Percona XtraDB Cluster е много добре известно решение с висока достъпност в света на MySQL. Той е базиран на Galera Cluster и осигурява практически синхронна репликация в множество възли. Както при всяка база данни, от решаващо значение е да следите какво се случва в системата, дали производителността е на очакваните нива и, ако не, какво е пречката. Това е от изключителна важност, за да можете да реагирате правилно в ситуацията, в която производителността е засегната. Разбира се, Percona XtraDB Cluster идва с множество показатели и не винаги е ясно кои от тях са най-важните за проследяване на състоянието на базата данни. В този блог ще обсъдим няколко от ключовите показатели, които искате да следите, докато работите с PXC.
За да стане ясно, ще се съсредоточим върху показателите, уникални за PXC и Galera, няма да покриваме показатели за MySQL или InnoDB. Тези показатели бяха обсъдени в предишните ни блогове.
Нека да разгледаме някои от най-важната информация, която PXC ни представя.
Контрол на потока
Контролът на потока е почти най-важният показател, който можете да наблюдавате във всеки клъстер Galera, затова нека имаме малко предистория. Galera е многоглавен, практически синхронен клъстер. Възможно е да се изпълняват записи на всеки от възлите на базата данни, които го формират. Всяка запис трябва да бъде изпратена до всички възли в клъстера, за да се гарантира, че може да се приложи - този процес се нарича сертифициране. Никоя транзакция не може да бъде приложена, преди всички възли да се съгласят, че може да бъде ангажирана. Ако някой от възлите има проблеми с производителността, които го правят неспособен да се справи с трафика, той ще започне да издава съобщения за контрол на потока, които имат за цел да информират останалата част от клъстера за проблемите с производителността и да ги помолят да намалят натоварването и да помогнат на забавените възел, за да настигне останалата част от клъстера.
Можете да проследите кога възлите е трябвало да въведат изкуствена пауза, за да позволят на техните изоставащи партньори да настигнат, като използвате метрика на пауза за контрол на потока (wsrep_flow_control_paused):

Можете също да проследите дали възелът изпраща или получава съобщенията за контрол на потока (wsrep_flow_control_recv и wsrep_flow_control_sent).
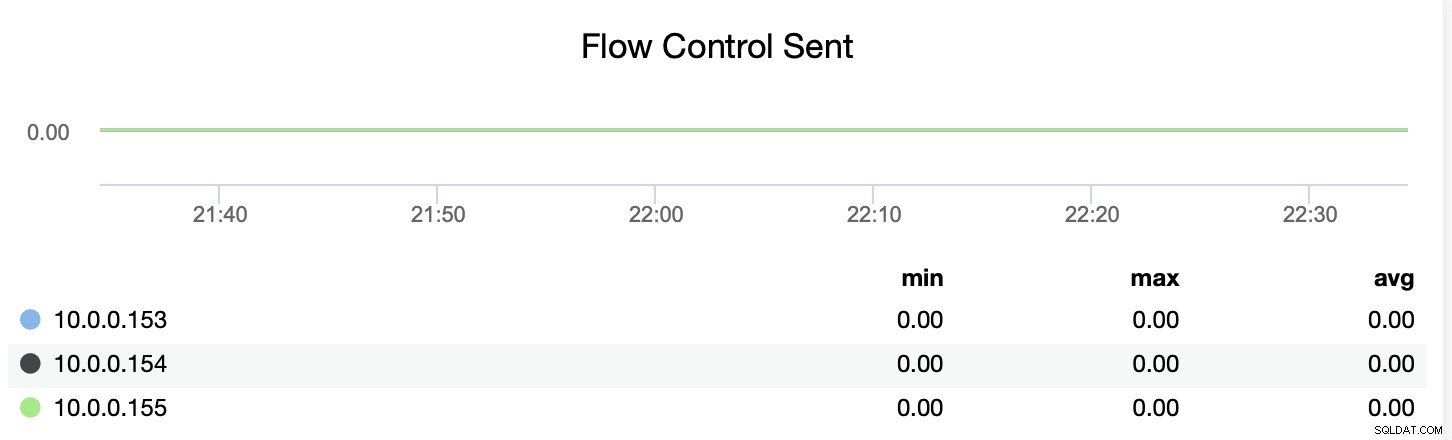
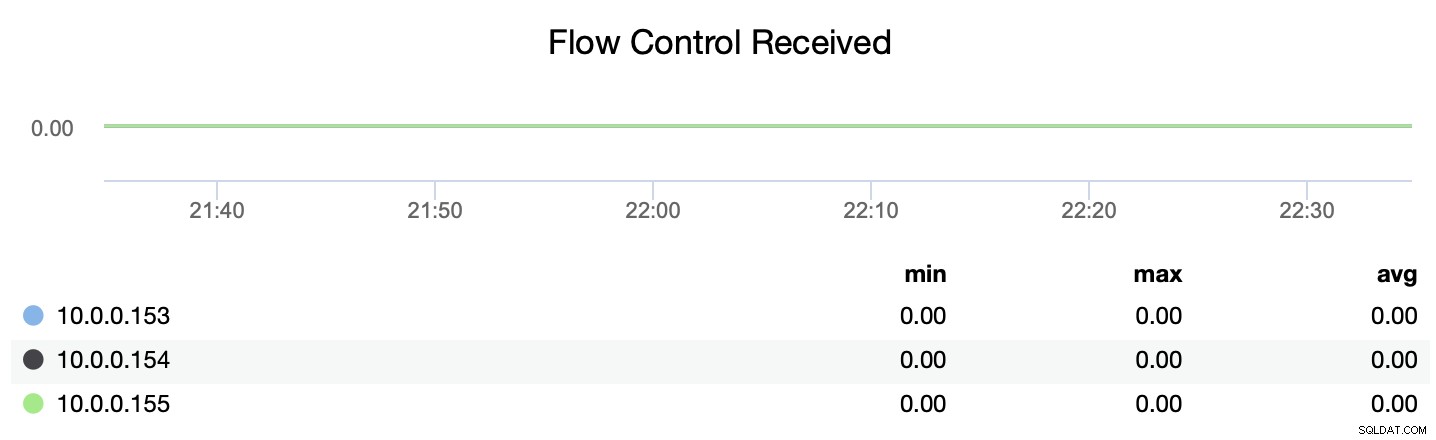
Тази информация ще ви помогне да разберете по-добре кой възел не работи на същия ниво като своите връстници. След това можете да се съсредоточите върху този възел и да се опитате да разберете какъв е проблемът и как да премахнете пречката.
Опашки за изпращане и получаване
Тези показатели са някак свързани с контрола на потока. Както обсъдихме, възелът може да изостава от други възли в клъстера. Това може да бъде причинено от неравномерно разделяне на натоварването или от други причини (някои процеси, работещи във фонов режим, архивиране или някои персонализирани, тежки заявки). Преди да започне контрола на потока, изоставащите възли ще се опитат да съхранят входящите набори за запис в опашката за получаване (wsrep_local_recv_queue), надявайки се, че въздействието върху производителността е преходно и ще може да навакса много скоро. Само ако опашката стане твърде голяма (управлява се от настройката gcs.fc_limit), съобщенията за контрол на потока започват да се изпращат в клъстера.

Можете да мислите за опашка за получаване като ранен маркер, който показва, че има са проблеми с производителността и контролът на потока може да се включи.

От друга страна, опашката за изпращане (wsrep_local_send_queue) ще ви каже, че възелът не може да изпрати наборите за запис до други членове на клъстера, което може да показва проблеми с мрежовата свързаност (натискане на наборите за запис към мрежата не е наистина ресурсоемка).
Показатели за паралелизиране
Клъстерът Percona XtraDB може да бъде конфигуриран да използва множество нишки за прилагане на входящите набори за запис - това му позволява по-добре да обработва множество нишки, свързващи се към клъстера и издаващи записи едновременно. Има два основни показателя, които може да искате да следите.
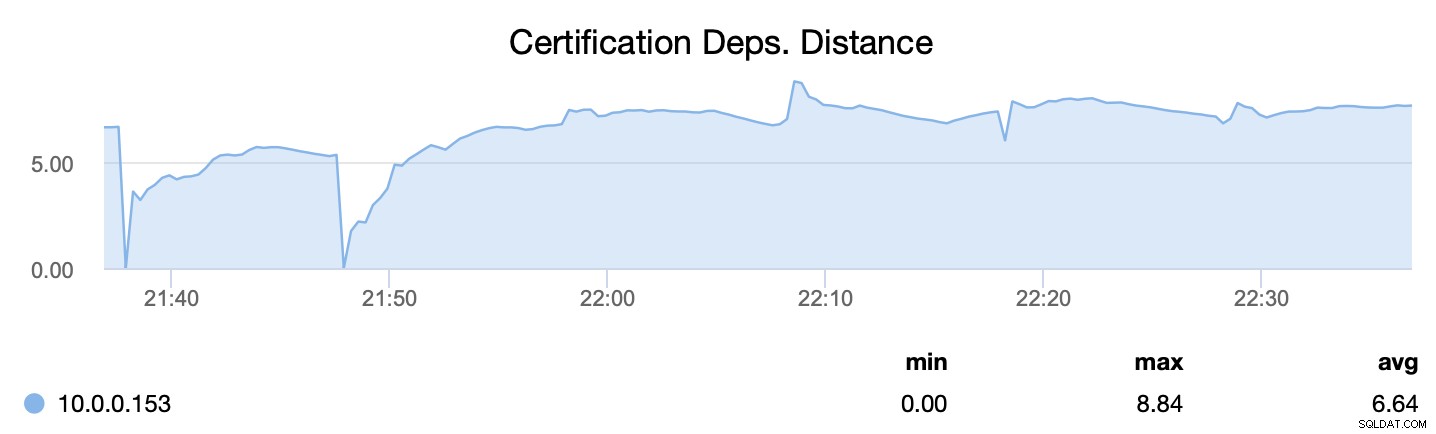
Първо, wsrep_cert_deps_distance, ни казва какъв е потенциалът за паралелизиране - колко набора за запис могат потенциално да бъдат приложени едновременно. Въз основа на тази стойност можете да конфигурирате броя на паралелните подчинени нишки (wsrep_slave_threads), които ще работят при прилагането на входящи набори за запис. Основното правило е, че няма смисъл да конфигурирате повече нишки от стойността на wsrep_cert_deps_distance.
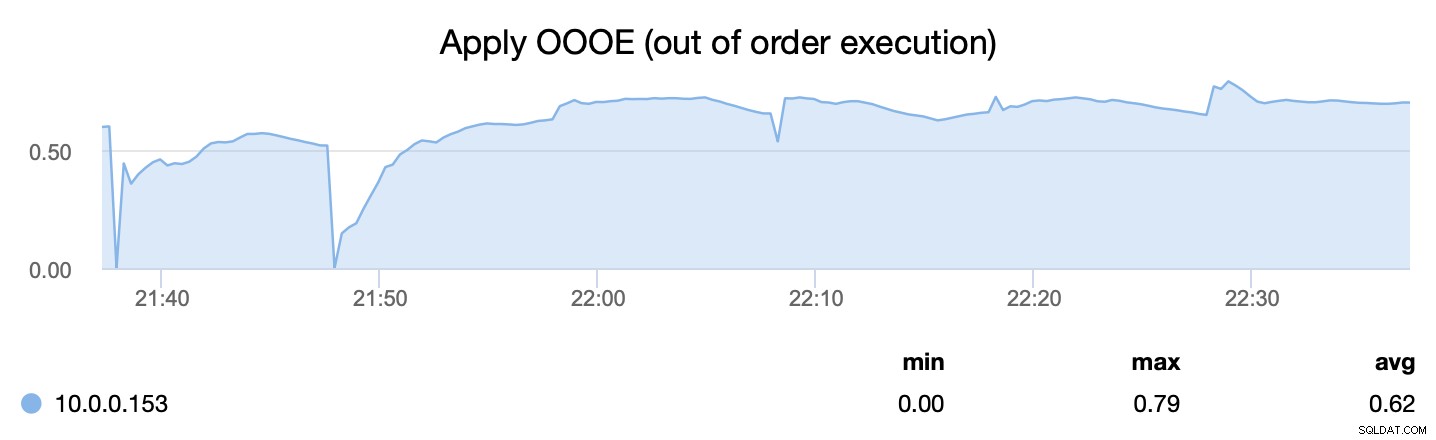
Вторият показател, от друга страна, ни казва колко ефективно успяхме да паралелизираме процеса на прилагане на набори за запис - wsrep_apply_oooe ни казва колко често приложението е започнало да прилага набори за запис извън ред (което сочи към по-добро паралелизиране ).
Заключение
Както можете да видите, има няколко показателя, които си струва да разгледате в Percona XtraDB Cluster. Разбира се, както казахме в началото на този блог, това са показатели, строго свързани с PXC и Galera Cluster като цяло.
Трябва също така да следите обикновените MySQL и InnoDB метрики, за да разберете по-добре състоянието на вашата база данни. И не забравяйте, че можете да наблюдавате тази технология безплатно с помощта на ClusterControl Community Edition.