Тази статия е третата част от поредицата за NULL сложности. В част 1 разгледах значението на NULL маркера и как се държи при сравнения. В част 2 описах несъответствията в третирането с NULL в различни езикови елементи. Този месец описвам мощни стандартни функции за работа с NULL, които все още не са стигнали до T-SQL, и заобикалящите я решения, които хората използват в момента.
Ще продължа да използвам примерната база данни TSQLV5, както миналия месец в някои от моите примери. Тук можете да намерите скрипта, който създава и попълва тази база данни, както и нейната диаграма за ER тук.
DISTINCT предикат
В част 1 от поредицата обясних как се държат NULL при сравнения и сложността около тризначната предикатна логика, която използват SQL и T-SQL. Помислете за следния предикат:
X =YАко някой предиканд е NULL — включително когато и двата са NULL — резултатът от този предикат е логическата стойност UNKNOWN. С изключение на операторите IS NULL и IS NOT NULL, същото важи и за всички други оператори, включително различни от (<>):
X <> YЧесто на практика искате NULL да се държат точно като стойности, различни от NULL за целите на сравнението. Това е особено в случая, когато ги използвате за представяне на липсващи, но неприложими стойности. Стандартът има решение за тази нужда под формата на характеристика, наречена предикат DISTINCT, която използва следната форма:
Вместо да използва семантика на равенство или неравенство, този предикат използва семантика, базирана на отличителност, когато сравнява предиканди. Като алтернатива на оператор за равенство (=), бихте използвали следния формуляр, за да получите TRUE, когато двата предиканда са еднакви, включително когато и двата са NULL, и FALSE, когато не са, включително когато единият е NULL и другото не е:
X НЕ СЕ РАЗЛИЧИ ОТ YКато алтернатива на различно от оператор (<>), ще използвате следния формуляр, за да получите TRUE, когато двата предиканда са различни, включително когато единият е NULL, а другият не е, и FALSE, когато са еднакви, включително когато и двата са NULL:
X СЕ РАЗЛИЧИ ОТ YНека приложим предиката DISTINCT към примерите, които използвахме в част 1 от поредицата. Припомнете си, че трябва да напишете заявка, която дава входен параметър @dt връща поръчки, които са били изпратени на датата на въвеждане, ако не е NULL, или които изобщо не са били изпратени, ако входът е NULL. Съгласно стандарта ще използвате следния код с предиката DISTINCT, за да се справите с тази нужда:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate НЕ СЕ РАЗЛИЧИ ОТ @dt;
Засега си припомнете от част 1, че можете да използвате комбинация от предиката EXISTS и оператора INTERSECT като SARGable заобиколно решение в T-SQL, както следва:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
За да върнете поръчки, които са били изпратени на дата, различна от (различна от) въведената дата @dt, ще използвате следната заявка:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate Е РАЗЛИЧНА ОТ @dt;
Заобикалянето, което работи в T-SQL, използва комбинация от предиката EXISTS и оператора EXCEPT, както следва:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE EXISTS(ИЗБЕРЕТЕ shippeddate EXCEPT SELECT @dt);
В част 1 също обсъдих сценарии, при които трябва да обедините таблици и да приложите базирана на отличителност семантика в предиката за присъединяване. В моите примери използвах таблици, наречени T1 и T2, с NULL колони за свързване, наречени k1, k2 и k3 от двете страни. Съгласно стандарта, вие бихте използвали следния код за обработка на такова присъединяване:
ИЗБЕРЕТЕ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1INNER JOIN dbo.T2 НА T1.k1 НЕ СЕ РАЗЛИЧИ ОТ T2.k1 И T1.k2 НЕ СЕ РАЗЛИЧИ ОТ T2 .k2 И T1.k3 НЕ СЕ РАЗЛИЧИ ОТ T2.k3;
Засега, подобно на предишните задачи за филтриране, можете да използвате комбинация от предиката EXISTS и оператора INTERSECT в клаузата ON на съединението, за да емулирате отделния предикат в T-SQL, както следва:
ИЗБЕРЕТЕ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1 , T2.k2, T2.k3);
Когато се използва във филтър, тази форма е SARGable, а когато се използва в обединения, тази форма може потенциално да разчита на реда на индексите.
Ако искате да видите предиката DISTINCT, добавен към T-SQL, можете да гласувате за него тук.
Ако след като прочетете този раздел, все още се чувствате малко неспокойни относно предиката DISTINCT, не сте сами. Може би този предикат е много по-добър от всяко съществуващо решение, което в момента имаме в T-SQL, но е малко многословно и малко объркващо. Той използва отрицателна форма, за да приложи това, което в съзнанието ни е положително сравнение, и обратно. Е, никой не каза, че всички стандартни предложения са перфектни. Както Чарли отбеляза в един от коментарите си към Част 1, следната опростена форма би работила по-добре:
<предикан 1> Е [ НЕ ] <предсказуем 2>Той е сбит и много по-интуитивен. Вместо X НЕ СЕ РАЗЛИЧИ ОТ Y, бихте използвали:
X Е YИ вместо X Е РАЗЛИЧЕН ОТ Y, ще използвате:
X НЕ Е YТози предложен оператор всъщност е приведен в съответствие с вече съществуващите оператори IS NULL и IS NOT NULL.
Приложено към нашата задача за заявка, за да върнете поръчки, които са били изпратени на датата на въвеждане (или които не са били изпратени, ако входът е NULL), ще използвате следния код:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate IS @dt;
За да върнете поръчки, които са били изпратени на дата, различна от датата на въвеждане, ще използвате следния код:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersWHERE shippeddate НЕ Е @dt;
Ако Microsoft някога реши да добави отделния предикат, би било добре да поддържат както стандартната многословна форма, така и тази нестандартна, но по-сбита и по-интуитивна форма. Любопитното е, че процесорът на заявки на SQL Server вече поддържа вътрешен оператор за сравнение IS, който използва същата семантика като желания оператор IS, който описах тук. Можете да намерите подробности за този оператор в статията на Пол Уайт Недокументирани планове за заявка:Сравнения на равенство (търсете „IS вместо EQ“). Това, което липсва, е излагането му външно като част от T-SQL.
Клауза за третиране NULL (IGNORE NULL | RESPECT NULLS)
Когато използвате функциите на прозореца за изместване LAG, LEAD, FIRST_VALUE и LAST_VALUE, понякога трябва да контролирате поведението на третиране NULL. По подразбиране тези функции връщат резултата от искания израз в заявената позиция, независимо дали резултатът от израза е действителна стойност или NULL. Понякога обаче искате да продължите да се движите в съответната посока (назад за LAG и LAST_VALUE, напред за LEAD и FIRST_VALUE) и да върнете първата стойност, различна от NULL, ако е налице, и NULL в противен случай. Стандартът ви дава контрол върху това поведение с помощта на клауза за третиране NULL със следния синтаксис:
offset_function(<израз>) IGNORE_NULLS | RESPECT NULLS OVER (<спецификация на прозореца>)По подразбиране, в случай че клаузата за третиране NULL не е посочена, е опцията RESPECT NULLS, което означава връщане на всичко, което присъства в заявената позиция, дори ако е NULL. За съжаление тази клауза все още не е налична в T-SQL. Ще дам примери за стандартния синтаксис, използвайки функциите LAG и FIRST_VALUE, както и заобиколни решения, които работят в T-SQL. Можете да използвате подобни техники, ако имате нужда от такава функционалност с LEAD и LAST_VALUE.
Като примерни данни ще използвам таблица, наречена T4, която създавате и попълвате с помощта на следния код:
ПРОСТЪПНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА dbo.T4;СЪЗДАВАЙТЕ ТАБЛИЦА dbo.T4( id INT NOT NULL ОГРАНИЧЕНИЕ PK_T4 ПЪРВИЧЕН КЛЮЧ, col1 INT NULL); ВМЕСЕТЕ В dbo.T4(id, col1) СТОЙНОСТИ( 2, NULL),( 3, 10),( 5, -1),( 7, NULL),(11, NULL),(13, -12),( 17, NULL),(19, NULL),(23, 1759);
Има обща задача, включваща връщане на последното уместно стойност. NULL в col1 показва липса на промяна в стойността, докато стойност, различна от NULL, показва нова подходяща стойност. Трябва да върнете последната стойност на col1, различна от NULL, въз основа на подреждането на id. Използвайки стандартната клауза за третиране NULL, бихте се справили със задачата така:
ИЗБЕРЕТЕ идентификатор, col1,COALESCE(col1, LAG(col1) ИГНОРИРАНЕ НА НУЛИ НАД (РЕД ПО идентификатор)) КАТО lastvalFROM dbo.T4;
Ето очаквания изход от тази заявка:
id col1 lastval----------- ----------- -----------2 NULL NULL3 10 105 -1 -17 NULL - 111 NULL -113 -12 -1217 NULL -1219 NULL -1223 1759 1759
В T-SQL има заобиколно решение, но включва два слоя функции на прозореца и табличен израз.
В първата стъпка използвате функцията на прозореца MAX, за да изчислите колона, наречена grp, съдържаща максималната стойност на идентификатор досега, когато col1 не е NULL, така:
ИЗБЕРЕТЕ идентификатор, col1,MAX(СЛУЧАЙ, КОГАТО col1 НЕ Е NULL, ТОГАВА id END) НАД (ПОРЪЧАЙТЕ ПО РЕДОВЕ ИД, НЕОГРАНИЧЕНИ ПРЕДИШНИ) КАТО grpFROM dbo.T4;
Този код генерира следния изход:
id col1 grp----------- ----------- -----------2 NULL NULL3 10 35 -1 57 NULL 511 NULL 513 -12 1317 NULL 1319 NULL 1323 1759 23
Както можете да видите, уникална стойност на grp се създава всеки път, когато има промяна в стойността col1.
Във втората стъпка дефинирате CTE въз основа на заявката от първата стъпка. След това във външната заявка вие връщате максималната стойност на col1 досега във всеки дял, дефиниран от grp. Това е последната стойност на col1, различна от NULL. Ето пълния код на решението:
WITH C AS(ИЗБЕРЕТЕ идентификатор, col1, MAX(СЛУЧАЙ, КОГАТО col1 НЕ Е NULL, ТОГАВА идентификатор END) OVER(ПОРЪЧКА ПО id РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВА) КАТО grpFROM dbo.T4)SELECT id, col1,MAX(col1) OVER( РАЗДЕЛЯНЕ ПО grp ПОРЪЧКА ПО идентификатор РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИШНИ) КАТО lastvalFROM C;
Ясно е, че това е много повече код и работа, отколкото просто да кажете IGNORE_NULLS.
Друга често срещана необходимост е да се върне първата релевантна стойност. В нашия случай да предположим, че трябва да върнете първата стойност на col1, различна от NULL до момента, въз основа на подреждането на id. Използвайки стандартната клауза за третиране NULL, ще се справите със задачата с функцията FIRST_VALUE и опцията IGNORE NULLS, както следва:
ИЗБЕРЕТЕ идентификатор, col1,FIRST_VALUE(col1) ИГНОРИРАЙТЕ НУЛИ НАД (ПОРЕД ПО идентификатор, НЕОГРАНИЧЕН ПРЕДШЕСТВЕН) КАТО firstvalFROM dbo.T4;
Ето очаквания изход от тази заявка:
id col1 firstval----------- ----------- -----------2 NULL NULL3 10 105 -1 107 NULL 1011 NULL 1013 -12 1017 NULL 1019 NULL 1023 1759 10
Обходното решение в T-SQL използва техника, подобна на тази, използвана за последната стойност, различна от NULL, само че вместо подход с двоен MAX, използвате функцията FIRST_VALUE върху функцията MIN.
В първата стъпка използвате функцията на прозореца MIN, за да изчислите колона, наречена grp, която държи минималната стойност на идентификатор досега, когато col1 не е NULL, така:
ИЗБЕРЕТЕ идентификатор, col1,MIN(СЛУЧАЙ, КОГАТО col1 НЕ Е NULL, ТОГАВА ИД КРАЙ) НАД (ПОРЪЧАЙТЕ ПО РЕДОВЕ ИД, НЕОГРАНИЧЕНИ ПРЕДИШНИ) КАТО grpFROM dbo.T4;
Този код генерира следния изход:
id col1 grp----------- ----------- -----------2 NULL NULL3 10 35 -1 37 NULL 311 NULL 313 -12 317 NULL 319 NULL 323 1759 3
Ако има NULL числа преди първата релевантна стойност, в крайна сметка получавате две групи – първата с NULL като grp стойност, а втората с първия не-NULL идентификатор като grp стойност.
Във втората стъпка поставяте кода на първата стъпка в табличен израз. След това във външната заявка използвате функцията FIRST_VALUE, разделена от grp, за да съберете първата подходяща (не-NULL) стойност, ако е налице, и NULL в противен случай, така:
WITH C AS(ИЗБЕРЕТЕ идентификатор, col1, MIN(СЛУЧАЙ, КОГАТО col1 НЕ Е NULL, ТОГАВА id END) OVER(ПОРЪЧКА ПО идентификатор РЕДОВЕ НЕОГРАНИЧЕНА ПРЕДШЕСТВА) КАТО grpFROM dbo.T4)SELECT id, col1,FIRST_VALUE(col1) OVER( РАЗДЕЛЯНЕ ПО grp ПОРЪЧКА ПО идентификатор РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИШНИ) КАТО firstvalFROM C;
Отново, това е много код и работа в сравнение с простото използване на опцията IGNORE_NULLS.
Ако смятате, че тази функция може да ви бъде полезна, можете да гласувате за включването й в T-SQL тук.
ПЪРВО ПОРЪЧАЙТЕ НУЛИ | НУЛИ ПОСЛЕДНИ
Когато поръчвате данни, независимо дали за целите на представянето, за отваряне на прозорци, филтриране TOP/OFFSET-FETCH или друга цел, възниква въпросът как NULL трябва да се държат в този контекст? Стандартът на SQL казва, че NULL трябва да сортират заедно или преди, или след не-NULL, и те оставят на реализацията да определи единия или другия начин. Въпреки това, каквото и да избере продавачът, то трябва да бъде последователно. В T-SQL NULL се подреждат първо (преди не-NULL), когато се използва възходящ ред. Разгледайте следната заявка като пример:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersORDER BY shippeddate, orderid;
Тази заявка генерира следния изход:
<предварителна>дата на доставка----------- -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110250 2017-07-12 ...11063 2019-05-0611067 2019-05-0611069 2019-05-06Резултатът показва, че неизпратените поръчки, които имат NULL дата на доставка, поръчват преди изпратените поръчки, които имат съществуваща приложима дата на доставка.
Но какво ще стане, ако имате нужда от NULL, за да подредите последно, когато използвате възходящ ред? Стандартът ISO/IEC SQL поддържа клауза, която прилагате към израз за подреждане, контролиращ дали NULL се подреждат първи или последни. Синтаксисът на тази клауза е:
<израз за подреждане> ПЪРВО NULL | НУЛИ ПОСЛЕДНИЗа да се справим с нашите нужди, връщайки поръчките, сортирани по датите на доставка, възходящо, но с неизпратени поръчки, върнати последни и след това по идентификаторите на поръчките им като тайбрейк, ще използвате следния код:
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.OrdersORDER BY shippeddate NULLS LAST, orderid;
За съжаление, тази клауза за подреждане NULLS не е налична в T-SQL.
Често срещано решение, което хората използват в T-SQL, е да предшестват израза за подреждане с израз CASE, който връща константа с по-ниска стойност на подреждане за стойности, различни от NULL, отколкото за NULL, като така (ще наречем това решение Заявка 1):
ИЗБЕРЕТЕ идентификатор на поръчката, shippeddateFROM Sales.Orders ПОРЪЧАЙТЕ ПО СЛУЧАЙ, КОГАТО shippeddate НЕ Е NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Тази заявка генерира желания изход с NULL, които се показват последно:
<предварителна>дата на доставка----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11063 2019-05 -0611067 2019-05-0611069 2019-05-0611008 NULL11019 NULL11039 NULL...Има покриващ индекс, дефиниран в таблицата Sales.Orders, с колоната shippeddate като ключ. Въпреки това, подобно на начина, по който манипулираната филтрираща колона предотвратява възможността за SARG на филтъра и възможността за прилагане на индекс за търсене, манипулираната колона за подреждане предотвратява възможността да се разчита на подреждането на индекси, за да поддържа клаузата ORDER BY на заявката. Следователно SQL Server генерира план за заявка 1 с изричен оператор за сортиране, както е показано на фигура 1.
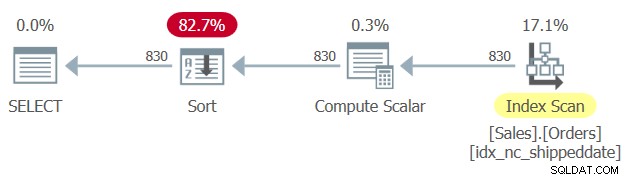 Фигура 1:План за заявка 1
Фигура 1:План за заявка 1
Понякога размерът на данните не е толкова голям, за да бъде проблем изричното сортиране. Но понякога е така. С изричното сортиране мащабируемостта на заявката става екстра-линейна (плащате повече на ред, толкова повече редове имате), а времето за отговор (времето, необходимо за връщане на първия ред) се забавя.
Има трик, който можете да използвате, за да избегнете изрично сортиране в такъв случай с решение, което се оптимизира с помощта на оператор за конкатенация на Merge Join Concatenation, запазващ реда. Можете да намерите подробно покритие на тази техника, използвана в различни сценарии в SQL Server:Избягване на сортиране с конкатенация на присъединяване при сливане. Първата стъпка в решението обединява резултатите от две заявки:една заявка връща редовете, където колоната за подреждане не е NULL с колона с резултати (ще я наречем sortcol) въз основа на константа с някаква стойност на подреждане, да речем 0, и друга заявка, връщаща редовете с NULL, с sortcol, зададен на константа с по-висока стойност на подреждане, отколкото в първата заявка, да речем 1. Във втората стъпка след това дефинирате табличен израз въз основа на кода от първата стъпка, а след това във външната заявка подреждате редовете от табличния израз първо по sortcol, а след това по останалите елементи за подреждане. Ето пълния код на решението, който реализира тази техника (ще наречем това решение Заявка 2):
WITH C AS(SELECT orderid, shippeddate, 0 AS sortcolFROM Sales.OrdersWHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcolFROM Sales.OrdersWHERE shippeddate IS NULL)DA ИЗБЕРЕТЕ идентификатор на поръчката, CROMCOPEDATE BY;
Планът за тази заявка е показан на Фигура 2.
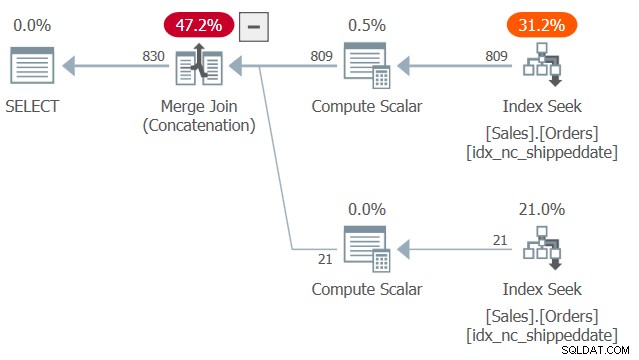 Фигура 2:План за заявка 2
Фигура 2:План за заявка 2
Забележете две търсения и подредени сканирания диапазон в покриващия индекс idx_nc_shippeddate – едното изтегля редовете, където shippeddateis не е NULL, а другото изтегля редове, където shippeddate е NULL. След това, подобно на начина, по който алгоритъмът на Merge Join работи в обединяване, алгоритъмът на Merge Join (Concatenation) обединява редовете от двете подредени страни по начин, подобен на цип, и запазва поетия ред, за да поддържа нуждите за подреждане на представяне на заявката. Не казвам, че тази техника винаги е по-бърза от по-типичното решение с израза CASE, което използва изрично сортиране. Въпреки това, първият има линейно мащабиране, а вторият има n log n мащабиране. Така че първите са склонни да се справят по-добре с голям брой редове, а вторите с малки числа.
Очевидно е добре да имаме решение за тази обща нужда, но ще бъде много по-добре, ако T-SQL добави поддръжка за стандартната клауза за подреждане NULL в бъдеще.
Заключение
Стандартът ISO/IEC SQL има доста NULL функции за обработка, които все още не са стигнали до T-SQL. В тази статия разгледах някои от тях:предиката DISTINCT, клаузата за третиране NULL и контрола дали NULL се подреждат първи или последни. Предоставих също заобиколни решения за тези функции, които се поддържат в T-SQL, но те очевидно са тромави. Следващия месец ще продължа дискусията, като разгледам стандартното уникално ограничение, как се различава от реализацията на T-SQL и заобикалящите решения, които могат да бъдат внедрени в T-SQL.



