Най-добрият сценарий е, че в случай на повреда на базата данни, имате добър план за възстановяване след бедствие (DRP) и високодостъпна среда с автоматичен процес на отказ, но... какво се случва, ако не успее за някаква неочаквана причина? Ами ако трябва да извършите ръчно преминаване при отказ? В този блог ще споделим някои препоръки, които да следвате, в случай че се наложи да преминете при отказ на вашата база данни.
Проверки за проверка
Преди да извършите каквато и да е промяна, трябва да проверите някои основни неща, за да избегнете нови проблеми след процеса на отказ.
Състояние на репликация
Възможно е в момента на отказ подчинения възел да не е актуален поради повреда в мрежата, голямо натоварване или друг проблем, така че трябва да се уверите, че slave разполага с цялата (или почти цялата) информация. Ако имате повече от един подчинен възел, трябва също да проверите кой е най-напредналият възел и да го изберете за превключване при отказ.
напр.:Нека проверим състоянието на репликация в сървър на MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)В случай на PostgreSQL е малко по-различно, тъй като трябва да проверите състоянието на WAL и да сравните приложените с извлечените.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Идентификационни данни
Преди да стартирате отказоустойчивостта, трябва да проверите дали вашето приложение/потребители ще имат достъп до новия ви главен файл с текущите идентификационни данни. Ако не копирате потребителите на вашата база данни, може би идентификационните данни са били променени, така че ще трябва да ги актуализирате в подчинените възли преди каквито и да било промени.
напр.:Можете да потърсите потребителската таблица в базата данни mysql, за да проверите потребителските идентификационни данни в MariaDB/MySQL сървър:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
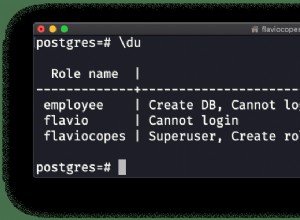
12 rows in set (0.001 sec)В случай на PostgreSQL можете да използвате командата ‘\du’, за да знаете ролите, а също така трябва да проверите конфигурационния файл pg_hba.conf, за да управлявате потребителския достъп (не идентификационни данни). И така:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}И pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustДостъп до мрежа/защитна стена
Идентификационните данни не са единственият възможен проблем при достъпа до новия ви главен файл. Ако възелът е в друг център за данни или имате локална защитна стена за филтриране на трафика, трябва да проверите дали имате достъп до него или дори дали имате мрежов маршрут за достигане до новия главен възел.
например:iptables. Нека разрешим трафика от мрежата 167.124.57.0/24 и да проверим текущите правила, след като го добавим:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationнапр.:маршрути. Да предположим, че вашият нов главен възел е в мрежата 10.0.0.0/24, вашият сървър на приложения е в 192.168.100.0/24 и можете да достигнете до отдалечената мрежа, като използвате 192.168.100.100, така че във вашия сървър на приложения добавете съответния маршрут:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Точки за действие
След като проверите всички споменати точки, трябва да сте готови да извършите действията за преодоляване на вашата база данни.
Нов IP адрес
Тъй като ще популяризирате подчинен възел, главният IP адрес ще се промени, така че ще трябва да го промените във вашето приложение или клиентски достъп.
Използването на Load Balancer е отличен начин да избегнете този проблем/промяна. След процеса на отказ, Load Balancer ще открие стария главен файл като офлайн и (в зависимост от конфигурацията) ще изпрати трафика към новия, за да запише върху него, така че не е необходимо да променяте нищо в приложението си.
напр.:Нека да видим пример за конфигурация на HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkВ този случай, ако един възел не работи, HAProxy няма да изпраща трафик там и ще изпраща трафика само до наличния възел.
Преконфигурирайте подчинените възли
Ако имате повече от един подчинен възел, след като повишите един от тях, трябва да преконфигурирате останалите подчинени, за да се свържат с новия главен. Това може да е отнемаща време задача, в зависимост от броя на възлите.
Проверете и конфигурирайте архивите
След като имате всичко на място (повишен нов главен, преконфигурирани подчинени устройства, писане на приложението в новия главен обект), важно е да предприемете необходимите действия, за да предотвратите нов проблем, така че архивирането е задължително тази стъпка. Най-вероятно сте имали правила за архивиране, работещи преди инцидента (ако не, трябва да го имате със сигурност), така че трябва да проверите дали архивите все още се изпълняват или ще работят в новата топология. Възможно е резервните копия да се изпълняват на стария главен възел или да използвате подчинения възел, който е главен сега, така че трябва да го проверите, за да се уверите, че вашата политика за архивиране ще продължи да работи след промените.
Наблюдение на базата данни
Когато изпълнявате процес на отказ, наблюдението е задължително преди, по време и след процеса. С това можете да предотвратите проблем, преди да се влоши, да откриете неочакван проблем по време на отказ или дори да разберете дали нещо се обърка след него. Например, трябва да наблюдавате дали приложението ви има достъп до новия ви главен файл, като проверите броя на активните връзки.
Ключови показатели за наблюдение
Нека видим някои от най-важните показатели, които трябва да вземете предвид:
- Закъснение при репликация
- Състояние на репликация
- Брой връзки
- Използване/грешки на мрежата
- Натоварване на сървъра (CPU, памет, диск)
- База данни и системни регистрационни файлове
Отмяна
Разбира се, ако нещо се обърка, трябва да можете да връщате назад. Блокирането на трафика към стария възел и поддържането му възможно най-изолирано може да бъде добра стратегия за това, така че в случай, че трябва да връщате назад, старият възел ще бъде наличен. Ако връщането е след няколко минути, в зависимост от трафика, вероятно ще трябва да вмъкнете данните за тези минути в стария главен възел, така че се уверете, че имате наличен и изолиран вашият временен главен възел, за да вземете тази информация и да я приложите обратно .
Автоматизиране на процеса на отказ с ClusterControl
Виждайки всички тези необходими задачи за извършване на отказ, най-вероятно искате да го автоматизирате и да избегнете цялата тази ръчна работа. За целта можете да се възползвате от някои от функциите, които ClusterControl може да ви предложи за различни технологии за бази данни, като автоматично възстановяване, архивиране, управление на потребителите, наблюдение, наред с други функции, всички от една и съща система.
С ClusterControl можете да проверите състоянието на репликация и неговото изоставане, да създавате или променяте идентификационни данни, да знаете състоянието на мрежата и хоста и дори повече проверки.
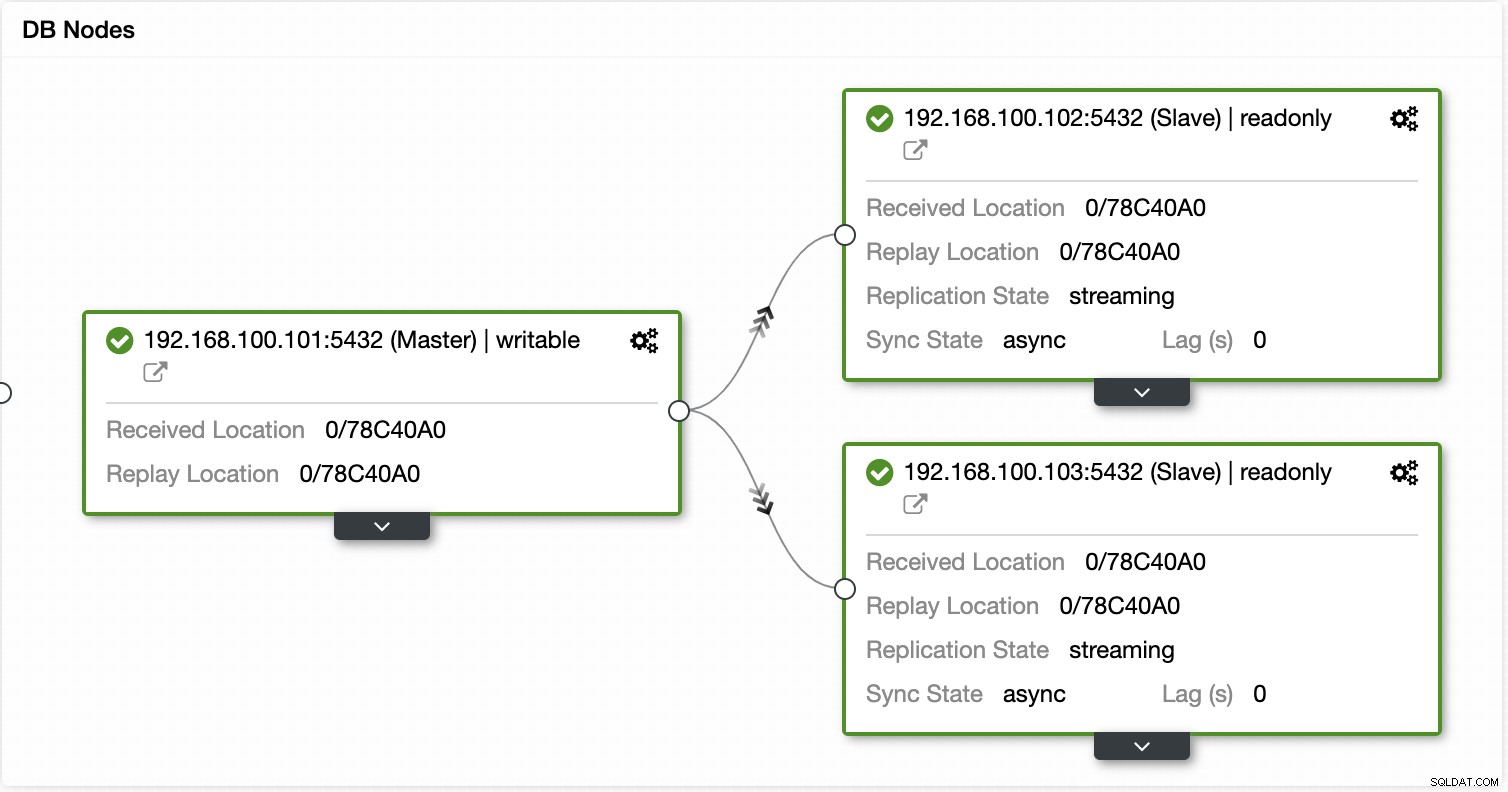
С помощта на ClusterControl можете също да извършвате различни действия за клъстери и възли, като популяризиране на подчинен , рестартирайте базата данни и сървъра, добавяйте или премахвайте възли на базата данни, добавяйте или премахвайте възли за балансиране на натоварването, изграждайте отново подчинен елемент за репликация и др.
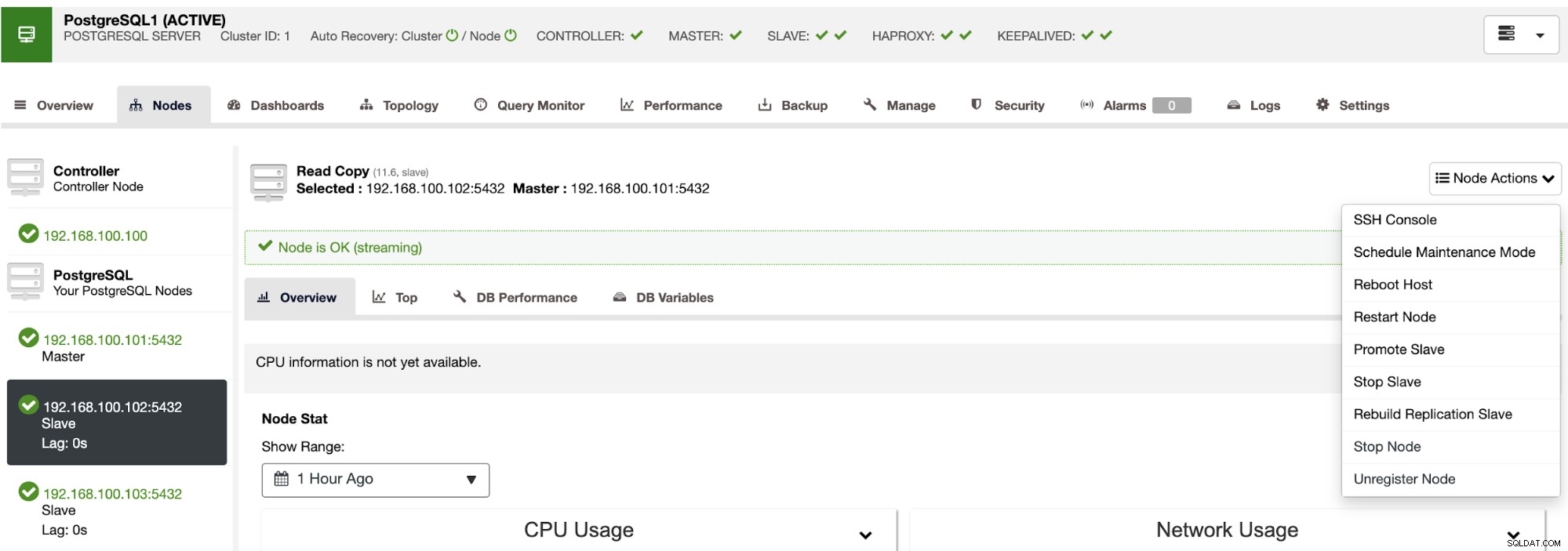
С помощта на тези действия можете също да отмените възстановяването на срива, ако е необходимо, чрез повторно изграждане и популяризиране предишния господар.
ClusterControl има услуги за наблюдение и предупреждение, които ви помагат да разберете какво се случва или дори ако нещо се е случило преди.
Можете също да използвате секцията за табло, за да имате по-удобен за потребителя изглед относно състоянието на вашите системи.
Заключение
В случай на повреда на главната база данни, ще искате да разполагате с цялата информация, за да предприемете необходимите действия възможно най-скоро. Наличието на добър DRP е ключът към поддържането на вашата система да работи през цялото време (или почти през цялото време). Този DRP трябва да включва добре документиран процес на отказ, за да има приемливо RTO (Цел за време за възстановяване) за компанията.