Сериализиращият се ниво на изолация осигурява пълна защита от ефекти на едновременност, които могат да застрашат целостта на данните и да доведат до неправилни резултати от заявката. Използването на сериализираща се изолация означава, че ако транзакция, за която може да се покаже, че дава правилни резултати без едновременна дейност, тя ще продължи да работи правилно, когато се конкурира с всяка комбинация от едновременни транзакции.
Това е много мощна гаранция и такъв, който вероятно отговаря на очакванията за интуитивната изолация на транзакциите на много T-SQL програмисти (въпреки че в действителност, сравнително малко от тях ще използват рутинно сериализираща се изолация в производството).
SQL стандартът дефинира три допълнителни нива на изолация, които предлагат много по-слаба ACID гаранции за изолация, отколкото сериализиращи се, в замяна на потенциално по-висок паралелизъм и по-малко потенциални странични ефекти като блокиране, блокиране и прекъсвания по време на записване.
За разлика от сериализиращата се изолация, другите нива на изолация се дефинират единствено от гледна точка на определени явления на едновременност, които могат да бъдат наблюдавани. Следващото най-силно от стандартните нива на изолация след сериализиране се нарича повторяемо четене . Стандартът на SQL уточнява, че транзакциите на това ниво позволяват едно явление на паралелност, известно като фантом .
Точно както по-рано видяхме важни разлики между общото интуитивно значение на свойствата на ACID транзакции и реалността, фантомният феномен обхваща по-широк спектър от поведения, отколкото често се оценява.
Тази публикация от поредицата разглежда действителните гаранции, предоставени от повтарящото се четене ниво на изолация и показва някои от поведенията, свързани с фантомите, които могат да се срещнат. За да илюстрираме някои точки, ще се обърнем към следната проста примерна заявка, където простата задача е да преброим общия брой редове в таблица:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Повтарящо се четене
Едно странно нещо за повторяемото ниво на изолация на четене е, че не всъщност гарантира, че четенията са повтаряеми , поне в един общоразбираем смисъл. Това е друг пример, когато само интуитивното значение може да бъде подвеждащо. Изпълнението на една и съща заявка два пъти в рамките на една и съща повторяема транзакция за четене наистина може да върне различни резултати.
В допълнение към това, внедряването на повторяемото четене на SQL Server означава, че едно четене на набор от данни може да пропусне някои редове това логично трябва да се вземе предвид в резултата от заявката. Макар и безспорно да е специфично за реализацията, това поведение е напълно в съответствие с дефиницията за повторяемо четене, съдържаща се в стандарта SQL.
Последното нещо, което искам да отбележа бързо, преди да се задълбоча в подробности, е, че повторяемото четене в SQL Server не предоставят изглед на данните в даден момент.
Неповтарящи се четения
Повторяемото ниво на изолация на четене осигурява гаранция, че данните няма да се променят за целия живот на транзакциятаслед като бъде прочетена за първи път.
Има няколко тънкости, съдържащи се в това определение. Първо, позволява на данните да се променят след транзакцията започва, но преди данните да са първи достъпен. Второ, няма гаранция, че транзакцията действително ще срещне всички данни, които логически отговарят на изискванията. Скоро ще видим примери и за двете.
Има още една предварителна заявка, която трябва бързо да се измъкнем от пътя, която е свързана с примерната заявка, която ще използваме. Честно казано, семантиката на тази заявка е малко размита. С риск да прозвучи леко философски, какво значит за да преброите броя на редовете в таблицата? Трябва ли резултатът да отразява състоянието на таблицата, каквото е било в определен момент от време? Този момент във времето трябва да бъде началото или края на транзакцията, или нещо друго?
Това може да изглежда малко придирчиво, но въпросът е валиден във всяка база данни, която поддържа едновременно четене и модификации на данни. Изпълнението на нашата примерна заявка може да отнеме произволно дълъг период от време (предвид достатъчно голяма таблица или ограничения на ресурсите например), така че едновременните промени не само са възможни, но и може да са неизбежни .
Основният проблем тук е потенциалът за феномена на едновременност, наричан фантом в стандарта SQL. Докато броим редовете в таблицата, друга едновременна транзакция може да вмъкне нови редове на място, което вече сме проверили, илипроменетете ред, който все още не сме проверили, така че да се премести на място, което вече сме търсили. Хората често мислят за фантомите като за редове, които могат да се появят магически, когато се четат за втори път, в отделно изявление, но ефектите могат да бъдат много по-фини от това.
Пример за едновременно вмъкване
Този първи пример показва как едновременните вмъквания могат да доведат до неповтаряем четене и/или води до пропускане на редове. Представете си, че нашата тестова таблица първоначално съдържа пет реда със стойностите, показани по-долу:

Сега задаваме нивото на изолация на повторяемо четене, стартираме транзакция и изпълняваме нашата заявка за броене. Както бихте очаквали, резултатът епет . Засега няма голяма мистерия.
Все още се изпълнява вътре в същата повторяема транзакция за четене , стартираме отново заявката за броене, но този път, докато втора паралелна транзакция вмъква нови редове в същата таблица. Диаграмата по-долу показва последователността от събития, като втората транзакция добавя редове със стойности 2 и 6 (може да сте забелязали, че тези стойности са забележими поради липсата им точно по-горе):
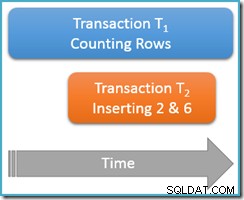
Ако нашата заявка за броене се изпълняваше в сериализиращия се ниво на изолация, ще бъде гарантирано, че ще брои или пет или седем редове (вижте предишната статия от тази серия, ако имате нужда от освежаване защо това е така). Как протича бягането впо-малко изолирано повтарящото се ниво на четене влияе на нещата?
Е, повтарящо се четене изолацията гарантира, че второто изпълнение на заявката за броене ще види всички по-рано прочетени редове и те ще бъдат в същото състояние като преди. Уловката е, че повторяемата изолация на четене не казва нищо за това как транзакцията трябва да третира новите редове (фантомите).
Представете си, че нашата транзакция за броене на редове (T1 ) има стратегия за физическо изпълнение, при която редовете се търсят във възходящ ред на индекси. Това е често срещан случай, например, когато от машината за изпълнение се използва пренаредено сканиране на индекс на b-дърво. Сега, точно след транзакция T1 брои редове 1 и 3 във възходящ ред, транзакция T2 може да се промъкне, да вмъкне нови редове 2 и 6 и след това да извърши транзакцията си.
Въпреки че в този момент мислим предимно за логически поведения, трябва да спомена, че в заключващата реализация на SQL Server на повторяемото четене няма нищо, което да предотвратява транзакция T2 от правенето на това. Споделени заключвания, взети от транзакция T1 на по-рано прочетени редове предотвратяват промяната на тези редове, но не пречат на новите редове от вмъкване в диапазона от стойности, тествани от нашата заявка за броене (за разлика от заключването на диапазона на ключове при заключването на сериализираща се изолация).
Както и да е, с ангажиментите на двата нови реда, транзакция T1 продължава търсенето си във възходящ ред, като в крайна сметка се натъква на редове 4, 5, 6 и 7. Имайте предвид, че T1 вижда нов ред 6 в този сценарий, но не нов ред 2 (поради подреденото търсене и неговата позиция при вмъкването).
Резултатът е, че повтарящото се четене преброяването на заявката съобщава, че таблицата съдържа шест реда (стойности 1, 3, 4, 5, 6 и 7). Този резултат е несъвместим с предишния резултат от пет реда получени в рамките на същата транзакция . Второто четене преброи фантомен ред 6, но пропусна фантомен ред 2. Толкова за интуитивното значение на повторяемото четене!
Пример за едновременна актуализация
Подобна ситуация може да възникне при едновременна актуализация вместо вложка. Представете си, че нашата тестова таблица е нулирана, за да съдържа същите пет реда, както преди:

Този път ще изпълним нашата заявка за броене само веднъж при повтарящото се четене ниво на изолация, докато втора едновременна транзакция актуализира реда със стойност 5, за да има стойност 2:
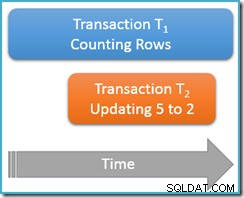
Транзакция T1 отново започва да брои редовете, (във възходящ ред) срещайки първи редове 1 и 3. Сега транзакцията T2 се вмъква, променя стойността на ред 5 на 2 и се ангажира:

Показах актуализирания ред в същата позиция като преди, за да направя промяната ясна, но индексът на b-дървото, който сканираме, поддържа данните в логически ред, така че реалната картина е по-близка до тази:

Въпросът е, че транзакцията T1 едновременно сканира същата тази структура в преден ред, като в момента се позиционира точно след записът за стойност 3. Заявката за броене продължава да сканира напред от тази точка, намирайки редове 4 и 7 (но не и ред 5, разбира се).
За да обобщим, заявката за броене видя редове 1, 3, 4 и 7 в този сценарий. Той отчита броя на четири реда – което е странно, защото таблицата изглежда съдържапет реда навсякъде!
Второ изпълнение на заявката за броене в рамките на същата повторяема транзакция за четене ще отчете пет редове по същите причини както преди. Като последна забележка, в случай, че се чудите, едновременните изтривания не предоставят възможност за фантомно-базирана аномалия при повторяема изолация на четене.
Последни мисли
И двата предходните примера използваха сканиране във възходящ ред на индексна структура, за да представят прост изглед на вида на ефектите, които фантомите могат да имат върху повтарящо се четене запитване. Важно е да се разбере, че тези илюстрации не разчитат по никакъв важен начин на посоката на сканиране или на факта, че е използван индекс на b-дърво. Моля, не формирайте мнението, че поръчаните сканирания са някак отговорни и следователно трябва да се избягват!
Същите ефекти на едновременност могат да се видят при сканиране в низходящ ред на индексна структура или в различни други сценарии за достъп до физически данни. Основното е, че фантомните явления са специално разрешени (макар и да не се изискват) от стандарта SQL за транзакции при повторяемо ниво на изолиране на четене.
Не всички транзакции изискват пълната гаранция за изолиране, осигурена от сериализираща се изолация, и не много системи биха могли да толерират страничните ефекти, ако го направят. Въпреки това си струва да имате добро разбиране кои точно гаранции предоставят различните нива на изолация.
Следващия път
Следващата част от тази поредица разглежда още по-слабите гаранции за изолация, предлагани от нивото на изолация по подразбиране на SQL Server, прочетете ангажирано .
[ Вижте индекса за цялата серия ]