SQL Server въведе OLTP обекти в паметта в SQL Server 2014. Имаше много ограничения в първоначалната версия; някои са адресирани в SQL Server 2016 и се очаква, че повече ще бъдат разгледани в следващата версия, тъй като функцията продължава да се развива. Досега приемането на In-Memory OLTP не изглежда много широко разпространено, но с напредването на функцията очаквам повече клиенти да започнат да питат за внедряване. Както при всяка голяма промяна на схема или код, препоръчвам задълбочено тестване, за да се определи дали In-Memory OLTP ще осигури очакваните ползи. Имайки това предвид, ми беше интересно да видя как се променя производителността за много прости оператори INSERT, UPDATE и DELETE с In-Memory OLTP. Надявах се, че ако успея да демонстрирам заключването или заключването като проблем с базирани на диск таблици, тогава таблиците в паметта ще осигурят решение, тъй като са без заключване и заключване.
Разработих следния тест случаи:
- Дискова таблица с традиционните съхранени процедури за DML.
- Таблица в паметта с традиционните съхранени процедури за DML.
- Таблица в паметта с компилирани процедури за DML.
Интересувах се от сравняването на производителността на традиционните съхранени процедури и нативно компилираните процедури, защото едно ограничение на нативно компилираната процедура е, че всички таблици, за които се препраща, трябва да са в паметта. Докато едноредовите, самостоятелни модификации може да са често срещани в някои системи, често виждам модификации да се случват в рамките на по-голяма съхранена процедура с множество изрази (SELECT и DML), които имат достъп до една или повече таблици. Документацията за OLTP в паметта силно препоръчва използването на компилирани процедури, за да получите максимална полза по отношение на производителността. Исках да разбера колко подобри производителността.
Настройката
Създадох база данни с оптимизирана за памет файлова група и след това създадох три различни таблици в базата данни (една базирана на диск, две в паметта):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
DDL беше почти еднакъв за всички обекти, като се отчиташе на диска спрямо в паметта, където е уместно. DiskTable DDL срещу DDL в паметта:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Също така създадох девет съхранени процедури – по една за всяка комбинация от таблица/модификация.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Изтриване
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Всяка съхранена процедура приема целочислен вход за цикъл за този брой модификации. Съхранените процедури следваха същия формат, вариациите бяха само достъпната таблица и дали обектът е компилиран или не. Пълният код за създаване на база данни и обекти можете да намерите тук, с примерни изрази INSERT и UPDATE по-долу:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Забележка:Таблиците IDs_* бяха повторно попълнени след завършване на всеки набор от INSERT и бяха специфични за трите различни сценария.
Методология на тестване
Тестването беше извършено с помощта на .cmd скриптове, които използваха sqlcmd за извикване на скрипт, който изпълнява съхранената процедура, например:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"изход
Използвах този подход, за да създам една или повече връзки към базата данни, които ще работят едновременно. В допълнение към разбирането на основните промени в производителността, аз също исках да проуча ефекта от различните натоварвания. Тези скриптове бяха инициирани от отделна машина, за да се премахнат излишните разходи за създаване на инстанции на връзки. Всяка съхранена процедура беше изпълнена 1000 пъти от връзка и тествах 1 връзка, 10 връзки и 100 връзки (съответно 1000, 10000 и 100000 модификации). Заснех показатели за производителност с помощта на Query Store, а също така заснех и статистика за чакане. С Query Store бих могъл да уловя средна продължителност и CPU за всяка съхранена процедура. Данните за статистически данни за чакане бяха уловени за всяка връзка с помощта на dm_exec_session_wait_stats, след което бяха обобщени за целия тест.
Проведох всеки тест четири пъти и след това изчислих общите средни стойности за данните, използвани в тази публикация. Скриптове, използвани за тестване на работното натоварване, могат да бъдат изтеглени от тук.
Резултати
Както може да се предвиди, производителността с обекти в паметта е по-добра, отколкото с обекти, базирани на диск. Въпреки това, таблица в паметта с обикновена съхранена процедура понякога има сравнима или само малко по-добра производителност в сравнение с дискова таблица с обикновена съхранена процедура. Запомнете:интересувах се да разбера дали наистина имам нужда от компилирана съхранена процедура, за да получа голяма полза с таблица в паметта. За този сценарий го направих. Във всички случаи таблицата в паметта с нативно компилираната процедура имаше значително по-добра производителност. Двете графики по-долу показват едни и същи данни, но с различни мащаби за оста x, за да демонстрират тази производителност за редовни съхранени процедури, които променят данните, влошени с повече едновременни връзки.
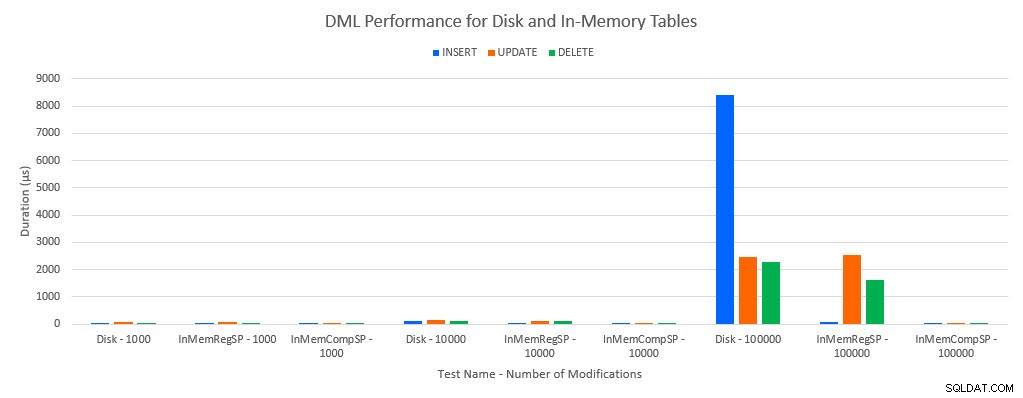
Ефективност на DML по тест и работно натоварване
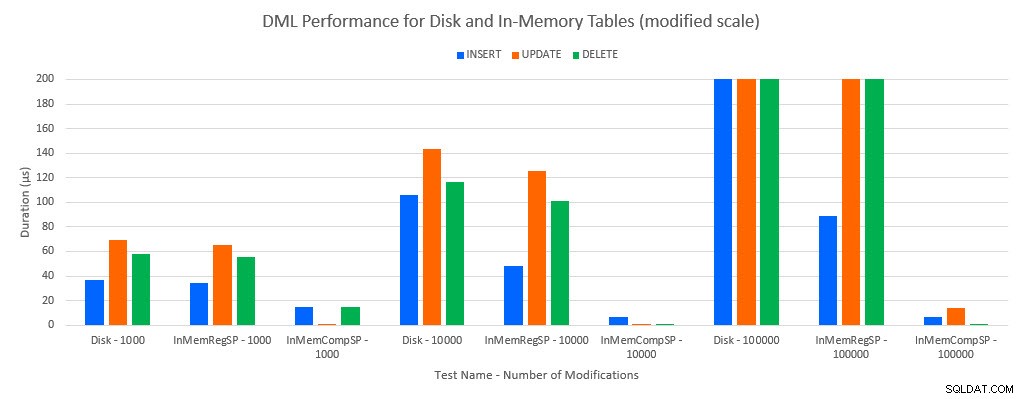
Ефективност на DML по тест и работно натоварване [Променен мащаб]
Изключението е INSERTs в таблицата In-Memory с обикновената съхранена процедура. При 100 връзки средната продължителност е над 8 мс за дисково базирана таблица, но по-малко от 100 микросекунди за таблицата в паметта. Вероятната причина е липсата на заключване и заключване с таблицата в паметта и това се поддържа с данни за статистика за чакане:
| Тест | INSERT | АКТУАЛИЗИРАНЕ | ИЗТРИВАНЕ |
|---|---|---|---|
| Таблица с дискове – 1000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
| InMemTable_RegularSP – 1000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
| InMemTable_CompiledSP – 1000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Таблица с дискове – 10 000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
| InMemTable_RegularSP – 10 000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
| InMemTable_CompiledSP – 10 000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | MEMORY_ALLOCATION_EXT |
| Таблица с дискове – 100 000 | PAGELATCH_EX | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
| InMemTable_RegularSP – 100 000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
| InMemTable_CompiledSP – 100 000 | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ | РЕГИСТРАЦИЯ ЗА ПИШЕНЕ |
Изчакайте статистика чрез тест
Данните за статистическите данни за изчакване са изброени тук въз основа на общото време за изчакване на ресурса (което обикновено се превежда и до най-високото средно време за ресурс, но имаше изключения). Типът на чакане WRITELOG е ограничаващият фактор в тази система през по-голямата част от времето. Въпреки това, PAGELATCH_EX изчаква 100 едновременни връзки, изпълняващи оператори INSERT, предполага, че при допълнително натоварване поведението на заключване и заключване, което съществува с базирани на диск таблици, може да бъде ограничаващ фактор. В сценариите UPDATE и DELETE с 10 и 100 връзки за тестовете на дискови таблици, средното време за изчакване на ресурса е най-високо за заключвания (LCK_M_X).
Заключение
In-Memory OLTP може абсолютно да осигури повишаване на производителността за правилното работно натоварване. Тестваните тук примери обаче са изключително прости и не трябва да се разглеждат само като причина за мигриране към решение In-Memory. Все още съществуват множество ограничения, които трябва да се вземат предвид и трябва да се направи задълбочено тестване, преди да се осъществи миграция (особено защото мигрирането към таблица в паметта е офлайн процес). Но за правилния сценарий тази нова функция може да осигури повишаване на производителността. Стига да разберете, че някои основни ограничения все още ще съществуват, като например скоростта на регистъра на транзакциите за трайни таблици, макар и най-вероятно в намален начин – независимо дали таблицата съществува на диск или в паметта.