Индексите на SQL Server се използват, за да помогнат за по-бързото извличане на данни и за намаляване на тесните места, засягащи критичните ресурси. Индексите в таблица на база данни служат като техника за оптимизиране на производителността. Може да се чудите – как индексите повишават ефективността на заявката? Има ли такива неща като добри и лоши индекси? Да предположим, че имате таблица с 50 колони, добра идея ли е да създадете индекси за всяка от колоните? Ако създадем множество индекси, това помага ли на SQL заявките да работят по-бързо?
Всички страхотни въпроси, но преди да се потопим, е важно да разберем защо може да се изискват индекси на първо място.
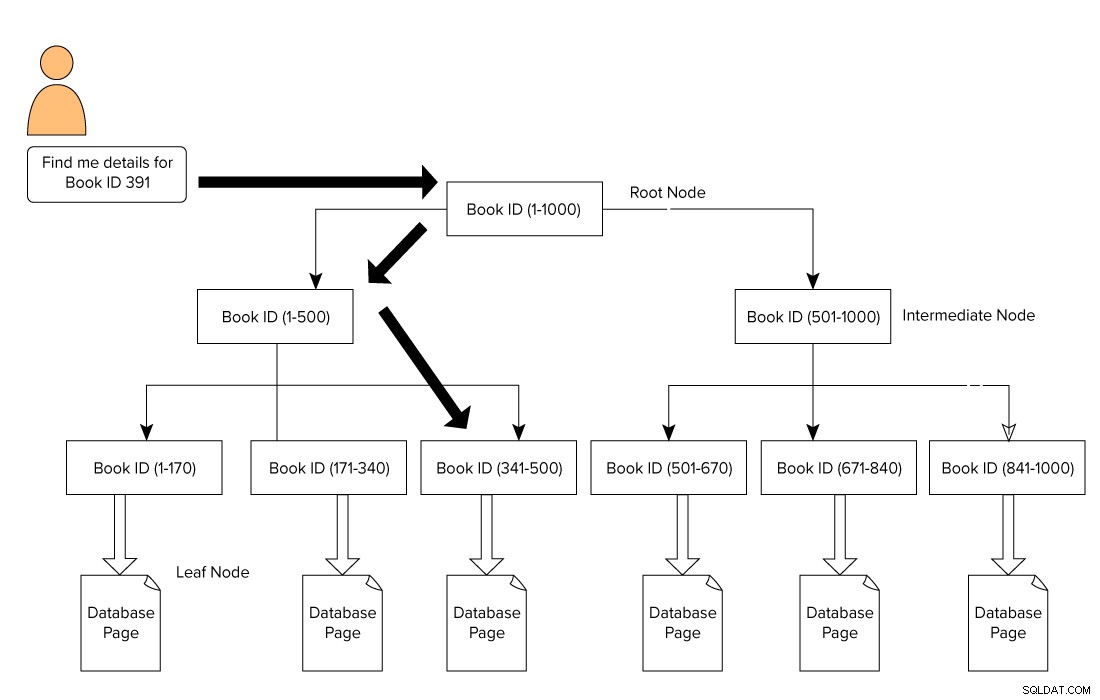
Представете си, че посещавате градска библиотека, която има колекция от хиляди книги. Търсите конкретна книга, но как ще я намерите? Ако прегледате всяка книга, във всяка поставка, може да отнеме дни, за да я намерите. Същото важи и за база данни, когато търсите запис от милионите редове, съхранени в таблица.
Индексът на SQL Server е оформен във формат B-Tree, който се състои от основен възел в горната част и листов възел в долната част. За нашия пример с библиотечни книги, потребител подава заявка за търсене на книга с идентификатор 391. В този случай машината за заявки започва да преминава от основния възел и се придвижва до крайния възел.
Корен възел –> Междинен възел –> Листов възел.
Машината за заявки търси референтната страница в междинно ниво. В този пример първият междинен възел се състои от идентификатори на книги от 1-500, а вторият междинен възел се състои от 501-1000.
Въз основа на междинния възел, машината за заявки преминава през B-дървото, за да търси съответния междинен възел и листовия възел. Този листов възел може да се състои от действителни данни или да сочи към действителната страница с данни въз основа на типа на индекса. В изображението по-долу виждаме как да преминем през индекса, за да търсим данни с помощта на индекси на SQL Server. В този случай SQL Server не трябва да минава през всяка страница, да я чете и да търси съдържание на конкретно идентификационен номер на книга.
Влияние на индексите върху производителността на SQL Server
В предишния пример за библиотека разгледахме потенциалните въздействия върху производителността на индекса. Нека разгледаме ефективността на заявката със и без индекс.
Да предположим, че изискваме данни за [SalesOrderID] 56958 от таблицата [SalesOrderDetail_Demo].
ИЗБЕРЕТЕ *
ОТ [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
където SalesOrderID=56958
В тази таблица няма никакви индекси. Таблица без никакви индекси се нарича heap таблица в SQL Server.
Оттук бихте искали да изпълните горния оператор select и да видите действителния план за изпълнение. Тази таблица има 121317 записа в нея. Той извършва сканиране на таблица, което означава, че чете всички редове в таблица, за да намери конкретния [SalesOrderID].
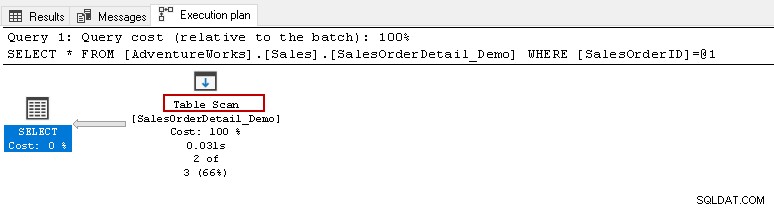
Когато задържите курсора на мишката върху иконата за сканиране на таблица, той показва, че действителният набор от резултати съдържа 2 реда, но за тази цел той чете всички редове в тази таблица.
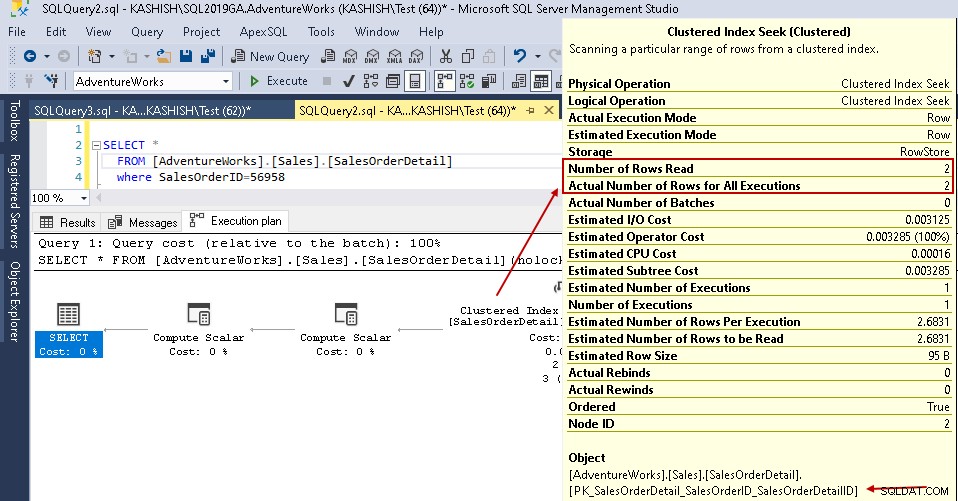
- Брой прочетени редове:121317
- Реалният брой редове за изпълнение:2
Сега помислете за таблица с милиони или милиарди редове. Не е добра практика да преминавате през всички записи в таблицата, за да филтрирате няколко реда. В една обширна система за обработка на онлайн транзакции (OLTP) тя не използва ефективно сървърните ресурси (CPU, IO, памет), поради което потребителят може да се сблъска с проблеми с производителността.
Сега нека изпълним горния оператор select с таблицата с индекси. Тази таблица има клъстериран индекс с първичен ключ и два неклъстерирани индекса в колоните [ProductID] и [rowguid]. По-късно ще говорим за различните типове индекси в SQL Server.
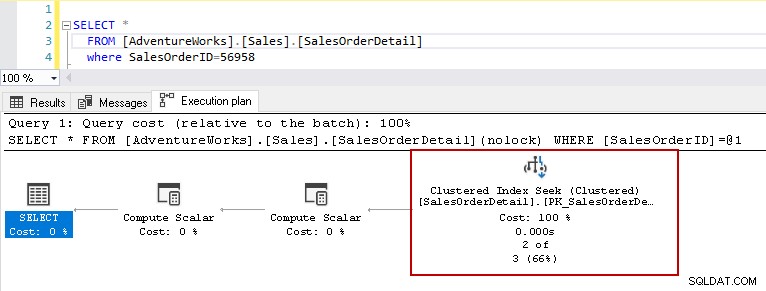
Сега, ако изпълните отново оператора select със същия предикат, планът за изпълнение показва проблема с производителността. Оптимизаторът на заявки решава да използва клъстерно търсене на индекс вместо сканиране на клъстерен индекс.
В подробностите за търсене на клъстериран индекс той показва, че оптимизаторът на заявки е прочел точно редовете, които е дал в изхода.
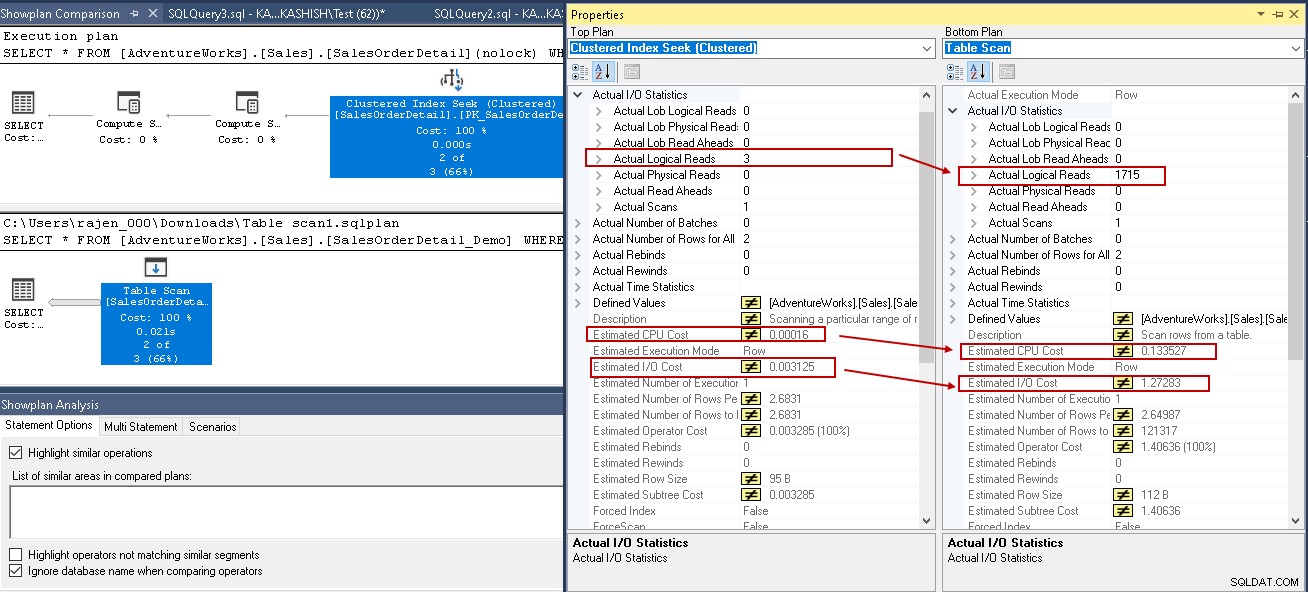
За да ви предоставим сравнителен анализ, нека сравним плана за изпълнение със и без индекс на SQL Server. Можете да се обърнете към статията на SQL Shack Как да сравните плановете за изпълнение на заявки в SQL Server 2016 за допълнителна информация.
За този пример вижте маркираните стойности в клъстерното търсене на индекс и сканирането на таблица:
- Логически четения:Двигателят на базата данни на SQL Server чете страница от буферния кеш и предизвиква логическо четене. По-долу виждаме, че логическите показания са намалени от 1715 на 3, след като създадете индекса.
- Прогнозната цена на процесора също пада от 0,133527 на 0,00016
- Прогнозните разходи за IO намаляват от 1,27283 на 0,003125
Изображението по-долу показва разликата между сканиране на таблица и търсене на индекс.
Добри (полезни) индекси и лоши индекси в SQL Server
Както подсказва името, добрият индекс подобрява производителността на заявката и свежда до минимум използването на ресурсите. Може ли един индекс да намали производителността на заявките в SQL Server? Понякога създаваме индекса върху конкретна колона, но той никога не се използва. Да предположим, че имате индекс на колона и извършвате много вмъквания и актуализации за тази колона. За всяка актуализация се изисква и съответната актуализация на индекса. Ако работното ви натоварване има повече активност при запис и имате много индекси в колона, това би забавило цялостната производителност на вашите заявки. Неизползваният индекс може също да причини бавна производителност и за избрани изрази. Оптимизаторът на заявки използва статистически данни, за да изгради план за изпълнение. Той чете всички индекси и техните извадки от данни и въз основа на това изгражда оптимизиран план за изпълнение на заявка. Можете да проследявате използването на индекса си с помощта на динамичния изглед за управление sys.dm_db_index_usage_stats и да наблюдавате ресурсите, като сканиране на потребителя, търсене на потребителя и търсене на потребители.
Типове и съображения на индекси на SQL Server
SQL Server има два основни индекса – клъстерни и неклъстерни индекси. Клъстерираният индекс съхранява действителните данни в крайния възел на индекса. Той физически сортира данните в страниците с данни въз основа на клъстерния индексен ключ. SQL Server позволява един клъстериран индекс на таблица. Можете да присъедините няколко колони, за да създадете клъстериран индексен ключ. Неклъстерираният индекс е логически индекс и има колоната с ключ на индекса, която сочи към клъстерирания индексен ключ.
Можем да имаме и други индекси в SQL Server, като например XML индекс, индекс на хранилището на колони, пространствен индекс, индекс на пълен текст, хеш индекс и т.н.
Трябва да имате предвид следните точки, преди да създадете индекс в SQL Server:
- Работно натоварване
- Колоната, за която се изисква индексът
- Размер на таблицата
- Възходящ или низходящ ред на данните в колоните
- Последователност на колони
- Тип индекс
- Коефициент на запълване, индекс на поле и ред на сортиране TempDB
Предимства, последици и препоръки за индекс на SQL Server
Индексите в база данни могат да бъдат нож с две остриета. Полезният индекс на SQL Server подобрява заявката и производителността на системата, без да влияе на другите заявки. От друга страна, ако създадете индекс без никаква подготовка или обмисляне, това може да доведе до влошаване на производителността, бавно извличане на данни и може да изразходва по-критични ресурси като CPU, IO и памет. Индексите също увеличават задачите ви за поддръжка на база данни. Като се имат предвид тези фактори, винаги е най-добре да тествате подходящ индекс в предпроизводствена среда с еквивалентно на продукцията работно натоварване, след което да анализирате производителността и да решите дали е най-добре да го приложите в производствена база данни. Има още много препоръки, които трябва да вземете предвид, вижте моите най-добри 11 най-добри практики за индексиране за допълнителна информация.