи, целият набор от информация за актуализиране се предава на втората фаза, която намира всеки запис, който трябва да бъде актуализиран, използвайки уникалния идентификатор, и променя заплатата на новата стойност. След това третата фаза проверява дали не са нарушени ограничения за целостта на базата данни от крайното състояние на таблицата.
Итеративна стратегия
Този подход чете един ред в даден момент от таблицата източник. Ако редът отговаря на WHERE клауза предикат, се прилага увеличението на заплатата. Този процес се повтаря, докато всички редове не бъдат обработени от източника. Примерен план за изпълнение, използващ този модел, е показан по-долу:

Както е обичайно за управлявания от търсенето конвейер на SQL Server, изпълнението започва от най-левия оператор – UPDATE в такъв случай. Той изисква ред от актуализацията на таблицата, която иска ред от скалара за изчисляване и надолу по веригата до сканирането на таблицата:
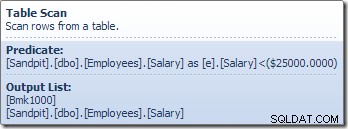
Операторът Table Scan чете редове един по един от механизма за съхранение, докато не намери такъв, който удовлетворява предиката Заплата. Изходният списък в графиката по-горе показва оператора за сканиране на таблици, връщащ идентификатор на ред и текущата стойност на колоната Заплата за този ред. Един ред, съдържащ препратки към тези две части от информация, се предава на изчислителния скалар:
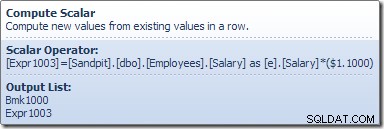
Скаларът за изчисляване дефинира израз, който прилага увеличението на заплатата към текущия ред. Той връща ред, съдържащ препратки към идентификатора на реда и модифицираната заплата към актуализацията на таблицата, която извиква механизма за съхранение, за да извърши модификацията на данните. Този итерационен процес продължава, докато при сканирането на таблицата не изчерпят редовете. Същият основен процес се следва, ако таблицата има клъстериран индекс:
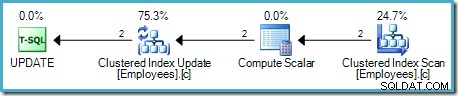
Основната разлика е, че ключът(ите) на клъстерния индекс и унификаторът (ако има такъв) се използват като идентификатор на ред вместо RID на купчина.
Проблемът
Преминаването от логическата трифазна операция, дефинирана в стандарта SQL, към модела на физическо итеративно изпълнение въведе редица фини промени, само една от които ще разгледаме днес. В нашия пример може да възникне проблем, ако има неклъстериран индекс в колоната Заплата, който оптимизаторът на заявки решава да използва, за да намери редове, които отговарят на изискванията (Заплата <$25 000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Моделът за изпълнение ред по ред вече може да даде неправилни резултати или дори да влезе в безкраен цикъл. Помислете за (въображаем) итеративен план за изпълнение, който търси индекса на заплатата, връщайки ред по ред към скалара за изчисляване и в крайна сметка към оператора за актуализиране:

В този план има няколко допълнителни изчислителни скалари поради оптимизация, която пропуска поддръжката на неклъстерни индекси, ако стойността на заплатата не се е променила (възможно е само за нулева заплата в този случай).
Пренебрегвайки това, важната характеристика на този план е, че сега имаме подредено частично сканиране на индекс, което предава ред по ред на оператор, който променя същия индекс (зеленото осветяване в графиката на SQL Sentry Plan Explorer по-горе прави ясно, че Clustered Операторът за актуализиране на индекса поддържа както основната таблица, така и неклъстерирания индекс).
Както и да е, проблемът е, че чрез обработване на един ред наведнъж, актуализацията може да премести текущия ред пред позицията на сканиране, използвана от Index Seek, за да намери редове за промяна. Работата по примера трябва да направи това твърдение малко по-ясно:
Неклъстерираният индекс е ключов и сортиран възходящо по стойността на заплатата. Индексът също така съдържа указател към родителския ред в базовата таблица (или RID на купчина, или клъстерираните индексни ключове плюс унификатор, ако е необходимо). За да направите примера по-лесен за следване, приемете, че базовата таблица вече има уникален клъстериран индекс в колоната Име, така че съдържанието на неклъстерирания индекс в началото на обработката на актуализацията е:
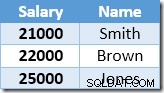
Първият ред, върнат от Index Seek, е заплатата от $21 000 за Смит. Тази стойност се актуализира до $23,100 в основната таблица и неклъстерирания индекс от оператора Clustered Index. Неклъстерираният индекс вече съдържа:
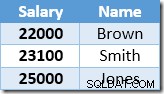
Следващият ред, върнат от Index Seek, ще бъде записът от $22,000 за Brown, който се актуализира на $24,200:
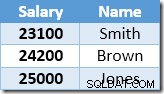
Сега Index Seek намира стойността от $23 100 за Smith, която се актуализира отново , до $25 410. Този процес продължава, докато всички служители имат заплата от най-малко $25 000 – което не е правилен резултат за дадената UPDATE запитване. Същият ефект при други обстоятелства може да доведе до спешна актуализация, която се прекратява само когато на сървъра свърши регистрационното пространство или възникне грешка при препълване (това може да възникне в този случай, ако някой е имал нулева заплата). Това е проблемът на Хелоуин, тъй като се отнася за актуализациите.
Избягване на проблема с Хелоуин за актуализации
Читателите с орлови очи ще забележат, че прогнозните проценти на разходите във въображаемия план за търсене на индекси не са 100%. Това не е проблем с Plan Explorer – нарочно премахнах ключов оператор от плана:

Оптимизаторът на заявки разпознава, че този план за обновяване по конвейер е уязвим към проблема за Хелоуин и въвежда Eager Table Spool, за да предотврати възникването му. Няма намек или флаг за проследяване, който да предотврати включването на макарата в този план за изпълнение, тъй като се изисква за коректност.
Както подсказва името му, пулта с нетърпение консумира всички редове от своя дъщерен оператор (Index Seek), преди да върне ред на своя родител Compute Scalar. Ефектът от това е да се въведе пълно фазово разделяне – всички отговарящи на условията редове се четат и записват във временно хранилище, преди да се извършат каквито и да било актуализации.
Това ни доближава до трифазната логическа семантика на SQL стандарта, въпреки че, моля, имайте предвид, че изпълнението на плана все още е основно итеративно, като операторите вдясно от пулта образуват курсора за четене и оператори вляво, образуващи курсора за запис . Съдържанието на макарата все още се чете и обработва ред по ред (не се предава масово тъй като сравнението със стандарта SQL иначе може да ви накара да повярвате).
Недостатъците на фазовото разделяне са същите, както споменахме по-рано. Table Spool консумира tempdb пространство (страници в буферния пул) и може да изисква физическо четене и запис на диск при натиск в паметта. Оптимизаторът на заявки присвоява прогнозна цена на пулта (при спазване на всички обичайни предупреждения относно приблизителните оценки) и ще избира между планове, които изискват защита срещу проблема на Хелоуин, спрямо тези, които не го правят въз основа на приблизителната цена, както обикновено. Естествено, оптимизаторът може неправилно да избере между опциите по някоя от нормалните причини.
В този случай компромисът е между повишаването на ефективността чрез директно търсене на квалифицирани записи (тези със заплата <$25 000) спрямо прогнозната цена на макарата, необходима за избягване на проблема с Хелоуин. Алтернативен план (в този конкретен случай) е пълно сканиране на клъстерирания индекс (или купчина). Тази стратегия не изисква същата защита за Хелоуин, тъй като ключовете на клъстерирания индекс не са променени:

Тъй като индексните ключове са стабилни, редовете не могат да преместват позицията в индекса между итерациите, избягвайки проблема с Хелоуин в настоящия случай. В зависимост от разходите по време на изпълнение на Clustered Index Scan в сравнение с комбинацията Index Seek плюс Eager Table Spool, видяна по-рано, един план може да се изпълни по-бързо от другия. Друго съображение е, че планът със защита за Хелоуин ще придобие повече ключалки от напълно изготвения план и ключалките ще се задържат по-дълго.
Последни мисли
Разбирането на проблема с Хелоуин и ефектите, които той може да има върху плановете за заявка за промяна на данни, ще ви помогне да анализирате плановете за изпълнение за промяна на данните и може да предложи възможности за избягване на разходите и страничните ефекти от ненужна защита, когато е налична алтернатива.
Има няколко форми на проблема за Хелоуин, не всички от които са причинени от четене и писане на ключовете на общ индекс. Проблемът с Хелоуин също не се ограничава до UPDATE запитвания. Оптимизаторът на заявки има още трикове в ръкава си, за да избегне проблема с Хелоуин, освен разделянето на фазите с груба сила с помощта на Eager Table Spool. Тези точки (и повече) ще бъдат разгледани в следващите части от тази серия.
[ Част 1 | Част 2 | Част 3 | Част 4 ]