Моят колега Стив Райт (блог | @SQL_Steve) ме подтикна с въпрос наскоро относно странен резултат, който виждаше. За да тества някои функции в нашия най-нов инструмент, SQL Sentry Plan Explorer PRO, той беше произвел широка и голяма таблица и изпълняваше различни заявки към нея. В един случай той връщаше много данни, но STATISTICS IO показваше, че се извършват много малко четения. Писнах някои хора в #sqlhelp и тъй като изглеждаше, че никой не е виждал този проблем, реших да направя блог за него.
TL;DR версия
Накратко, имайте предвид, че има някои сценарии, при които не можете да разчитате на STATISTICS IO да ти кажа истината. В някои случаи (този включва TOP и паралелизъм), той ще отчита значително недостатъчно логически показания. Това може да ви накара да повярвате, че имате много удобна за I/O заявка, когато не го правите. Има и други по-очевидни случаи – като например, когато имате куп I/O, скрити от използването на скаларни дефинирани от потребителя функции. Смятаме, че Plan Explorer прави тези случаи по-очевидни; този обаче е малко по-сложен.
Заявката за проблема
Таблицата има 37 милиона реда, до 250 байта на ред, около 1 милион страници и много ниска фрагментация (0,42% на ниво 0, 15% на ниво 1 и 0 след това). Няма изчислени колони, няма UDF в игра и няма индекси, освен клъстериран първичен ключ на водещия INT колона. Проста заявка, връщаща 500 000 реда, всички колони, използвайки TOP и SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(И да, осъзнавам, че нарушавам собствените си правила и използвам SELECT * и TOP без ORDER BY , но с цел простота се опитвам да сведа до минимум влиянието си върху оптимизатора.)
Резултати:
(засегнати 500 000 реда)Таблица „История на поръчките“. Брой на сканирането 1, логически четения 23, физически четения 0, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Връщаме 500 000 реда и отнема около 10 секунди. Веднага разбирам, че нещо не е наред с логическия номер на четене. Дори ако все още не знаех за основните данни, мога да кажа от резултатите от мрежата в Management Studio, че това извлича повече от 23 страници данни, независимо дали са от памет или кеш, и това трябва да бъде отразено някъде в STATISTICS IO . Разглеждайки плана...
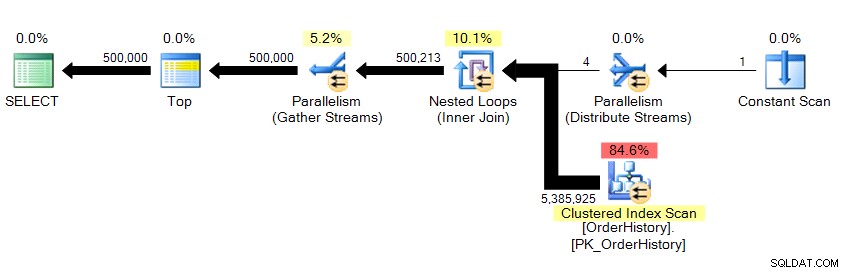
…виждаме, че има паралелизъм и че сме сканирали цялата таблица. И така, как е възможно да има само 23 логически четения?
Друга „идентична“ заявка
Един от първите ми въпроси към Стив беше:„Какво ще стане, ако премахнете паралелизма?“ Така че го изпробвах. Взех оригиналната версия на подзаявката и добавих MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Резултати и план:
(засегнати 500 000 реда)Таблица „История на поръчките“. Брой на сканиране 1, логически четения 149589, физически четения 0, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
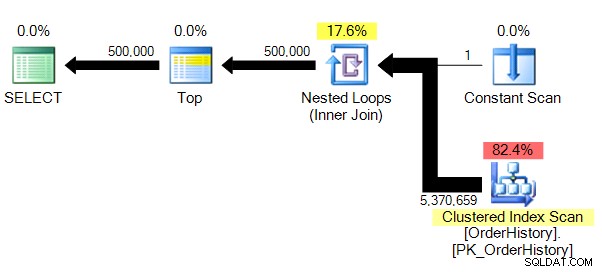
Имаме малко по-малко сложен план и без паралелизъм (по очевидни причини), STATISTICS IO ни показва много по-правдоподобни числа за логически прочетени бройки.
Каква е истината?
Не е трудно да се види, че едно от тези запитвания не казва цялата истина. Докато STATISTICS IO може да не ни разкаже цялата история, може би следа ще ни разкаже. Ако извлечем показатели по време на изпълнение, като генерираме действителен план за изпълнение в Plan Explorer, виждаме, че магическата заявка с ниско четене всъщност извлича данните от паметта или диска, а не от облак от магически прах от пикси. Всъщност има *повече* четения от другата версия:

Така че е ясно, че четенията се случват, те просто не се появяват правилно в STATISTICS IO изход.
Какъв е проблемът?
Е, ще бъда съвсем честен:не знам, освен факта, че паралелизмът определено играе роля и изглежда е някакво състояние на състезанието. STATISTICS IO (и тъй като оттам получаваме данните, нашия раздел Table I/O) показва много подвеждащ брой четения. Ясно е, че заявката връща всички данни, които търсим, и е ясно от резултатите от проследяването, че използва четения, а не осмоза, за да направи това. Попитах Пол Уайт (блог | @SQL_Kiwi) за това и той предложи, че само някои от броя на I/O преднишките са включени в общия брой (и се съгласява, че това е грешка).
Ако искате да изпробвате това у дома, всичко, от което се нуждаете, е AdventureWorks (това трябва да се повтори срещу версиите 2008, 2008 R2 и 2012) и следната заявка:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Обърнете внимание, че SETCPUWEIGHT се използва само за коаксиален паралелизъм. За повече информация вижте публикацията в блога на Пол Уайт за Планиране на разходите.)
Резултати:
Таблица 'SalesOrderHeader'. Брой на сканиране 1, логически четения 4, физически четения 0, четене напред за четене 0, логически четения на лоб 0, физически четения на лоб 0, четене напред в лоб четене 0.Таблица 'SalesOrderHeader'. Брой на сканиране 1, логически четения 333, физически четения 0, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Пол посочи още по-проста реплика:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Резултати:
Таблица „История на транзакциите“. Брой на сканиране 1, логическо четене 5, физическо четене 0, четене напред 0, логически четене на лоб 0, физическо четене на лоб 0, четене напред в лоб четене 0.Таблица 'TransactionHistory'. Брой на сканиране 1, логическо четене 110, физическо четене 0, четене напред 0, логически четене на лоб 0, физическо четене на лоб 0, четене напред за четене 0.
Така че изглежда, че можем лесно да възпроизведем това по желание с TOP оператор и достатъчно нисък DOP. Записах грешка:
- СТАТИСТИКА IO отчита недостатъчно логически показания за паралелни планове
И Пол подаде две други донякъде свързани грешки, включващи паралелизъм, първият в резултат на нашия разговор:
- Грешка при оценката на кардиналността с избутан предикат при търсене [ свързана публикация в блога ]
- Слаба производителност с паралелизъм и горна [сродна публикация в блога]
(За носталгичните, ето шест други грешки в паралелизма, които посочих преди няколко години.)
Какъв е урокът?
Внимавайте да се доверите на един източник. Ако погледнете единствено STATISTICS IO след като промените заявка като тази, може да се изкушите да се съсредоточите върху чудотворния спад в четенията, вместо върху увеличаването на продължителността. В този момент може да се потупате по гърба, да напуснете работа по-рано и да се насладите на уикенда си, мислейки, че току-що сте оказали огромно влияние върху производителността на заявката си. Когато, разбира се, нищо не може да бъде по-далеч от истината.