[ Част 1 | Част 2 | Част 3 ]
В духа на неотдавнашните изказвания на Грант Фричи и усилията на Ерин Стелато, откакто си мисля, преди да се срещнем, искам да се включа, за да тръбя и популяризирам идеята за отхвърляне на проследяването в полза на Разширените събития. Когато някой каже trace , повечето хора веднага си мислят, че Profiler . Въпреки че Profiler е собствен специален кошмар, днес исках да говоря за проследяването по подразбиране на SQL Server.
В нашата среда той е активиран на всички 200+ производствени сървъри и събира много боклук, който никога няма да разследваме. Всъщност толкова много боклук, че важни събития, които може да намерим за полезни за отстраняване на неизправности, излизат от файловете за проследяване, преди изобщо да имаме възможност. Затова започнах да обмислям възможността да го изключа, защото:
- това не е безплатно (режимът на наблюдателя за самата дейност по проследяване, входно/изходният процес, участващ в записването във файловете за проследяване, и пространството, което те консумират);
- на повечето сървъри никога не се разглежда; при други, рядко; и,
- това е лесно да се включи отново за конкретно, изолирано отстраняване на неизправности.
Няколко други неща влияят върху стойността на проследяването по подразбиране. Не може да се конфигурира по никакъв начин – не можете да промените кои събития събира, не можете да добавяте филтри и не можете да контролирате колко файлове съхранява (5), колко големи могат да станат (20 MB всеки) , или къде се съхраняват (SERVERPROPERTY('ErrorLogFileName') ). Така че ние сме изцяло на милостта на работното натоварване — на всеки даден сървър не можем да предвидим колко далеч могат да се върнат данните (събития с по-голям TextData стойностите, например, могат да заемат много повече място и да изтласкват по-старите събития по-бързо). Понякога може да се върне една седмица назад, друг път може да се върне само за минути.
Анализиране на текущото състояние
Изпълних следния код срещу 224 производствени инстанции, само за да разбера какъв вид шум запълва следата по подразбиране в нашата среда. Това вероятно е по-сложно, отколкото трябва да бъде и дори не е толкова сложно като последната заявка, която използвах, но е прилична отправна точка за анализиране на разбивката на типове събития от високо ниво, които в момента се улавят:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Предикатът EventSubClass е там, за да предотврати двойното отчитане на DDL събития.За карта на стойностите на EventClass ги изброих в този отговор на Stack Exchange.)
И резултатите не са красиви (типични резултати от случаен сървър). Следното не представлява точния изход от тази заявка, но прекарах известно време, обобщавайки резултатите в по-удобен формат, за да видя колко от данните са полезни и колко шум (щракнете за увеличаване):
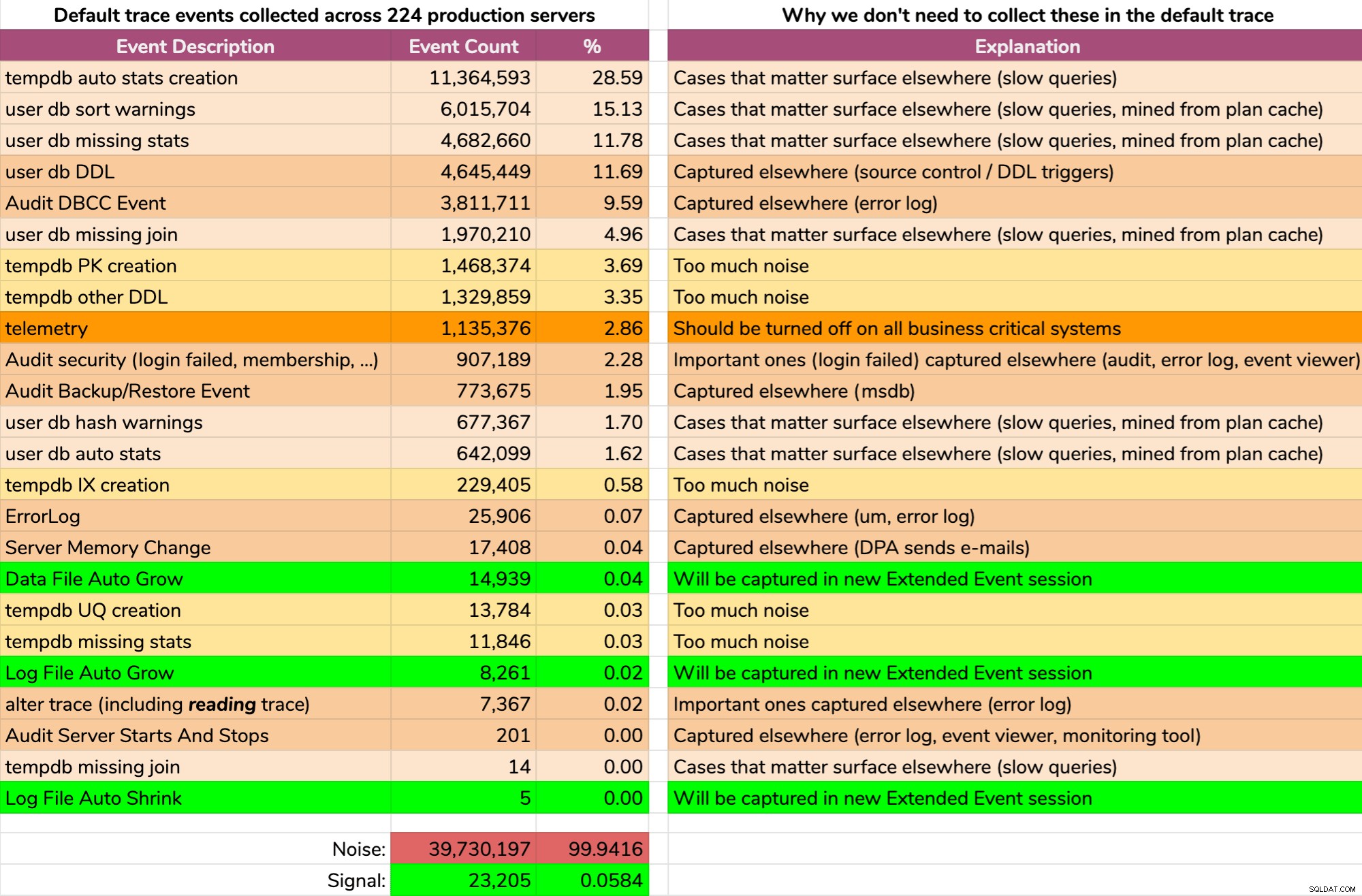
Почти целият шум (99,94%). Единственото полезно нещо, от което се нуждаехме от проследяването по подразбиране, бяха събитията за растеж и свиване на файлове, тъй като те бяха единственото нещо, което не улавяхме другаде по един или друг начин. Но дори и на това не винаги можем да разчитаме, защото данните се изливат толкова бързо.
Друг начин, по който нарязах данните:най-старото събитие на екземпляр. Някои екземпляри имаха толкова много шум, че не можеха да задържат данните за проследяване по подразбиране за повече от няколко минути! Замъглих имената на сървърите, но това са реални данни (това са 20-те сървъра с най-кратка история – щракнете, за да увеличите):
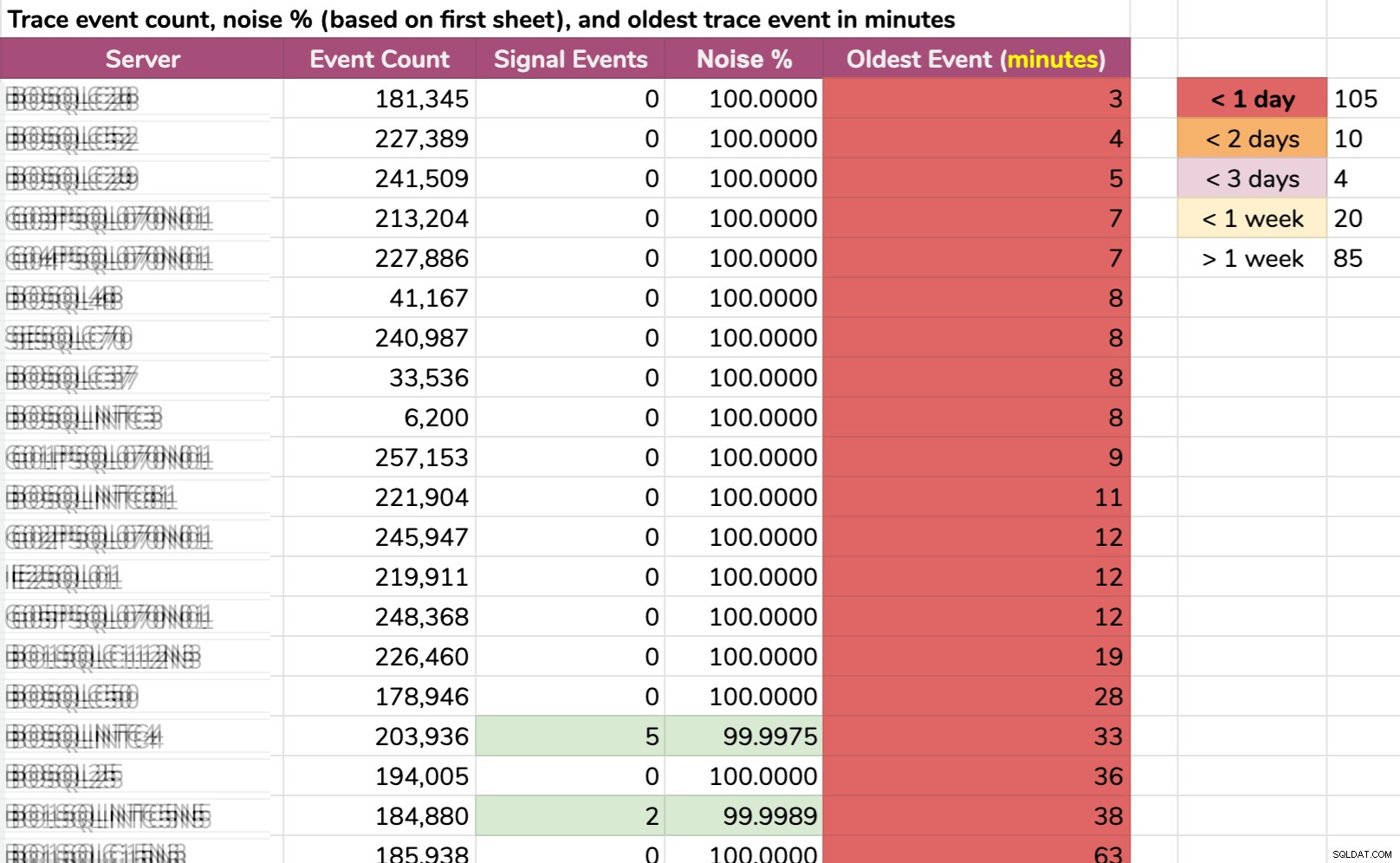
Дори ако следата събираше само подходяща информация и се случи нещо интересно, ще трябва да действаме бързо, за да я хванем, в зависимост от сървъра. Ако се е случило:
- преди 20 минути , тогава вече би изчезнал при 15 екземпляра .
- този път вчера , ще изчезне при 105 екземпляра .
- преди два дни , ще изчезне при 115 екземпляра .
- преди повече от седмица , ще бъде изчезнал при 139 екземпляра .
Имахме шепа сървъри и в другия край, но те не са интересни в този контекст; тези сървъри са такива, просто защото там не се случва нищо интересно (например не са заети или не са част от критично натоварване).
Положителната страна...
Проучването на проследяването по подразбиране разкри някои неправилни конфигурации на няколко от нашите сървъри:
- Няколко сървъра все още са с активирана телеметрия . Аз съм за подпомагане на Microsoft в определени среди, но не на всякакви режийни разходи за критични за бизнеса системи.
- Някои задачи за синхронизиране на заден план бяха добавяне на членове към роли на сляпо , отново и отново, без да проверяват дали вече са били в тези роли. Това не е вредно само по себе си, особено след като тези събития вече няма да запълват проследяването по подразбиране, но вероятно запълват и одитите с шум и вероятно има други операции на сляпо повторно прилагане, които се случват по същия модел.
- Някой е активирал автоматично свиване някъде (приятна скръб!), така че това беше нещо, което исках да проследя и да предотвратя да се случи отново (новото XE също ще улови тези събития).
Това доведе до последващи задачи за отстраняване на тези проблеми и/или добавяне на условия към съществуващата автоматизация, която вече е налице. Така че можем да предотвратим повторение, без да разчитаме само на късмета да се сблъскаме с тях при някакво бъдещо проследяване по подразбиране, преди да се пуснат.
...но проблемът остава
В противен случай всичко е или информация, върху която не можем да действаме, или, както е описано в графиката по-горе, събития, които вече сме заснели другаде. И отново, единствените данни, които ме интересуват от проследяването по подразбиране, които все още не улавяме с други средства, са събития, свързани с нарастването и свиването на файла (въпреки че проследяването по подразбиране улавя само автоматичното разнообразие).
Но по-големият проблем всъщност не е силата на шума. Мога да се справя с големи масивни трасиращи файлове с много боклук, тъй като клаузите WHERE са измислени точно за тази цел. Истинският проблем е, че важни събития изчезваха твърде бързо.
Отговорът
Отговорът, поне в нашия сценарий, беше прост:деактивирайте проследяването по подразбиране, тъй като не си струва да се изпълнява, ако не може да се разчита.
Но като се има предвид количеството шум по-горе, какво трябва да го замени? Нещо?
Може да искате сесия с разширени събития, която улавя всичко уловена е следата по подразбиране. Ако е така, Джонатан Кехайяс ви е покрил. Това ще ви даде същата информация, но с контрол върху неща като задържане, където данните се съхраняват и, когато се чувствате по-удобно, възможността да премахвате някои от по-шумните или по-малко полезни събития, постепенно, с течение на времето.
Планът ми беше малко по-агресивен и бързо се превърна в „прост“ процес за извършване на следното на всички сървъри в средата (чрез CMS):
- разработете сесия с разширени събития, която улавя само събития за промяна на файлове (както ръчни, така и автоматични)
- деактивирайте проследяването по подразбиране
- създайте изглед, за да улесните нашите екипи да използват целеви данни
Имайте предвид, че не ви предлагам сляпо да деактивирате проследяването по подразбиране , просто обяснявам защо избрах да го направя в нашата среда. В предстоящите публикации от тази серия ще покажа новата сесия на разширени събития, изгледа, който разкрива основните данни, кода, който използвах за внедряване на тези промени на всички сървъри, и потенциалните странични ефекти, които трябва да имате предвид.
[ Част 1 | Част 2 | Част 3 ]