Тази статия е четвъртата от поредицата за праговете за оптимизация. Серията обхваща групиране и агрегиране на данни, обяснявайки различните алгоритми, които SQL Server може да използва, и модела за изчисляване на разходите, който му помага да избира между алгоритмите. В тази статия се фокусирам върху съображенията за паралелизъм. Обхващам различните стратегии за паралелизъм, които SQL Server може да използва, праговете за избор между сериен и паралелен план и логиката за изчисляване на разходите, която SQL Server прилага, използвайки концепция, наречена степен на паралелизъм за изчисляване на разходите (DOP за изчисляване на разходите).
Ще продължа да използвам таблицата dbo.Orders в примерната база данни на PerformanceV3 в моите примери. Преди да стартирате примерите в тази статия, изпълнете следния код, за да премахнете няколко ненужни индекса:
ОТПУСКАНЕ ИНДЕКСА, АКО СЪЩЕСТВУВА idx_nc_sid_od_cid В dbo.Orders; ИЗПУСКАНЕ НА ИНДЕКС, АКО СЪЩЕСТВУВА idx_unc_od_oid_i_cid_eid В dbo.Orders;
Единствените два индекса, които трябва да бъдат оставени в тази таблица, са idx_cl_od (клъстериран с orderdate като ключ) и PK_Orders (неклъстериран с orderid като ключ).
Стратегии за паралелизъм
Освен че трябва да избира между различни стратегии за групиране и агрегиране (предварително поръчан Stream Aggregate, Sort + Stream Aggregate, Hash Aggregate), SQL Server също трябва да избере дали да използва сериен или паралелен план. Всъщност той може да избира между множество различни стратегии за паралелизъм. SQL Server използва логика за изчисляване на разходите, която води до прагове за оптимизация, които при различни условия правят една стратегия предпочитана пред другите. Вече обсъдихме задълбочено логиката за изчисляване на разходите, която SQL Server използва в серийните планове в предишните части на поредицата. В този раздел ще представя редица стратегии за паралелизъм, които SQL Server може да използва за обработка на групиране и агрегиране. Първоначално няма да навлизам в подробностите на логиката на разходите, а просто да опиша наличните опции. По-късно в статията ще обясня как работят формулите за изчисляване на разходите и важен фактор в тези формули, наречен DOP за изчисляване на разходите.
Както ще научите по-късно, SQL Server взема предвид броя на логическите процесори в машината в своите формули за изчисляване на разходите за паралелни планове. В моите примери, освен ако не кажа друго, предполагам, че целевата система има 8 логически CPU. Ако искате да изпробвате примерите, които ще предоставя, за да получите същите планове и стойности на разходите като мен, трябва да изпълните кода и на машина с 8 логически процесора. Ако вашата машина има различен брой процесори, можете да емулирате машина с 8 процесора - за целите на разходите - като така:
DBCC OPTIMIZER_WHATIF(CPU, 8);
Въпреки че този инструмент не е официално документиран и поддържан, той е доста удобен за изследователски и учебни цели.
Таблицата „Поръчки“ в нашата примерна база данни има 1 000 000 реда с идентификатори на поръчки в диапазона от 1 до 1 000 000. За да демонстрирам три различни стратегии за паралелизъм за групиране и агрегиране, ще филтрирам поръчки, при които идентификационният номер на поръчката е по-голям или равен на 300 001 (700 000 съвпадения) и ще групирам данните по три различни начина (по custid [20 000 групи преди филтриране], от empid [500 групи] и от shipperid [5 групи]), и изчислете броя на поръчките за група.
Използвайте следния код, за да създадете индекси за поддръжка на групираните заявки:
СЪЗДАВАНЕ НА ИНДЕКС idx_oid_i_eid В dbo.Orders(orderid) INCLUDE(empid);CREATE INDEX idx_oid_i_sid ON dbo.Orders(orderid) INCLUDE(shipperid);CREATE INDEX idx_oid_i_ciders ON dbo. предварително>Следните заявки изпълняват гореспоменатото филтриране и групиране:
-- Запитване 1:Serial SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Заявка 2:Паралелен, а не локален/глобален SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid; -- Заявка 3:Локален паралел глобален паралелен SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Заявка 4:Локален паралелен глобален сериен SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid;Забележете, че заявка 1 и заявка 2 са едни и същи (и двете групи по custid), само че първият налага сериен план, а вторият получава паралелен план на машина с 8 CPU. Използвам тези два примера, за да сравня серийните и паралелните стратегии за една и съща заявка.
Фигура 1 показва прогнозните планове за всичките четири заявки:
Фигура 1:Стратегии за паралелизъм
Засега не се притеснявайте за стойностите на разходите, показани на фигурата, и споменаването на термина DOP за изчисляване на разходите. Ще стигна до тях по-късно. Първо се съсредоточете върху разбирането на стратегиите и разликите между тях.
Стратегията, използвана в серийния план за заявка 1, трябва да ви е позната от предишните части на поредицата. Планът филтрира съответните поръчки с помощта на търсене в покриващия индекс, който сте създали по-рано. След това, с прогнозния брой редове, които трябва да бъдат групирани и обобщени, оптимизаторът предпочита стратегията Hash Aggregate пред стратегията Sort + Stream Aggregate.
Планът за заявка 2 използва проста стратегия за паралелизъм, която използва само един агрегатен оператор. Паралелен оператор Index Seek разпределя пакети от редове към различните нишки по кръговрат. Всеки пакет от редове може да съдържа множество различни идентификатори на клиенти. За да може един агрегатен оператор да изчисли правилния окончателен брой групи, всички редове, които принадлежат към една и съща група, трябва да се обработват от една и съща нишка. Поради тази причина се използва оператор за обмен на паралелизъм (преразпределяне на потоци) за повторно разделяне на потоците от групиращия набор (custid). И накрая, оператор за обмен на паралелизъм (събиране на потоци) се използва за събиране на потоците от множество нишки в един поток от редове с резултати.
Плановете за заявка 3 и заявка 4 използват по-сложна стратегия за паралелизъм. Плановете започват подобно на плана за заявка 2, където паралелен оператор Index Seek разпределя пакети от редове към различни нишки. След това работата по агрегирането се извършва на две стъпки:един агрегатен оператор локално групира и агрегира редовете на текущата нишка (забележете члена на резултата partialagg1004), а вторият агрегатен оператор глобално групира и агрегира резултатите от локалните агрегати (забележете globalagg1005 резултатен член). Всяка от двете обобщени стъпки – локална и глобална – може да използва всеки от обобщените алгоритми, които описах по-рано в поредицата. И двата плана за заявка 3 и заявка 4 започват с локален хеш агрегат и продължават с глобален агрегат за сортиране + поток. Разликата между двете е, че първият използва паралелизъм и в двете стъпки (следователно обмен на Repartition Streams се използва между двете и обмен на Gather Streams след глобалния агрегат), а вторият обработва локалния агрегат в паралелна зона и глобалния агрегат в серийна зона (следователно обменът на събиране на потоци се използва между двете).
Когато правите проучване за оптимизацията на заявки като цяло и конкретно за паралелизма, е добре да сте запознати с инструменти, които ви позволяват да контролирате различни аспекти на оптимизация, за да видите техните ефекти. Вече знаете как да наложите сериен план (с намек MAXDOP 1) и как да емулирате среда, която за целите на изчисляването на разходите има определен брой логически процесори (DBCC OPTIMIZER_WHATIF, с опцията CPU). Друг удобен инструмент е подсказката за заявка ENABLE_PARALLEL_PLAN_PREFERENCE (въведена в SQL Server 2016 SP1 CU2), която максимизира паралелизма. Това, което имам предвид с това, е, че ако се поддържа паралелен план за заявката, паралелизмът ще бъде предпочитан във всички части на плана, които могат да се обработват паралелно, сякаш е безплатен. Например, обърнете внимание на фигура 1, че по подразбиране планът за заявка 4 обработва локалния агрегат в серийна зона и глобалния агрегат в паралелна зона. Ето същата заявка, само че този път с приложен намек за заявка ENABLE_PARALLEL_PLAN_PREFERENCE (ще я наречем заявка 5):
ИЗБЕРЕТЕ shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Планът за заявка 5 е показан на фигура 2:
Фигура 2:Максимизиране на паралелизма
Обърнете внимание, че този път както локалните, така и глобалните агрегати се обработват в паралелни зони.
Избор на сериен/паралелен план
Припомнете си, че по време на оптимизацията на заявки SQL Server създава множество кандидат-планове и избира този с най-ниска цена сред произведените. Терминът разходи е малко погрешно наименование, тъй като се предполага, че кандидат планът с най-ниска цена, според оценките, е този с най-ниско време за изпълнение, а не този с най-ниско количество използвани ресурси като цяло. Например, между сериен кандидат план и паралелен такъв, произведен за една и съща заявка, паралелният план вероятно ще използва повече ресурси, тъй като трябва да използва оператори за обмен, които синхронизират нишките (разпределяне, повторно разделяне и събиране на потоци). Въпреки това, за да може паралелният план да се нуждае от по-малко време за изпълнение от серийния план, икономиите, постигнати чрез извършване на работата с множество нишки, трябва да надвишават допълнителната работа, извършена от операторите на обмен. И това трябва да бъде отразено от формулите за изчисляване на разходите, които SQL Server използва, когато е включен паралелизъм. Не е лесна задача за точно изпълнение!
В допълнение към цената на паралелния план, която трябва да бъде по-ниска от цената на серийния план, за да бъде предпочитана, цената на алтернативата на серийния план трябва да бъде по-голяма или равна на прага на разходите за паралелизъм . Това е опция за конфигурация на сървъра, зададена на 5 по подразбиране, която предотвратява обработката на заявки с доста ниска цена с паралелизъм. Мисленето тук е, че система с голям брой малки заявки като цяло би се възползвала повече от използването на серийни планове, вместо да губи много ресурси за синхронизиране на нишки. Все още можете да имате множество заявки със серийни планове, изпълнявани по едно и също време, като ефективно използвате многопроцесорните ресурси на машината. Всъщност много професионалисти на SQL Server обичат да увеличат прага на разходите за паралелизъм от неговата стойност по подразбиране от 5 до по-висока стойност. Система, изпълняваща едновременно сравнително малък брой големи заявки, би имала много по-голяма полза от използването на паралелни планове.
За да обобщим, за да може SQL Server да предпочете паралелен план пред серийната алтернатива, цената на серийния план трябва да бъде поне прага на разходите за паралелизъм, а цената на паралелния план трябва да бъде по-ниска от цената на серийния план (подразбирайки потенциално по-ниско време за изпълнение).
Преди да стигна до подробностите за действителните формули за изчисляване на разходите, ще илюстрирам с примери различни сценарии, при които се прави избор между сериен и паралелен план. Уверете се, че вашата система предполага 8 логически CPU, за да получите разходи за заявка, подобни на моите, ако искате да изпробвате примерите.
Помислете за следните заявки (ще ги наречем Заявка 6 и Заявка 7):
-- Заявка 6:Serial SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; -- Запитване 7:Принудително паралелен SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Плановете за тези заявки са показани на фигура 3.
Фигура 3:Серийна цена <разходен праг за паралелизъм, паралелна цена <сериен разход
Тук цената на [принудителния] паралелен план е по-ниска от цената на серийния план; обаче цената на серийния план е по-ниска от прага на разходите по подразбиране за паралелизъм от 5, следователно SQL Server е избрал серийния план по подразбиране.
Помислете за следните заявки (ще ги наречем Заявка 8 и Заявка 9):
-- Запитване 8:Parallel SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Запитване 9:Принудително сериен SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empidOPTION(MAXDOP 1);Плановете за тези заявки са показани на Фигура 4.
Фигура 4:Серийна цена>=разходен праг за паралелизъм, паралелна цена <сериен разход
Тук цената на [принудителния] сериен план е по-голяма или равна на прага на разходите за паралелизъм, а цената на паралелния план е по-ниска от цената на серийния план, следователно SQL Server е избрал паралелния план по подразбиране.
Помислете за следните заявки (ще ги наречем заявка 10 и заявка 11):
-- Заявка 10:Serial SELECT *FROM dbo.OrdersWHERE orderid>=100000; -- Запитване 11:Принудително паралелен SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Плановете за тези заявки са показани на Фигура 5.
Фигура 5:Серийна цена>=праг на разходите за паралелизъм, паралелна цена>=сериен разход
Тук цената на серийния план е по-голяма или равна на прага на разходите за паралелизъм; обаче цената на серийния план е по-ниска от цената на [принудителния] паралелен план, поради което SQL Server е избрал серийния план по подразбиране.
Има още нещо, което трябва да знаете за опитите за максимизиране на паралелизма с намека ENABLE_PARALLEL_PLAN_PREFERENCE. За да може SQL Server дори да използва паралелен план, трябва да има някакъв инструмент за паралелизъм като остатъчен предикат, сортиране, агрегат и т.н. План, който прилага само сканиране на индекс или търсене на индекс без остатъчен предикат и без друг активатор за паралелизъм, ще бъде обработен със сериен план. Разгледайте следните заявки като пример (ще ги наречем заявка 12 и заявка 13):
-- Заявка 12 SELECT *FROM dbo.OrdersOPTION(ИЗПОЛЗВАЙТЕ HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- Запитване 13 SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(ИЗПОЛЗВАЙТЕ HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Плановете за тези заявки са показани на фигура 6.
Фигура 6:Активатор на паралелизъм
Заявка 12 получава сериен план въпреки намека, тъй като няма инструмент за паралелизъм. Заявка 13 получава паралелен план, тъй като има остатъчен предикат.
Изчисляване и тестване на DOP за изчисляване на разходите
Microsoft трябваше да калибрира формулите за изчисляване на разходите в опит да има по-ниска цена за паралелен план, отколкото цената на серийния план отразява по-ниско време за изпълнение и обратно. Една потенциална идея беше да се вземе цената на CPU на серийния оператор и просто да се раздели на броя на логическите CPU в машината, за да се получи цената на CPU на паралелния оператор. Логическият брой CPU в машината е основният фактор, определящ степента на паралелизъм на заявката, или накратко DOP (броя на нишките, които могат да се използват в паралелна зона в плана). Опростеното мислене тук е, че ако операторът отнема T времеви единици, за да завърши, когато използва една нишка, и степента на паралелизъм на заявката е D, на оператора ще отнеме време T/D, за да завърши, когато използва D нишки. На практика нещата не са толкова прости. Например, обикновено имате няколко заявки, които се изпълняват едновременно, а не само една, в който случай една заявка няма да получи всички централни ресурси на машината. И така, Microsoft излезе с идеята за степен на паралелизъм за разход (DOP за остойностяване, накратко). Тази мярка обикновено е по-ниска от броя на логическите CPU в машината и е факторът, на който се разделя цената на CPU на серийния оператор, за да се изчисли цената на CPU на паралелния оператор.
Обикновено DOP за изчисляване на разходите се изчислява като броят на логическите процесори, разделен на 2, като се използва целочислено деление. Има обаче изключения. Когато броят на CPU е 2 или 3, DOP за изчисляване на разходите е настроен на 2. При 4 или повече CPU DOP за изчисляване на разходите е настроен на #CPUs / 2, отново, като се използва целочислено деление. Това е до определен максимум, който зависи от количеството памет, налична за машината. В машина с до 4096 MB памет максималният DOP за осчетоводяване е 8; с повече от 4096 MB, максималният DOP за осчетоводяване е 32.
За да тествате тази логика, вече знаете как да емулирате желания брой логически процесори, използвайки DBCC OPTIMIZER_WHATIF, с опцията CPU, както следва:
DBCC OPTIMIZER_WHATIF(CPU, 8);Използвайки същата команда с опцията MemoryMBs, можете да емулирате желано количество памет в MB, както следва:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);Използвайте следния код, за да проверите съществуващото състояние на емулираните опции:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(Състояние); DBCC TRACEOFF(3604);Използвайте следния код, за да нулирате всички опции:
DBCC OPTIMIZER_WHATIF(ResetAll);Ето T-SQL заявка, която можете да използвате за изчисляване на DOP за изчисляване на разходите въз основа на въведен брой логически процесори и количество памет:
ДЕКЛАРИРАНЕ @NumCPUs КАТО INT =8, @MemoryMBs КАТО INT =16384; ИЗБЕРЕТЕ СЛУЧАЙ, КОГАТО @NumCPUs =1 ТОГАВА 1 КОГАТО @NumCPUs <=3 ТОГАВА 2 КОГАТО @NumCPUs>=4 ТОГАВА (ИЗБЕРЕТЕ MIN(n) ОТ ( СТОЙНОСТИ(@NumCPUs / 2), (MaxDOP4C) ) КАТО D2(n)) КРАЙ КАТО DOP4CFROM ( СТОЙНОСТИ ( СЛУЧАЙ, КОГАТО @MemoryMBs <=4096 ТОГАВА 8 ДРУГИ 32 END ) ) КАТО D1(MaxDOP4C);С посочените входни стойности тази заявка връща 4.
Таблица 1 описва DOP за разход, който получавате въз основа на логическия брой процесори и количеството памет във вашата машина.
| #CPUs | DOP за разходи, когато MemoryMBs <=4096 | DOP за разходи, когато MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Таблица 1:DOP за разход
Като пример, нека да разгледаме отново заявка 1 и заявка 2, показани по-рано:
-- Запитване 1:Принудително сериен SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Запитване 2:Естествено паралелно SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid;
Плановете за тези заявки са показани на фигура 7.
 Фигура 7:DOP за разходи
Фигура 7:DOP за разходи
Заявка 1 налага сериен план, докато заявка 2 получава паралелен план в моята среда (емулира 8 логически CPU и 16 384 MB памет). Това означава, че DOP за изчисляване на разходите в моята среда е 4. Както споменахме, цената на CPU на паралелен оператор се изчислява като цената на CPU на серийния оператор, разделена на DOP за изчисляване на разходите. Можете да видите, че това наистина е така в нашия паралелен план с операторите Index Seek и Hash Aggregate, които се изпълняват паралелно.
Що се отнася до разходите на борсовите оператори, те се състоят от начална цена и някаква постоянна цена на ред, която можете лесно да промените обратното инженерство.
Забележете, че в простата стратегия за паралелно групиране и агрегиране, която е използваната тук, оценките за мощност в серийния и паралелния план са еднакви. Това е така, защото е зает само един обобщен оператор. По-късно ще видите, че нещата са различни, когато използвате локална/глобална стратегия.
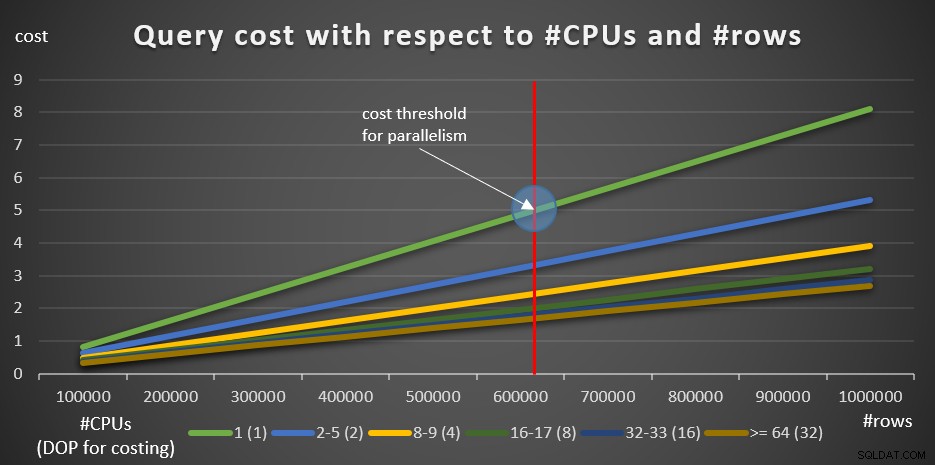
Следните заявки помагат да се илюстрира ефекта от броя на логическите процесори и броя на редовете, включени върху цената на заявката (10 заявки, с нараствания от 100K реда):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=900001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=800001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=700001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=600001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=500001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=200001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=100001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=000001GROUP BY empid;
Фигура 8 показва резултатите.
Фигура 8:Цена на заявката по отношение на #CPUs и #rows
Зелената линия представлява разходите за различните заявки (с различния брой редове), използвайки сериен план. Другите редове представляват разходите на паралелните планове с различен брой логически процесори и съответните им DOP за изчисляване на разходите. Червената линия представлява точката, в която цената на серийната заявка е 5 — прагът на разходите по подразбиране за настройка на паралелизъм. Вляво от тази точка (по-малко редове за групиране и агрегиране) обикновено оптимизаторът няма да разглежда паралелен план. За да можете да изследвате разходите за паралелни планове под прага на разходите за паралелизъм, можете да направите едно от двете неща. Една от опциите е да използвате намек за заявка ENABLE_PARALLEL_PLAN_PREFERENCE, но като напомняне, тази опция максимизира паралелизма, вместо просто да го принуждава. Ако това не е желаният ефект, можете просто да деактивирате прага на разходите за паралелизъм, както следва:
EXEC sp_configure 'показване на разширени опции', 1; ПРЕКОНФИГУРИРАНЕ; EXEC sp_configure 'праг на разходите за паралелизъм', 0; EXEC sp_configure 'показване на разширени опции', 0; ПРЕКОНФИГУРИРАНЕ;
Очевидно това не е интелигентен ход в производствената система, но е напълно полезен за изследователски цели. Това направих, за да създам информацията за диаграмата на фигура 8.
Започвайки със 100K редове и добавяйки стъпки от 100K, всички графики изглежда предполагат, че прагът на разходите за паралелизъм не е фактор, паралелен план винаги би бил предпочитан. Това наистина е така с нашите заявки и броя на редовете. Опитайте обаче с по-малък брой редове, като се започне с 10K и се увеличава с 10K стъпки, като използвате следните пет заявки (отново оставете прага на разходите за паралелизъм засега деактивиран):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=990001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=980001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=970001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=960001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=950001GROUP BY empid;
Фигура 9 показва разходите за заявка както със сериен, така и с паралелен план (емулиране на 4 CPU, DOP за разходи 2).
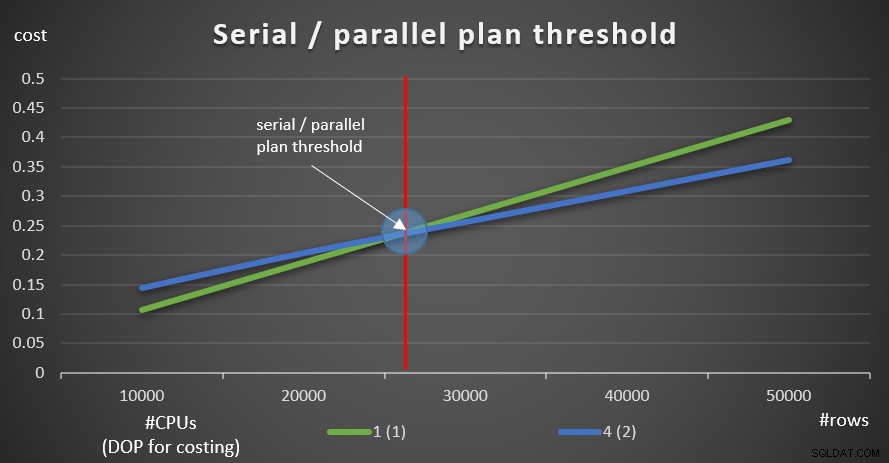 Фигура 9:Сериен / праг на паралелен план
Фигура 9:Сериен / праг на паралелен план
Както можете да видите, има праг за оптимизация, до който се предпочита серийният план и над който се предпочита паралелният план. Както споменахме, в нормална система, при която или поддържате прага на разходите за настройка на паралелизъм на стойност по подразбиране 5 или по-висока, ефективният праг така или иначе е по-висок, отколкото в тази графика.
По-рано споменах, че когато SQL Server избере простата стратегия за групиране и паралелизъм на агрегиране, оценките за мощност на серийния и паралелния план са еднакви. Въпросът е как SQL Server се справя с оценките за кардиналност за стратегията за локален/глобален паралелизъм.
За да разбера това, ще използвам заявка 3 и заявка 4 от предишните ни примери:
-- Запитване 3:Локален паралел глобален паралел SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Заявка 4:Локален паралелен глобален сериен SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid;
В система с 8 логически CPU и ефективен DOP за стойност на себестойност от 4, получих плановете, показани на Фигура 10.
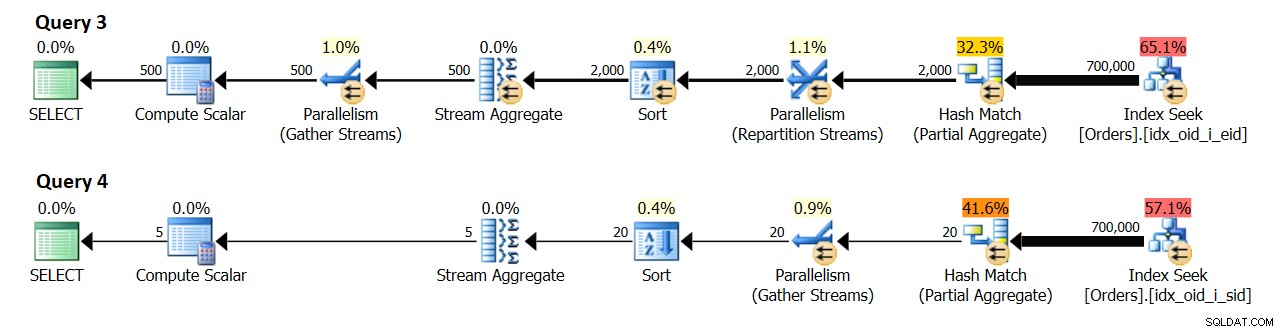 Фигура 10:Оценка на кардиналността
Фигура 10:Оценка на кардиналността
Заявка 3 групира поръчките по empid. В крайна сметка се очакват 500 различни групи служители.
Заявка 4 групира поръчките по изпращач. В крайна сметка се очакват 5 отделни групи изпращачи.
Любопитното е, че изглежда, че оценката на кардиналитета за броя на групите, произведени от локалния агрегат, е {брой отделни групи, очаквани от всяка нишка} * {DOP за изчисляване на разходите}. На практика разбирате, че броят обикновено ще бъде два пъти по-голям, тъй като това, което се брои, е DOP за изпълнение (известен още като просто DOP), който се основава предимно на броя на логическите процесори. Тази част е малко трудна за емулиране за изследователски цели, тъй като командата DBCC OPTIMIZER_WHATIF с опцията CPUs влияе върху изчисляването на DOP за изчисляване на разходите, но DOP за изпълнение няма да бъде по-голям от действителния брой логически CPU, които вашият екземпляр на SQL Server вижда. Това число по същество се основава на броя на планировчиците, с които SQL Server започва. Вие можете контролирайте броя на планировчиците, които SQL Server започва с помощта на стартовия параметър -P{ #schedulers }, но това е малко по-агресивен инструмент за изследване в сравнение с опцията за сесия.
Във всеки случай, без да емулирам никакви ресурси, моята тестова машина има 4 логически процесора, което води до DOP за цена 2 и DOP за изпълнение 4. В моята среда локалният агрегат в плана за заявка 3 показва оценка от 1000 групи резултати (500 x 2) и действително от 2000 (500 x 4). По подобен начин местният агрегат в плана за заявка 4 показва приблизителна оценка от 10 групи резултати (5 x 2) и действителна от 20 (5 x 4).
Когато приключите с експериментирането, изпълнете следния код за почистване:
-- Задаване на прага на разходите за паралелизъм по подразбиране EXEC sp_configure 'показване на разширени опции', 1; ПРЕКОНФИГУРИРАНЕ; EXEC sp_configure 'праг на разходите за паралелизъм', 5; EXEC sp_configure 'показване на разширени опции', 0; RECONFIGURE;GO -- Нулиране на опциите OPTIMIZER_WHATIF DBCC OPTIMIZER_WHATIF(ResetAll); -- Изпускане на индексите ИЗПУСКАНЕ НА ИНДЕКС idx_oid_i_sid НА dbo.Orders; ИЗПУСКАНЕ НА ИНДЕКС idx_oid_i_eid НА dbo.Orders; ИЗПУСКАНЕ НА ИНДЕКС idx_oid_i_cid НА dbo.Orders;
Заключение
В тази статия описах редица стратегии за паралелизъм, които SQL Server използва за обработка на групиране и агрегиране. Важна концепция, която трябва да се разбере при оптимизирането на заявки с паралелни планове, е степента на паралелизъм (DOP) за изчисляване на разходите. Показах редица прагове за оптимизация, включително праг между серийни и паралелни планове и праг за настройка на разходите за паралелизъм. Повечето от концепциите, които описах тук, не са уникални за групирането и агрегирането, а са също толкова приложими за съображения за паралелен план в SQL Server като цяло. Следващия месец ще продължа поредицата, като обсъждам оптимизацията с пренаписване на заявки.