АКТУАЛИЗИРАНЕ:2 септември 2021 г. (Публикувано първоначално на 26 юли 2012 г.)
Много неща се променят в хода на няколко основни версии на нашата любима платформа за бази данни. SQL Server 2016 ни донесе STRING_SPLIT, естествена функция, която елиминира необходимостта от много от персонализираните решения, от които се нуждаехме преди. И той е бърз, но не е идеален. Например, той поддържа само разделител от един знак и не връща нищо, за да посочи реда на входните елементи. Написах няколко статии за тази функция (и STRING_AGG, която пристигна в SQL Server 2017), след като тази публикация беше написана:
- Изненади и предположения в производителността:STRING_SPLIT()
- STRING_SPLIT() в SQL Server 2016 :Продължение №1
- STRING_SPLIT() в SQL Server 2016 :Продължение №2
- Код за замяна на разделен низ на SQL сървър с STRING_SPLIT
- Сравняване на методите за разделяне/конкатенация на низове
- Решете стари проблеми с новите функции STRING_AGG и STRING_SPLIT на SQL Server
- Справяне с разделителя от един знак във функцията STRING_SPLIT на SQL Server
- Моля, помогнете с STRING_SPLIT подобрения
- Начин за подобряване на STRING_SPLIT в SQL Server – и вие можете да помогнете
Ще оставя съдържанието по-долу тук за потомство и историческа уместност, а също и защото част от методологията на тестване е свързана с други проблеми освен разделянето на низове, но моля, вижте някои от горните препратки за информация как трябва да разделяте низове в модерни, поддържани версии на SQL Server – както и тази публикация, която обяснява защо разделянето на низове може би не е проблем, който искате базата данни да реши на първо място, нова функция или не.
- Разделяне на низове:Вече с по-малко T-SQL
Знам, че много хора са отегчени от проблема с „разделените низове“, но все още изглежда се появява почти ежедневно във форуми и сайтове за въпроси и отговори като Stack Overflow. Това е проблемът, при който хората искат да предадат низ като този:
EXEC dbo.UpdateProfile @UserID =1, @FavoriteTeams =N'Patriots,Red Sox,Bruins';
В рамките на процедурата те искат да направят нещо подобно:
ВЪВЕТЕТова не работи, защото @FavoriteTeams е един низ и горното се превежда на:
ВЪВЕТЕ dbo.UserTeams(UserID, TeamID) ИЗБЕРЕТЕ @UserID, TeamID ОТ dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins');Следователно SQL Server ще се опита да намери екип на име Patriots, Red Sox, Bruins , а предполагам, че няма такъв отбор. Това, което те наистина искат тук, е еквивалент на:
ВЪВЕТЕ dbo.UserTeams(UserID, TeamID) ИЗБЕРЕТЕ @UserID, TeamID ОТ dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins');Но тъй като в SQL Server няма тип масив, променливата изобщо не се интерпретира по този начин – тя все още е прост, единичен низ, който съдържа някои запетаи. Като оставим настрана съмнителния дизайн на схемата, в този случай списъкът, разделен със запетая, трябва да бъде „разделен“ на отделни стойности – и това е въпросът, който често предизвиква много „нови“ дебати и коментари относно най-доброто решение за постигане точно на това.
Отговорът изглежда почти винаги е, че трябва да използвате CLR. Ако не можете да използвате CLR – а знам, че има много от вас, които не могат, поради корпоративна политика, шиповокос шеф или упоритост – тогава използвате едно от многото заобиколни решения, които съществуват. И съществуват много заобиколни решения.
Но коя трябва да използвате?
Ще сравня производителността на няколко решения – и ще се съсредоточа върху въпроса, който всеки винаги си задава:„Кое е най-бързото?“ Няма да задълбочавам дискусията около *всички* потенциални методи, защото няколко вече са елиминирани поради факта, че просто не се мащабират. И може да го посетя отново в бъдеще, за да проуча влиянието върху други показатели, но засега ще се съсредоточа само върху продължителността. Ето кандидатите, които ще сравня (използвайки SQL Server 2012, 11.00.2316, на Windows 7 VM с 4 процесора и 8 GB RAM):
CLR
Ако искате да използвате CLR, определено трябва да заемете код от колегата MVP Адам Мачаник, преди да помислите за писане на свой собствен (писал съм преди това за преоткриването на колелото и това важи и за безплатни фрагменти от код като този). Той прекара много време за фина настройка на тази CLR функция, за да анализира ефективно низ. Ако в момента използвате CLR функция и това не е това, силно ви препоръчвам да я разгърнете и сравните – тествах я срещу много по-проста, базирана на VB CLR рутина, която беше функционално еквивалентна, но подходът на VB се представи около три пъти по-лошо отколкото на Адам.
Така че взех функцията на Адам, компилирах кода в DLL (с помощта на csc) и разположих точно този файл на сървъра. След това добавих следния сбор и функция към моята база данни:
СЪЗДАЙТЕ ASSEMBLY CLRUtilities ОТ 'c:\DLLs\CLRUtilities.dll' С PERMISSION_SET =SAFE; ОТКЛЮЧЕТЕ СЪЗДАЙТЕ ФУНКЦИЯ dbo.SplitStrings_CLR( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255))(Item0 NVARCHLE0)RETURNS T0 NVAR0 ) )ВЪНШНО ИМЕ CLRUtilities.UserDefinedFunctions.SplitString_Multi;GOXML
Това е типичната функция, която използвам за еднократни сценарии, при които знам, че входът е „безопасен“, но не препоръчвам за производствени среди (повече за това по-долу).
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.SplitStrings_XML( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255))ВЪЗРАЩА ТАБЛИЦА С ВЪЗРАЩАНЕ НА SCHEMABINDINGAS (ИЗБЕРЕТЕ Елемент =y.i.value('(./text())[1]', 'nvarchar 4000)') ОТ ( SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('. ') ) КАТО КРЪСТ ПРИЛОЖИ x.nodes('i') КАТО y(i) );GOМного силно предупреждение трябва да се използва заедно с XML подхода:той може да се използва само ако можете да гарантирате, че вашият входен низ не съдържа никакви незаконни XML знаци. Едно име с <,> или &и функцията ще се взриви. Така че, независимо от производителността, ако ще използвате този подход, имайте предвид ограниченията – не трябва да се счита за жизнеспособна опция за общ разделител на низове. Включвам го в този обзор, защото може да имате случай, в който можете доверете се на входа – например е възможно да се използва за разделени със запетая списъци с цели числа или GUID.
Таблица с числа
Това решение използва таблица с числа, която трябва да изградите и попълните сами. (От векове искаме вградена версия.) Таблицата Numbers трябва да съдържа достатъчно редове, за да надвишава дължината на най-дългия низ, който ще разделите. В този случай ще използваме 1 000 000 реда:
ЗАДАДЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @UpperLimit INT =1000000; WITH n AS( SELECT x =ROW_NUMBER() НАД (РЕД s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 CROSS JOIN sys.all_objects AS s3)SELECT Number =x INTO dbo.Numbers FROM. n КЪДЕ x МЕЖДУ 1 И @UpperLimit; GOCREATE UNIQUE CLUSTERED INDEX n НА dbo.Numbers(Number) С (DATA_COMPRESSION =PAGE);GO(Използването на компресиране на данни ще намали драстично броя на необходимите страници, но очевидно трябва да използвате тази опция само ако използвате Enterprise Edition. В този случай компресираните данни изискват 1360 страници, срещу 2102 страници без компресия – около 35% спестяване. )
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.SplitStrings_Numbers( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255))ВЪЗРАЩА ТАБЛИЦА СЪС SCHEMABINDINGAS ВРЪЩАНЕ ( ИЗБЕРЕТЕ Елемент =SUBSTRING(@List, Number, CHARINDEX(@Delimiter, @miter, @List + ) - Номер) ОТ dbo.Числа КЪДЕТО Номер <=CONVERT(INT, LEN(@List)) И SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) =@Delimiter );GO
Общ израз на таблица
Това решение използва рекурсивен CTE за извличане на всяка част от низа от "остатъка" от предишната част. Като рекурсивна CTE с локални променливи, ще забележите, че това трябваше да бъде функция с таблична стойност с множество изрази, за разлика от другите, които всички са вградени.
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.SplitStrings_CTE( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255))ВЪЗРАЩА @Items ТАБЛИЦА (Елемент NVARCHAR(4000))СЪС СХЕМА СВЪРЗВАНЕ НА ЗАЧИТАНЕ НА ДЕКЛАРИРАНЕ @ll INT =LEN(@List) ld INT =LEN(@Delimiter); С AS ( SELECT [начало] =1, [край] =КОАЛЕСЦИЯ(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll), [стойност] =SUBSTRING(@List, 1, COALESCE( NULLIF(CHARINDEX(@Delimiter, @List, 1), @ll) - 1) UNION ALL SELECT [начало] =CONVERT(INT, [край]) + @ld, [end] =COALESCE(NULLIF(CHARINDEX (@Delimiter, @List, [end] + @ld), 0), @ll), [value] =SUBSTRING(@List, [end] + @ld, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + @ld), 0), @ll)-[end]-@ld) ОТ КЪДЕ [край] <@ll ) INSERT @Items SELECT [стойност] ОТ WHERE LEN([стойност])> 0 ОПЦИЯ (МАКС.РЕКУРСИЯ 0); ВРЪЩАНЕ;ENDGO
Сплитерът на Джеф МодънФункция, базирана на сплитера на Jeff Moden с малки промени за поддръжка на по-дълги низовеВ SQLServerCentral, Джеф Модън представи функция за разделяне, която съперничи на производителността на CLR, така че смятах, че е справедливо да се включа вариант, използващ подобен подход в това обобщение. Трябваше да направя няколко малки промени в неговата функция, за да се справя с най-дългия ни низ (500 000 знака), а също така направих конвенциите за именуване подобни:
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.SplitStrings_Moden( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255))ВЪРНА ТАБЛИЦА СЪС СХЕМА ОБВЪРЖАНЕ СЪС E1(N) КАТО ( ИЗБЕРЕТЕ 1 ОБЪЕД ВСИЧКИ ИЗБЕРЕТЕ 1 ОБЪЕД ВСИЧКИ ИЗБЕРЕТЕ ВСИЧКИ ИЗБЕРЕТЕ 1 СЪЮЗ ИЗБЕРЕТЕ SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1), E2(N) AS (ИЗБЕРЕТЕ 1 ОТ E1 a, E1 b), E4(N) AS (ИЗБЕРЕТЕ 1 ОТ E2 a, E2 b), E42(N) AS (ИЗБЕРЕТЕ 1 ОТ E4 a, E2 b), cteTally(N) AS (ИЗБЕРЕТЕ 0 СЪЕДИНЕНИЕ ВСИЧКИ ИЗБЕРЕТЕ ВЪРХА (ДЪЛЖИНА НА ДАННИ(ISNULL(@List,1))) ROW_NUMBER() НАД (ПОРЪЧАЙТЕ ПО (ИЗБЕРЕТЕ NULL)) ОТ E42), cteStart(N1) КАТО (ИЗБЕРЕТЕ t.N+1 ОТ cteTally t КЪДЕ (ПОДНИЗ(@List,t.N,1) =@Delimiter ИЛИ t.N =0)) ИЗБЕРЕТЕ Елемент =SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000)) ОТ cteStart s;Като настрана, за тези, които използват решението на Джеф Моден, може да помислите за използването на таблица с числа, както е по-горе, и да експериментирате с лека вариация на функцията на Джеф:
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.SplitStrings_Moden2( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255))ВЪЗРАЩА ТАБЛИЦА СЪС СХЕМА ОБВЪЗВАНЕ НА ВРЪЩАНЕ С cteTally(N) КАТО ( ИЗБЕРЕТЕ ВЪРХ (ИЗБЕРЕТЕ ДЪЛЖИНА НА ДАННИ(ISNULL)+@List1,1) Число-1 ОТ dbo.Numbers ПОРЪЧАЙТЕ ПО Номер ), cteStart(N1) КАТО ( ИЗБЕРЕТЕ t.N+1 ОТ cteTally t КЪДЕ (ПОДНИЗ(@List,t.N,1) =@Delimiter ИЛИ t.N =0) ) ИЗБЕРЕТЕ Елемент =SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000)) ОТ cteStart AS s;(Това ще обменя малко по-високи показания за малко по-нисък процесор, така че може да е по-добре в зависимост от това дали вашата система вече е свързана с процесор или I/O.)
Проверка за здравина
Само за да сме сигурни, че сме на прав път, можем да проверим дали всичките пет функции връщат очакваните резултати:
DECLARE @s NVARCHAR(MAX) =N'Patriots,Red Sox,Bruins'; ИЗБЕРЕТЕ Елемент ОТ dbo.SplitStrings_CLR (@s, N',');ИЗБЕРЕТЕ елемент ОТ dbo.SplitStrings_XML (@s, N',');ИЗБЕРЕТЕ елемент ОТ dbo.SplitStrings_Numbers (@s, N',');ИЗБЕРЕТЕ елемент ОТ dbo.SplitStrings_CTE (@s, N',');ИЗБЕРЕТЕ Елемент ОТ dbo.SplitStrings_Moden (@s, N',');И всъщност това са резултатите, които виждаме и в петте случая...
Тестовите данни
Сега, когато знаем, че функциите се държат според очакванията, можем да стигнем до забавната част:тестване на производителността срещу различен брой низове с различна дължина. Но първо имаме нужда от маса. Създадох следния прост обект:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.strings( тип_низ TINYINT, низова стойност NVARCHAR(MAX)); СЪЗДАЙТЕ КЛУСТРИРАН ИНДЕКС st ON dbo.strings(string_type);Напълних тази таблица с набор от низове с различна дължина, като се уверих, че за всеки тест ще се използва приблизително един и същ набор от данни – първо 10 000 реда, където низът е дълъг 50 знака, след това 1000 реда, където низът е дълъг 500 знака , 100 реда, където низът е дълъг 5000 знака, 10 реда, където низът е дълъг 50 000 знака, и така нататък до 1 ред от 500 000 знака. Направих това, за да сравня едно и също количество общи данни, обработвани от функциите, както и за да се опитам да запазя времето си за тестване донякъде предвидимо.
Използвам таблица #temp, за да мога просто да използвам GO
, за да изпълня всяка партида определен брой пъти: ЗАДАДЕТЕ NOCOUNT ON;GOCREATE TABLE #x(s NVARCHAR(MAX));INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';GOINSERT dbo.strings SELECT 1, s ОТ #x;GO 10000INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x;GO 1000INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x;GO 100INSERT dbo .strings SELECT 4, REPLICATE(s,1000) FROM #x;GO 10INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x;GODROP TABLE #x;GO -- след това, за да почистите последната запетая, тъй като някои подходи третират краен празен низ като валиден елемент:UPDATE dbo.strings SET string_value =SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';Създаването и попълването на тази таблица отне около 20 секунди на моята машина и таблицата представлява данни на стойност около 6 MB (около 500 000 знака по 2 байта, или 1 MB на тип string_type, плюс ред и индекс). Не е огромна таблица, но трябва да е достатъчно голяма, за да подчертае всякакви разлики в производителността между функциите.
Тестовете
С функциите на място и таблицата правилно напълнена с големи струни за дъвчене, най-накрая можем да проведем някои реални тестове, за да видим как различните функции се представят спрямо реални данни. За да измеря производителността, без да вземам предвид мрежовите разходи, използвах SQL Sentry Plan Explorer, изпълнявайки всеки набор от тестове 10 пъти, събирайки показателите за продължителността и усреднявайки.
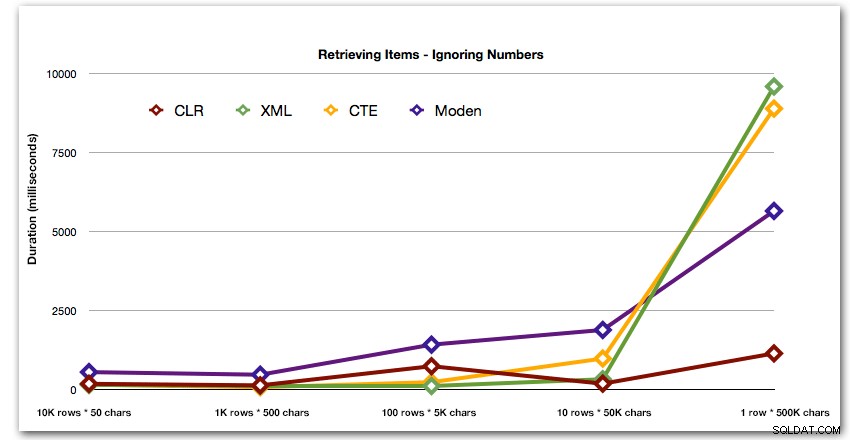
Първият тест просто изтегли елементите от всеки низ като набор:
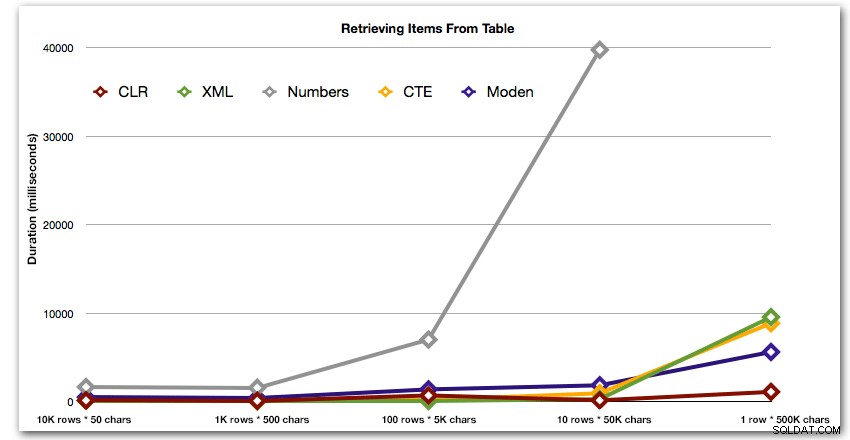
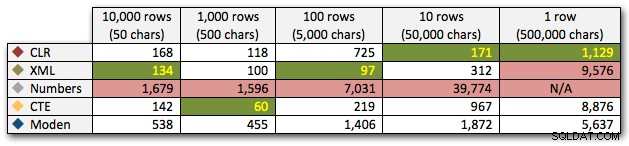
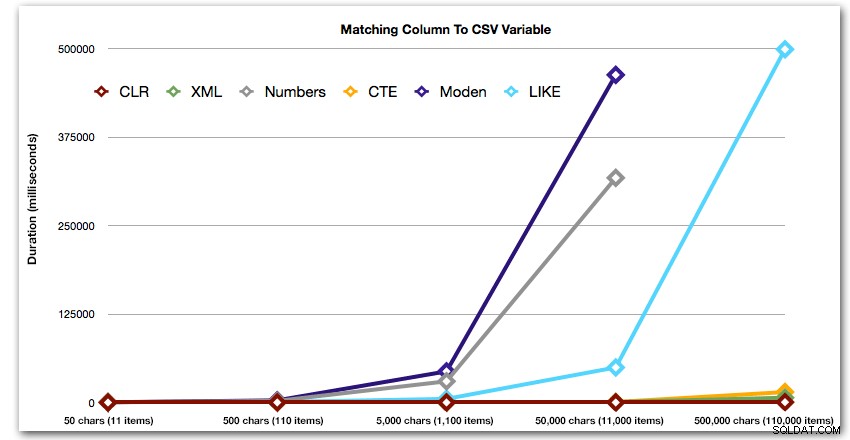
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE; ДЕКЛАРИРАНЕ @string_type TINYINT =; -- 1-5 отгоре ИЗБЕРЕТЕ t.Item ОТ dbo.strings AS s КРЪСТО ПРИЛОЖИ dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type =@string_type;Резултатите показват, че когато струните стават по-големи, предимството на CLR наистина блести. В долния край резултатите бяха смесени, но отново XML методът трябва да има звездичка до него, тъй като използването му зависи от разчитането на XML-безопасен вход. За този конкретен случай на използване таблицата Numbers постоянно се представяше най-лошо:
Продължителност, в милисекундиСлед хиперболичното 40-секундно представяне за таблицата с числа срещу 10 реда от 50 000 знака, го изхвърлих от стартирането за последния тест. За да покажа по-добре относителната производителност на четирите най-добри метода в този тест, махнах резултатите от числата изцяло от графиката:
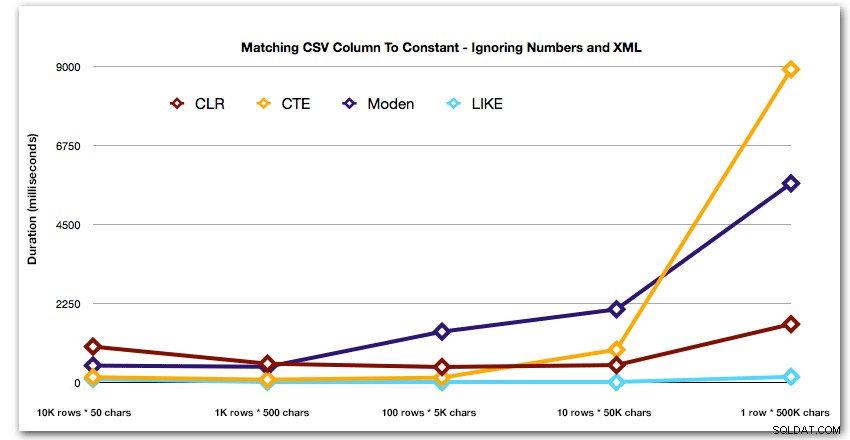
След това нека сравним кога извършваме търсене спрямо стойността, разделена със запетая (например връщане на редовете, където един от низовете е 'foo'). Отново ще използваме петте функции по-горе, но също така ще сравним резултата с търсене, извършено по време на изпълнение, използвайки LIKE, вместо да се занимаваме с разделяне.
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE; ДЕКЛАРИРАНЕ @i INT =, @search NVARCHAR(32) =N'foo';;WITH s(st, sv) AS ( SELECT string_type, string_value FROM dbo.strings AS s WHERE string_type =@i)SELECT s.string_type, s.string_value FROM s КРЪСТ APPLY dbo.SplitStrings_(s.sv, ',') AS t WHERE t.Item =@search; ИЗБЕРЕТЕ s.string_type ОТ dbo.strings КЪДЕ string_type =@i И ',' + string_value + ',' КАТО '%,' + @search + ',%';Тези резултати показват, че за малки низове CLR всъщност е най-бавният и че най-доброто решение ще бъде извършването на сканиране с помощта на LIKE, без изобщо да се притеснявате да разделяте данните. Отново пуснах решението на таблицата Numbers от 5-ия подход, когато беше ясно, че продължителността му ще се увеличи експоненциално с нарастването на размера на низа:
Продължителност, в милисекундиИ за да демонстрирам по-добре моделите за първите 4 резултата, премахнах решенията Numbers и XML от графиката:
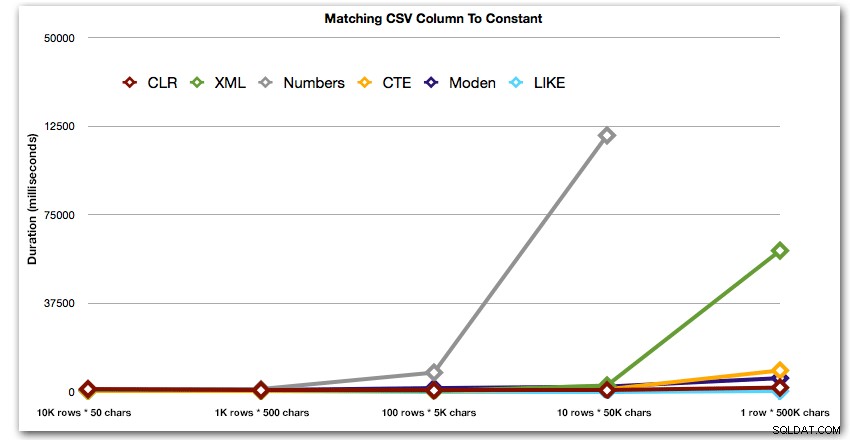
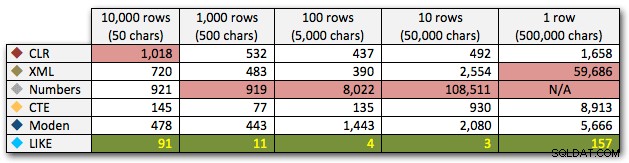
След това нека разгледаме репликирането на случая на употреба от началото на тази публикация, където се опитваме да намерим всички редове в една таблица, които съществуват в списъка, който се предава. Както и с данните в таблицата, която създадохме по-горе, ние ще създадете низове с различна дължина от 50 до 500 000 знака, ще ги съхраните в променлива и след това ще проверите общ изглед на каталог за съществуващи в списъка.
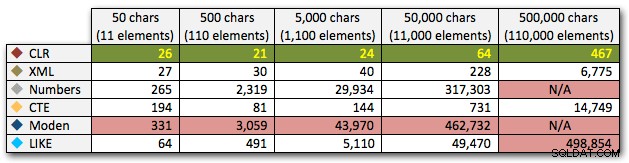
DECLARE @i INT =, -- стойност 1-5, даващи низове 50 - 500 000 знака @x NVARCHAR(MAX) =N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge ,бекон,'; SET @x =REPLICATE(@x, POWER(10, @i-1)); SET @x =SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT c.[object_id] FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x WHERE Item =c.name ) ORDER BY c.[object_id]; ИЗБЕРЕТЕ [object_id] ОТ sys.all_columns WHERE N',' + @x + ',' LIKE N'%,' + име + ',%' ПОРЪЧАЙТЕ ПО [object_id];Тези резултати показват, че за този модел няколко метода виждат, че продължителността им се увеличава експоненциално с увеличаване на размера на низа. В долния край XML поддържа добро темпо с CLR, но това също бързо се влошава. CLR постоянно е безспорният победител тук:
Продължителност, в милисекундиИ отново без методите, които експлодират нагоре по отношение на продължителност:
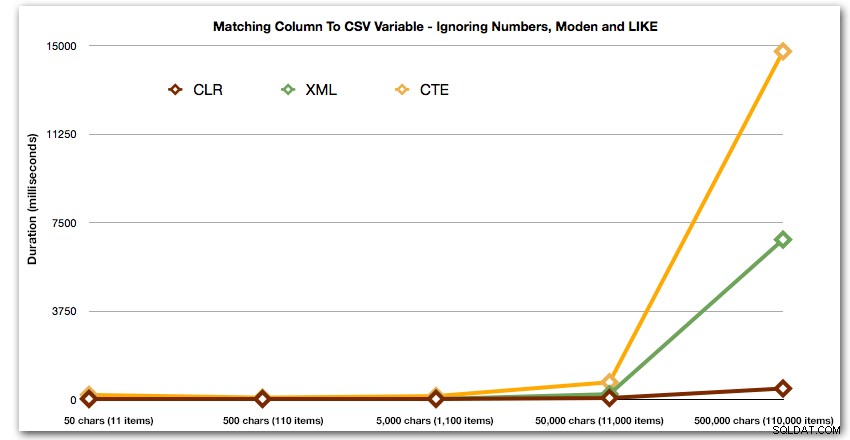
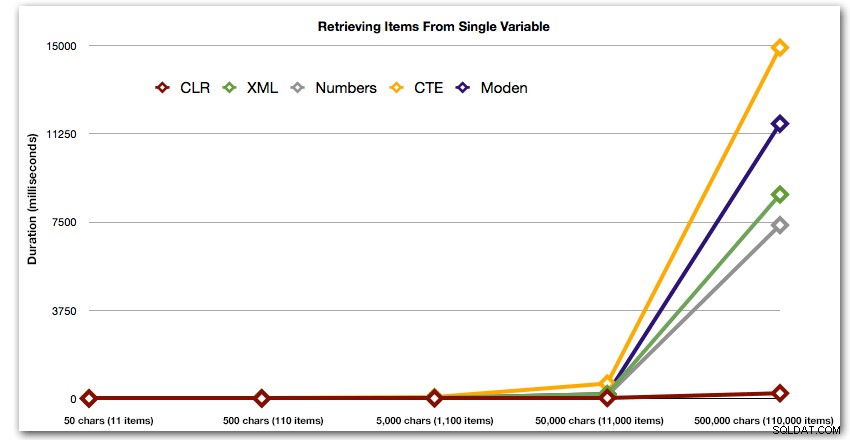
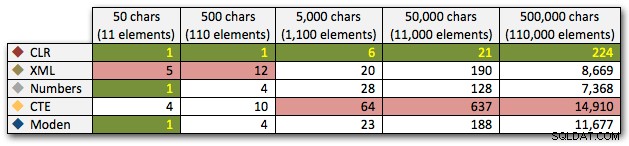
И накрая, нека сравним разходите за извличане на данни от една променлива с различна дължина, като игнорираме разходите за четене на данни от таблица. Отново ще генерираме низове с различна дължина, от 50 – 500 000 знака, и след това просто ще върнем стойностите като набор:
DECLARE @i INT =, -- стойност 1-5, даващи низове 50 - 500 000 знака @x NVARCHAR(MAX) =N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge ,бекон,'; SET @x =REPLICATE(@x, POWER(10, @i-1)); SET @x =SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; ИЗБЕРЕТЕ Елемент ОТ dbo.SplitStrings_(@x, N',');Тези резултати също показват, че CLR е доста плоска по отношение на продължителността, чак до 110 000 елемента в комплекта, докато другите методи поддържат прилично темпо до известно време след 11 000 елемента:
Продължителност, в милисекундиЗаключение
В почти всички случаи решението CLR явно превъзхожда другите подходи – в някои случаи това е убедителна победа, особено когато размерите на низовете се увеличават; в няколко други това е фото завършек, който може да падне така или иначе. В първия тест видяхме, че XML и CTE превъзхождат CLR в ниския край, така че ако това е типичен случай на употреба *и* сте сигурни, че вашите низове са в диапазона от 1 – 10 000 знака, един от тези подходи може бъде по-добър вариант. Ако размерите на низовете ви са по-малко предвидими от това, CLR вероятно все още е най-добрият ви залог като цяло – губите няколко милисекунди в ниския край, но печелите много във високия край. Ето изборите, които бих направил, в зависимост от задачата, като второто място е подчертано за случаите, когато CLR не е опция. Обърнете внимание, че XML е моят предпочитан метод само ако знам, че входът е XML-безопасен; това може да не са непременно най-добрите ви алтернативи, ако имате по-малко доверие във вашия принос.
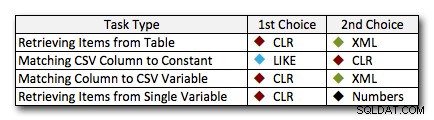
Единственото истинско изключение, при което CLR не е моят избор повсеместно, е случаят, когато всъщност съхранявате списъци, разделени със запетая, в таблица и след това намирате редове, където дефиниран обект е в този списък. В този конкретен случай вероятно бих препоръчал първо да се преработи и нормализира правилно схемата, така че тези стойности да се съхраняват отделно, вместо да се използва като извинение да не се използва CLR за разделяне.
Ако не можете да използвате CLR по други причини, няма ясно изразено „второ място“, разкрито от тези тестове; моите отговори по-горе се базираха на цялостен мащаб, а не на конкретен размер на низа. Всяко решение тук е на второ място в поне един сценарий – така че докато CLR очевидно е изборът кога можете да го използвате, това, което трябва да използвате, когато не можете, е по-скоро отговорът „зависи“ – ще трябва да прецените въз основа на вашия случай(и) на използване и тестовете по-горе (или чрез изграждане на свои собствени тестове), коя алтернатива е по-добра за вас.
Допълнение :Алтернатива на разделянето на първо място
Горните подходи не изискват промени в съществуващото(ите) приложение(а), ако приемем, че те вече сглобяват разделен със запетая низ и го хвърлят в базата данни, за да се справят. Една от опциите, която трябва да обмислите, ако CLR не е опция и/или можете да модифицирате приложението(ата), е използването на параметри с таблица с стойност (TVP). Ето един бърз пример за това как да използвате TVP в горния контекст. Първо, създайте тип таблица с колона с един низ:
СЪЗДАЙТЕ ТИП dbo.Items КАТО ТАБЛИЦА( Елемент NVARCHAR(4000));Тогава съхранената процедура може да приеме това TVP като вход и да се присъедини към съдържанието (или да го използва по други начини – това е само един пример):
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.UpdateProfile @UserID INT, @TeamNames dbo.Items ЧЕТЕТЕ ДА СЕ ЗАПОЧНЕТЕ ЗАДАДЕТЕ NOCOUNT ON; INSERT dbo.UserTeams(UserID, TeamID) ИЗБЕРЕТЕ @UserID, t.TeamID ОТ dbo.Teams КАТО t INNER JOIN @TeamNames AS tn ON t.Name =tn.Item;ENDGOСега във вашия C# код, например, вместо да създавате разделен със запетая низ, попълнете DataTable (или използвайте каквато и да е съвместима колекция, която вече може да съдържа вашия набор от стойности):
DataTable tvp =new DataTable();tvp.Columns.Add(new DataColumn("Item")); // в цикъл от колекция, вероятно:tvp.Rows.Add(someThing.someValue); using (connectionObject){ SqlCommand cmd =new SqlCommand("dbo.UpdateProfile", connectionObject); cmd.CommandType =CommandType.StoredProcedure; SqlParameter tvparam =cmd.Parameters.AddWithValue("@TeamNames", tvp); tvparam.SqlDbType =SqlDbType.Structured; // други параметри, напр. userId cmd.ExecuteNonQuery();}Може да смятате, че това е предистория на последваща публикация.
Разбира се, че това не работи добре с JSON и други приложни програмни интерфейси (API) – доста често причината, разделена със запетая низ да се предава на SQL Server на първо място.