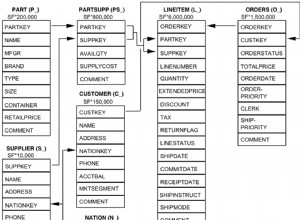
Какво прави индексирането?
Индексирането е начинът да получите неподредена таблица в поръчка, която ще увеличи максимално ефективността на заявката по време на търсене.
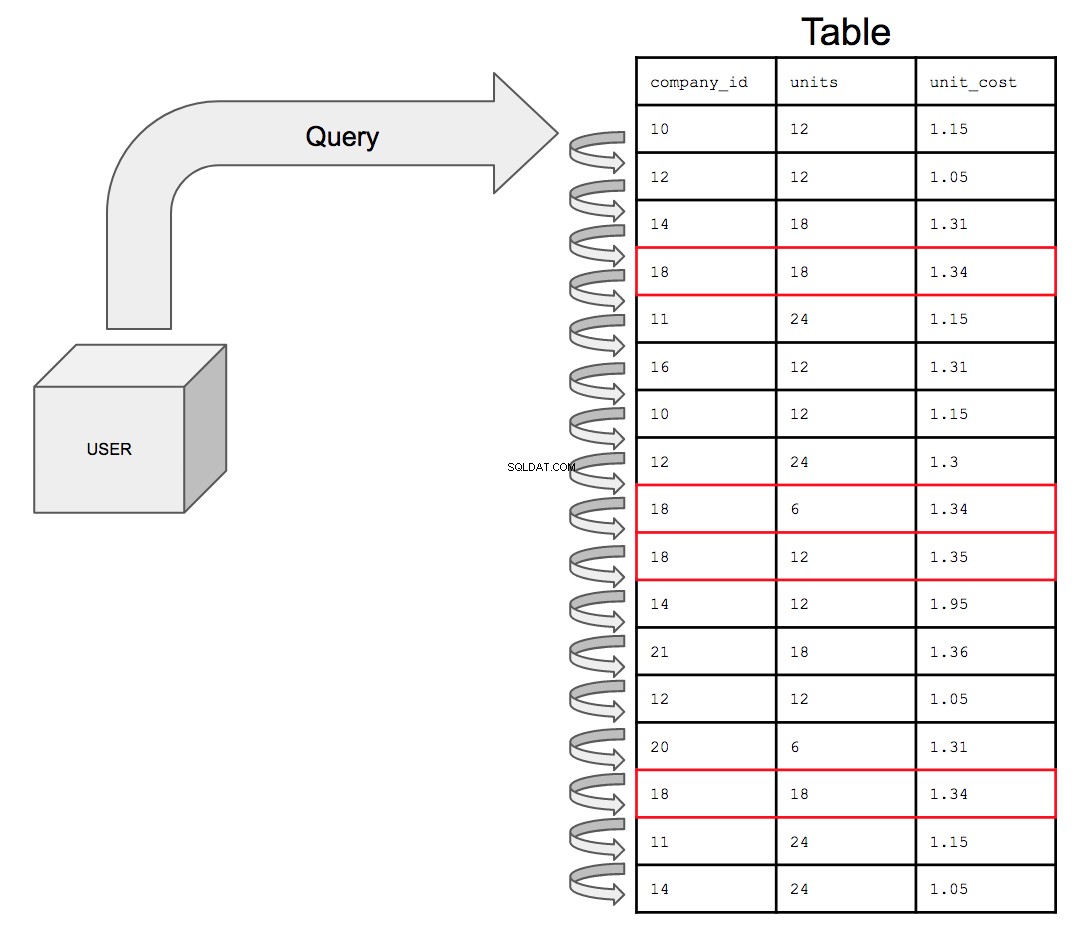
Когато таблицата е неиндексирана, редът на редовете вероятно няма да бъде различим от заявката като оптимизиран по какъвто и да е начин и следователно вашата заявка ще трябва да търси из редовете линейно. С други думи, заявките ще трябва да търсят във всеки ред, за да намерят редовете, отговарящи на условията. Както можете да си представите, това може да отнеме много време. Преглеждането на всеки ред не е много ефективно.
Например таблицата по-долу представлява таблица във измислен източник на данни, който е напълно неподреден.
| company_id | единица | unit_cost |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1.95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Ако трябваше да изпълним следната заявка:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
Базата данни ще трябва да търси във всичките 17 реда в реда, в който се появяват в таблицата, отгоре надолу, един по един. Така че, за да потърсите всички потенциални екземпляри на company_id номер 18, базата данни трябва да прегледа цялата таблица за всички появявания на 18 в company_id колона.
Това само ще отнема все повече и повече време, тъй като размерът на масата се увеличава. С нарастването на сложността на данните това, което в крайна сметка може да се случи е, че таблица с един милиард реда се присъедини към друга таблица с един милиард реда; заявката вече трябва да търси в двойно по-голямо количество редове, което струва двойно повече време.
Можете да видите как това става проблематично в нашия вечно наситен с данни свят. Таблиците се увеличават по размер и търсенето се увеличава във времето за изпълнение.
Запитването на неиндексирана таблица, ако е представено визуално, би изглеждало така:
Това, което прави индексирането, е да настройва колоната, в която се намират условията за търсене, в сортиран ред, за да помогне за оптимизиране на ефективността на заявката.
С индекс на company_id колона, таблицата по същество би „изглеждала“ така:
| company_id | единица | unit_cost |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1.95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Сега базата данни може да търси company_id номер 18 и върнете всички искани колони за този ред, след което преминете към следващия ред. Ако comapny_id на следващия ред номерът също е 18, тогава той ще върне всички колони, поискани в заявката. Ако company_id на следващия ред е 20, заявката знае да спре търсенето и заявката ще завърши.
Как работи индексирането?
В действителност таблицата на базата данни не се пренарежда всеки път, когато условията на заявката се променят, за да се оптимизира изпълнението на заявката:това би било нереалистично. Всъщност това, което се случва, е, че индексът кара базата данни да създаде структура от данни. Типът структура на данните много вероятно е B-дърво. Докато предимствата на B-Tree са многобройни, основното предимство за нашите цели е, че е сортируемо. Когато структурата на данните е сортирана по ред, това прави търсенето ни по-ефективно поради очевидните причини, които посочихме по-горе.
Когато индексът създава структура от данни за конкретна колона, важно е да се отбележи, че в структурата на данните не се съхранява друга колона. Нашата структура от данни за таблицата по-горе ще съдържа само company_id числа. Единици и unit_cost няма да се задържат в структурата на данните.
Как базата данни знае какви други полета в таблицата да върне?
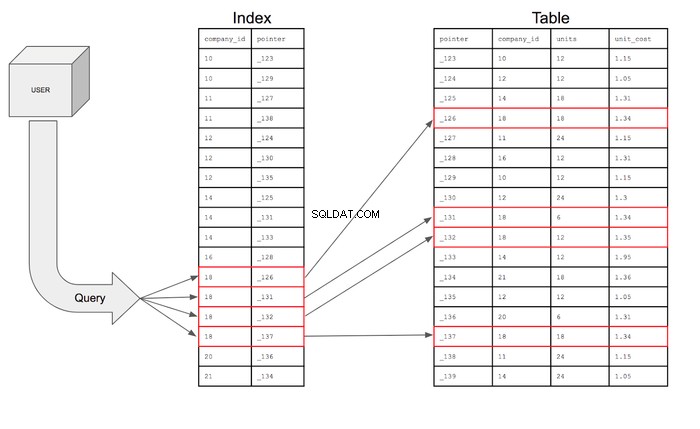
Индексите на базата данни също ще съхраняват указатели, които са просто референтна информация за местоположението на допълнителната информация в паметта. По принцип индексът съдържа company_id и домашния адрес на този конкретен ред на диска с памет. Индексът всъщност ще изглежда така:
| company_id | указател |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С този индекс заявката може да търси само редовете в company_id колона, която има 18 и след това с помощта на показалеца може да влезе в таблицата, за да намери конкретния ред, където живее този указател. След това заявката може да влезе в таблицата, за да извлече полетата за колоните, поискани за редовете, които отговарят на условията.
Ако търсенето беше представено визуално, то би изглеждало така:
Резюме
- Индексирането добавя структура от данни с колони за условията за търсене и указател
- Показателят е адресът на диска с памет на реда с останалата информация
- Структурата на индексните данни е сортирана, за да оптимизира ефективността на заявката
- Заявката търси конкретния ред в индекса; индексът се отнася до указателя, който ще намери останалата информация.
- Индексът намалява броя на редовете, в които заявката трябва да търси, от 17 на 4.