IGNORE_DUP_KEY опцията за уникални индекси указва как SQL Server отговаря на опит за INSERT дублиращи се стойности:Прилага се само за таблици (не изгледи) и само за вмъквания. Всяка част за вмъкване на MERGE оператор игнорира всеки IGNORE_DUP_KEY настройка на индекса.
Когато IGNORE_DUP_KEY е OFF , първият открит дубликат води догрешка и нито един от новите редове не се вмъква.
Когато IGNORE_DUP_KEY е ON , вмъкнатите редове, които биха нарушили уникалността, се отхвърлят. Останалите редове са вмъкнати успешно. Предупреждение вместо грешка се излъчва съобщение:
Резюме на статията
IGNORE_DUP_KEY опцията index може да бъде зададена както за клъстерирани, така и за неклъстерирани уникални индекси. Използването му върху клъстериран индекс може да доведе до много по-лоша производителност отколкото за неклъстериран уникален индекс.
Размерът на разликата в производителността зависи от това колко нарушения на уникалността са открити по време на INSERT операция. Колкото повече нарушения, толкова по-лошо се представя клъстерираният уникален индекс в сравнение. Ако изобщо няма нарушения, вмъкването на клъстерен индекс може дори да работи по-добре.
Групирани вмъквания на уникален индекс
За клъстериран уникален индекс с IGNORE_DUP_KEY набор, дубликатите се обработват отдвижката за съхранение .
Голяма част от работата, свързана с вмъкването на всеки ред, се извършва преди да бъде открит дубликатът. Например, вмъкване на клъстериран индекс операторът навигира надолу по клъстерираното индексно b-дърво до точката, където ще отиде новият ред, като взема ключалките на страниците и обичайната йерархия на заключване, преди да открие дублиращия се ключ.
При откриване на дублиращото се ключово условие, грешка е повдигнат. Вместо да се отмени изпълнението и да се върне грешката на клиента, грешката се обработва вътрешно. Проблемният ред не се вмъква и изпълнението продължава, като се търси следващият ред за вмъкване. Ако този ред срещне дублиран ключ, се повдига и обработва друга грешка и т.н.
Изключенията са много скъпи за хвърляне и улавяне. Значителен брой дубликати ще забавят изпълнението много забележимо.
Неклъстерни вмъквания на уникален индекс
За неклъстериран уникален индекс с IGNORE_DUP_KEY набор, дубликатите се обработват от процесора на заявки . Откриват се дубликати и се излъчва предупреждение преди всяко вмъкване.
Процесорът на заявки премахва дубликати от потока за вмъкване, като гарантира, че не се виждат дубликати от механизма за съхранение. В резултат на това не се повдигат уникални грешки при нарушение на ключовете или не се обработват вътрешно.
Компенсацията
Има компромис между разходите за откриване и премахване на дублирани ключове в плана за изпълнение, спрямо разходите за извършване на значителна работа, свързана с вмъкване, и хвърляне и улавяне на грешки, когато бъде намерен дубликат.
Ако се очаква дубликатите да са много редки , решението на механизма за съхранение (клъстериран индекс) може да бъде по-ефективно. Когато дубликатите са по-малко редки, подходът на процесора на заявки вероятно ще изплати дивиденти. Точната точка на пресичане ще зависи от фактори като ефективността по време на изпълнение на компонентите на плана за изпълнение, използвани за откриване и премахване на дубликати.
Останалата част от тази статия предоставя демонстрация и разглежда по-подробно защо подходът на механизма за съхранение може да се представи толкова лошо.
Демо
Следният скрипт създава временна таблица с милион реда. Той има 1000 уникални стойности и 1000 реда за всяка уникална стойност. Този набор от данни ще се използва като източник на данни за вмъквания в таблици с различни конфигурации на индекси.
ПРОСТЪПНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА #Data;GOCREATE TABLE #Data (c1 integer NOT NULL);GOSET NOCOUNT ON;SET STATISTICS XML OFF; ДЕКЛАРИРАНЕ @Loop цяло число =1, @N цяло число =1; ДОКАТО @N <=1000НАЧАЛО ЗАДАВАНЕ @Loop =1; ЗАПОЧНЕТЕ ТРАНЗАКЦИЯ; -- Добавете 1000 копия на текущата стойност на цикъла ДОКАТО @Loop <=50 BEGIN INSERT #Data (c1) VALUES (@N), (@N), (@N), (@N), (@N), ( @N), (@N), (@N), (@N), (@N), (@N), (@N), (@N), (@N), (@N), ( @N), (@N), (@N), (@N), (@N); SET @Loop +=1; КРАЙ; ИЗВЪРШВАНЕ НА ТРАНЗАКЦИЯ; SET @N +=1;КРАЙ; СЪЗДАЙТЕ КЛУСТРИРАН ИНДЕКС cx НА #Data (c1) С (MAXDOP =1);
Основна линия
Следното вмъкване в променлива на таблица с неуникален клъстериран индекс отнема около 900 мс :
DECLARE @T таблица ( c1 цяло число НЕ НУЛЕН ИНДЕКС cuq КЛУСТРИРАН (c1)); INSERT @T (c1) ИЗБЕРЕТЕ D.c1 ОТ #Data AS D;
Обърнете внимание на липсата на IGNORE_DUP_KEY върху променливата на целевата таблица.
Клъстериран уникален индекс
Вмъкване на същите данни в уникален клъстер индекс с IGNORE_DUP_KEY задайте ON отнема около 15 900 мс — почти 18 пъти по-лошо:
ДЕКЛАРИРАНЕ @T таблица ( c1 цяло число НЕ НУЛИ УНИКАЛНО КЛУСТРИРАНО С (IGNORE_DUP_KEY =ON)); INSERT @T (c1) ИЗБЕРЕТЕ D.c1 ОТ #Data AS D;
Неклъстериран уникален индекс
Вмъкване на данните в уникален неклъстер индекс с IGNORE_DUP_KEY задайте ON отнема около 700 мс :
DECLARE @T таблица ( c1 цяло число НЕ NULL УНИКАЛНО НЕ КЛУСТРИРАНО С (IGNORE_DUP_KEY =ON)); INSERT @T (c1) ИЗБЕРЕТЕ D.c1 ОТ #Data AS D;
Резюме на производителността
Основният тест отнема 900 мс за да вмъкнете всичките един милион реда. Тестът за неклъстериран индекс отнема 700 мс за да вмъкнете само 1000 различни ключа. Тестът на клъстерирания индекс отнема 15 900 мс за да вмъкнете същите 1000 уникални реда.
Този тест е умишлено настроен, за да подчертае лошата производителност на внедряването на механизма за съхранение, като генерира 999 единици пропиляна работа (ключалки, ключалки, обработка на грешки) за всеки успешен ред.
Предвиденото съобщение не е това IGNORE_DUP_KEY винаги ще се представя лошо при клъстерирани индекси, само че може и може да има голяма разлика между клъстерирани и неклъстерирани индекси.
План за изпълнение на клъстерен индекс
В плана за вмъкване на клъстериран индекс не може да се види много:
Има 1 000 000 реда, които се предават към Вмъкване на клъстериран индекс оператор, който се показва като „връщащи“ 1000 реда. Ако се поразровим в детайлите на плана, можем да видим:
- 1 244 008 логически четения на оператора за вмъкване.
- Огромната част от времето за изпълнение се изразходва в Insert оператор.
- 11 мс от
SOS_SCHEDULER_YIELDчака (т.е. няма други чакания).
Нищо, което наистина обяснява 15 900 ms от изминалото време.
Защо производителността е толкова слаба
Очевидно е, че този план ще трябва да свърши много работа за всеки ред:
- Навигирайте по нивата на клъстерирания индекс b-дърво, заключвайки и заключвайки, докато върви, за да намерите точката на вмъкване за новия запис.
- Ако някоя от необходимите индексни страници не е в паметта, те ще трябва да бъдат извлечени от диска.
- Създайте нов ред с b-дърво в паметта.
- Подгответе регистрационни записи.
- Ако бъде намерен дубликат на ключ (който не е призрачен запис), повдигнете грешка, обработвайте тази грешка вътрешно, освободете текущия ред и продължете в подходяща точка от кода, за да обработите следващия кандидат ред.
Всичко това е доста работа и не забравяйте, че всичко се случва за всеки ред .
Частта, върху която искам да се съсредоточа, е издигането и обработката на грешки, защото е изключително скъпо. Останалите аспекти, отбелязани по-горе, вече бяха направени възможно най-евтини чрез използване на променлива на таблица и временна таблица в демонстрацията.
Изключения
Първото нещо, което искам да направя, е да покажа, че Clustered Insert Insert операторът наистина повдига изключение, когато срещне дублиран ключ.
Един от начините да покажете това директно е чрез прикачване на дебъгер и заснемане на проследяване на стека в точката, в която се хвърля изключението:
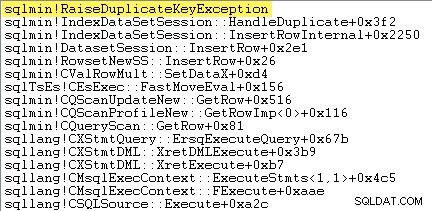
Важното тук е, че хвърлянето и улавянето на изключения е много скъпо.
Мониторингът на SQL Server с помощта на Windows Performance Recorder по време на изпълнение на теста и анализирането на резултатите в Windows Performance Analyzer показва:
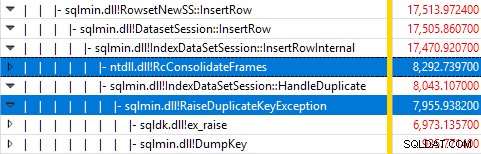
Почти цялото време за изпълнение на заявката се изразходва в sqlmin!IndexDataSetSession::InsertRowInternal както би се очаквало за заявка, която не прави нищо друго освен вмъкване на редове.
Изненадата е, че 45% от това време се изразходва за набиране на изключения чрез sqlmin!RaiseDuplicateKeyException и още 47% се изразходват в свързания блок за улавяне на изключения (ntdll!RcConsolidateFrames йерархия).
За да обобщим:Повишаването и улавянето на изключения представлява 92% от времето за изпълнение на нашата тестова заявка за вмъкване на клъстериран индекс.
Проблеми със събирането на данни
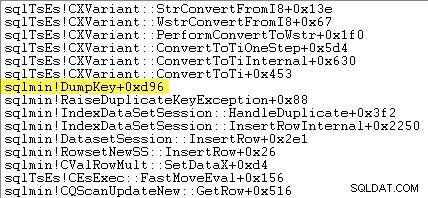
Читателите с остри очи може да забележат значително количество – около 12% – време за изключение, прекарано в sqlmin!DumpKey в графиката на Windows Performance Analyzer. Това си струва да се проучи бързо, заедно с няколко свързани елемента.
Като част от издигането на изключение, SQL Server трябва да събере някои данни, които са налични само в момента на възникване на грешката. Номерът на грешката, свързан с изключение на дублиран ключ, е 2627. Текстът на съобщението в sys.messages за тази грешка номерът е:
Информацията за попълване на тези маркери за място трябва да се събере в момента на възникване на грешката — тя няма да бъде достъпна по-късно! Това означава търсене и форматиране на типа на ограничението, неговото име, пълното име на целевия обект и конкретната стойност на ключа. Всичко това отнема време.
Следната проследяване на стека показва сървърът, който форматира дублираната стойност на ключа като Unicode низ по време на DumpKey обадете се:
Обработката на изключения също включва заснемане на стекова проследяване:
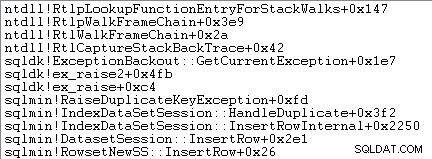
SQL Server също така записва информация за изключения (включително стекови рамки) в малък пръстен буфер, както показва следното:
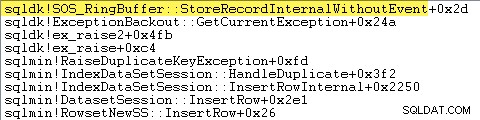
Можете да видите тези записи за пръстен буфер, като използвате команда като:
SELECT TOP (10) date_time =DATEADD ( MILLISECOND, DORB.[timestamp] - DOSI.ms_ticks, SYSDATETIME() ), record =CONVERT(xml, DORB.record)FROM sys.dm_os_ring_buffers КАТО DORBCROSS JOOS_sys.dinfo AS_ DOSIWHERE DORB.ring_buffer_type =N'RING_BUFFER_EXCEPTION'ПОРЪЧКА ПО DORB.[timestamp] DESC;
Следва пример за xml запис за изключение на дублиран ключ. Обърнете внимание на стека рамки:
2627 14 State>10 0 0X00007FFAC659E80A 0X00007FFACBAC0EFD 0X00007FFACBAA1252 0X00007FFACBA9E040 0X00007FFACAB55>0X00007FFACAB55>D 5">0X00007FFACAB55C06 0X00007FFACB3E3D0B 0X00007FFAC92020EC 0X0000B2FAme>0X0000B2FAme> ="9">0X00007FFACABA3B9B 0X00007FFACAB3D89F 0X00007FFAC6A9D108 0XFAC0AB>0XFAC0AB> frame id="13">0X00007FFAC6AB296F 0X00007FFAC6A9B7D0 0X00007FFAC6A9B233 Цялата тази фонова работа се случва за всяко изключение. В нашия тест това означава, че се случва 999 000 пъти — веднъж за всеки ред, който срещне дублирано нарушение на ключ.
Има много начини да видите това, например като стартирате проследяване на Profiler с помощта на Изключение събитие в Грешки и предупреждения клас. В нашия тестов случай това ще в крайна сметка произведете 999 000 реда с TextData елементи като този:
Нарушение на ограничението UNIQUE KEY 'UQ__#AC166DE__3213663B8B6E2E0E'
Не може да се вмъкне дублиран ключ в обект 'dbo.@T'.
Стойността на дублирания ключ е (173).Прикачването на Profiler означава, че всяко събитие за обработка на изключения придобива много допълнителни разходи, тъй като необходимите допълнителни данни се събират и форматират. Данните по подразбиране, споменати по-горе, винаги се събират, дори ако никой не използва активно информацията.
За да бъде ясно:Данните за ефективността, докладвани в тази статия, са получени без прикачен дебъгер и без друго активно наблюдение.
План за изпълнение на неклъстериран индекс
Въпреки че е много по-бърз, планът за вмъкване на неклъстериран индекс е доста по-сложен, така че ще го разделя на две части.
Общата тема е, че този план е по-бърз, защото елиминира дублирания преди опитвайки се да ги вмъкнете в целевата таблица.
Част 1
Първо, дясната страна на неклъстерирания индексен план:
Тази част от плана отхвърля всички редове, които имат ключово съвпадение в целевата таблица за уникалния индекс с
IGNORE_DUP_KEYзадайтеON.Може да очаквате да видите Anti Semi Join тук, но SQL Server няма необходимата инфраструктура за излъчване на необходимото предупреждение за дублиран ключ с Anti Semi Join оператор. (Ако това вече няма смисъл, трябва скоро.)
Вместо това получаваме план с редица интересни функции:
- Клъстерното сканиране на индекс е
Ordered:Trueза да предоставите вход за Обединяване на ляво полуприсъединяване сортирани по колонаc1в#Dataмаса. - Индексното сканиране на променливата на таблицата е
Ordered:False - Сортирането подрежда редове по колона
c1в променливата на таблицата. Тази поръчка може да бъде предоставена от поръчан сканиране на индекса на променливата на таблицата наc1, но оптимизаторът решава Сортиране е най-евтиният начин да осигурите необходимото ниво на защита за Хелоуин. - Променливата на таблицата Сканиране на индекса има вътрешен
UPDLOCKиSERIALIZABLEприлагани съвети за осигуряване на стабилност на целта по време на изпълнение на плана. - Обединяване на ляво полуприсъединяване проверява за съвпадения в променливата на таблицата за всяка стойност на
c1върнати от#Dataмаса. За разлика от обикновеното полу присъединяване, той излъчва всеки ред, получен на горния му вход. Той задава флаг в колона на сонда за да посочите дали текущият ред е намерил съвпадение или не. Колоната на сондата се излъчва от Merge Left Semi Join като израз с имеExpr1012. - Твърждение оператор проверява стойността на колоната на сондата
Expr1012. Първият път, когато види ред с ненулева стойност на пробна колона (което показва, че е намерено съвпадение на индексен ключ), той излъчва „Дублиращият ключ беше игнориран“ съобщение. - Твърждение минава само на редове, където колоната на сондата е нула. Това елиминира входящите редове, които биха довели до грешка с дублиран ключ.
Всичко това може да изглежда сложно, но по същество е толкова просто като задаване на флаг, ако бъде намерено съвпадение, излъчване на предупреждение при първия път, когато флагът е зададен, и само предаване на редове към вмъкването, които все още не съществуват в целевата таблица .
Част 2
Втората част на плана следва Подтверди оператор:
Предишната част на плана премахна редове, които имат съвпадение в целевата таблица. Тази част от планапремахва дубликатите в набора за вмъкване .
Например, представете си, че няма редове в целевата таблица, където c1 = 1 . Все пак може да причиним грешка с дублиран ключ, ако се опитаме да вмъкнем два реда с c1 = 1 от таблицата на източника. Трябва да избягваме това, за да спазваме семантиката на IGNORE_DUP_KEY = ON .
Този аспект се обработва от Сегмент и Отгоре оператори.
Сегментът оператор задава нов флаг (с етикет Segment1015 ), когато срещне ред с нова стойност за c1 . Тъй като редовете са представени в c1 поръчка (благодарение на запазващия ред Merge ), планът може да разчита на всички редове със същия c1 стойност, пристигаща в непрекъснат поток.
Върхът операторът предава един ред за всяка група дубликати, както е посочено от Сегмент флаг. Ако Най операторът среща повече от един ред за един и същ Сегмент група (c1 стойност), излъчва „Дублиращият ключ беше игнориран“ предупреждение, ако това е първият път, когато планът се сблъсква с това условие.
Нетният ефект от всичко това е, че само един ред се предава на операторите за вмъкване за всяка уникална стойност на c1 и се генерира предупреждение, ако е необходимо.
Планът за изпълнение вече елиминира всички потенциални дублирани ключови нарушения, така че оставащото Вмъкване на таблица и Вмъкване на индекс операторите могат безопасно да вмъкват редове в купчината и неклъстерирания индекс, без да се страхуват от грешка с дублиран ключ.
Не забравяйте, че UPDLOCK и SERIALIZABLE подсказките, приложени към целевата таблица, гарантират, че наборът не може да се промени по време на изпълнение. С други думи, едновременен израз не може да промени целевата таблица, така че да възникне грешка с дублиран ключ при Insert оператори. Това не е проблем тук, тъй като използваме променлива за частна таблица, но SQL Server все пак добавя намеци като обща мярка за безопасност.
Без тези намеци, едновременен процес би могъл да добави ред към целевата таблица, който би генерирал дублирано ключово нарушение, въпреки проверките, направени от част 1 от плана. SQL Server трябва да е сигурен, че резултатите от проверката за съществуване остават валидни.
Любопитният читател може да види някои от функциите, описани по-горе, като активира флагове за проследяване 3604 и 8607, за да види дървото на изхода на оптимизатора:
PhyOp_RestrRemap PhyOp_StreamUpdate(INS TBL:@T, iid 0x2 като IDX, Сортиране(QCOL:.c1, )), { - COL:Bmk10001013 =COL:Bmk1000 - COL:QCte1:PhysOp. :@T, iid 0x0 като TBLInsLocator(COL:Bmk1000) REPORT-COUNT), { - QCOL:.c1=QCOL:[D].c1} PhyOp_GbTop Group(QCOL:[D].c1,) WARN-DUP PhyOp_StreamCheck WarnIgnoreDuplicate TABLE) PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL:Expr1012 ( QCOL:[D].c1) =( QCOL:.c1) PhyOp_Range TBL:#Data(псевдоним TBL:D)(1) ASC Phy. c1 PhyOp_Range TBL:@T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX ) ScaOp_Comp x_cmpIs ScaOp_Identifier QCOL:[D].c1 ScaOp_Identifier QCOL:.c1 ScaOp_Identifier QCOL:.c1 ScaOp_Identifier QCOL:.c1 ScaOp_Identifier COL:.c1 ScaOp_Idenfical xN_lop_IcapI xpr1012 Последни мисли
IGNORE_DUP_KEY опцията за индекс не е нещо, което повечето хора ще използват много често. Все пак е интересно да разгледаме как се реализира тази функционалност и защо може да има големи разлики в производителността между IGNORE_DUP_KEY върху клъстерирани и неклъстерни индекси.
В много случаи ще си струва да следвате примера на процесора на заявки и да гледате да пишете заявки, които елиминират изрично дубликати, вместо да разчитате на IGNORE_DUP_KEY . В нашия пример това би означавало да напишете:
DECLARE @T таблица ( c1 цяло число НЕ NULL УНИКАЛНО КЛУСТРИРАНО -- няма IGNORE_DUP_KEY!); INSERT @T (c1) SELECT DISTINCT -- Премахване на дубликати D.c1 ОТ #Data AS D;
Това се изпълнява за около 400 мс , само за протокола.