Тази публикация има „прикачени низове:по добра причина. Ще проучим дълбоко в SQL VARCHAR, типът данни, който се занимава с низове.
Освен това това е „само за вашите очи“, защото без низове няма да има публикации в блогове, уеб страници, инструкции за игри, запазени рецепти и много повече, за да могат очите ни да четат и да се наслаждават. Ние се занимаваме с един милион струни всеки ден. Така че, като разработчици, вие и аз сме отговорни да направим този вид данни ефективни за съхранение и достъп.
Имайки това предвид, ще разгледаме най-важното за съхранението и производителността. Въведете какво трябва и не трябва за този тип данни.
Но преди това VARCHAR е само един от типовете низове в SQL. Какво го прави различен?
Какво е VARCHAR в SQL? (С примери)
VARCHAR е низ или символен тип данни с различен размер. Можете да съхранявате букви, цифри и символи с него. Започвайки със SQL Server 2019, можете да използвате пълния набор от символи на Unicode, когато използвате съпоставяне с поддръжка на UTF-8.
Можете да декларирате VARCHAR колони или променливи, като използвате VARCHAR[(n)], където n означава размера на низа в байтове. Диапазонът от стойности за n е от 1 до 8000. Това са много данни за знаци. Но дори повече, можете да го декларирате с помощта на VARCHAR(MAX), ако имате нужда от гигантски низ до 2GB. Това е достатъчно голямо за вашия списък с тайни и лични неща в дневника ви! Обърнете внимание обаче, че можете да го декларирате и без размера и по подразбиране той е 1, ако го направите.
Нека имаме пример.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
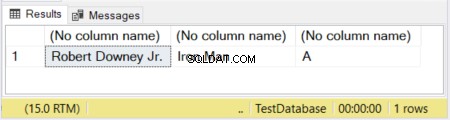
На фигура 1 първите 2 колони имат определени размери. Третата колона остава без размер. И така, думата „Отмъстителите“ е съкратена, защото VARCHAR без деклариран размер по подразбиране е 1 знак.
Сега, нека опитаме нещо огромно. Но имайте предвид, че изпълнението на тази заявка ще отнеме известно време – 23 секунди на моя лаптоп.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
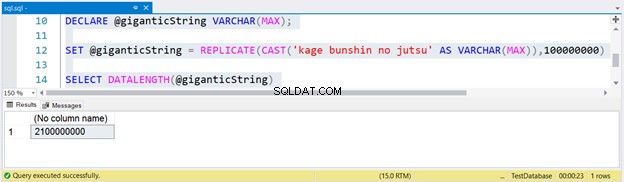
За да генерираме огромен низ, репликирахме kage bunshin no jutsu 100 милиона пъти. Обърнете внимание на CAST в REPLICATE. Ако не CAST низовия израз към VARCHAR(MAX), резултатът ще бъде съкратен само до 8000 знака.
Но как SQL VARCHAR се сравнява с други типове низови данни?
Разлика между CHAR и VARCHAR в SQL
В сравнение с VARCHAR, CHAR е символен тип данни с фиксирана дължина. Без значение колко малка или голяма стойност поставите на променлива CHAR, крайният размер е размерът на променливата. Проверете сравненията по-долу.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
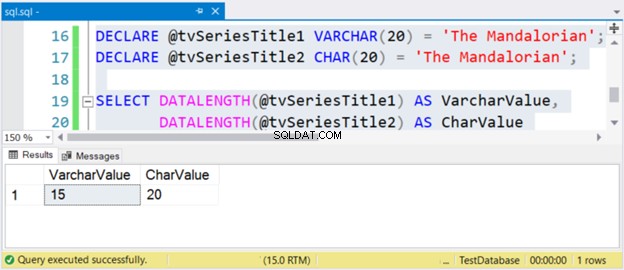
Размерът на низа “The Mandalorian” е 15 знака. И така, VarcharValue колоната го отразява правилно. Въпреки това, CharValue запазва размера на 20 – допълнен е с 5 интервала вдясно.
SQL VARCHAR срещу NVARCHAR
Две основни неща идват на ум, когато сравнявате тези типове данни.
Първо, това е размерът в байтове. Всеки знак в NVARCHAR има два пъти по-голям размер от VARCHAR. NVARCHAR(n) е само от 1 до 4000.
След това знаците, които може да съхранява. NVARCHAR може да съхранява многоезични знаци като корейски, японски, арабски и т.н. Ако планирате да съхранявате корейски K-Pop текстове във вашата база данни, този тип данни е една от вашите опции.
Нека имаме пример. Ще използваме K-pop групата 세븐틴 или Seventeen на английски.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
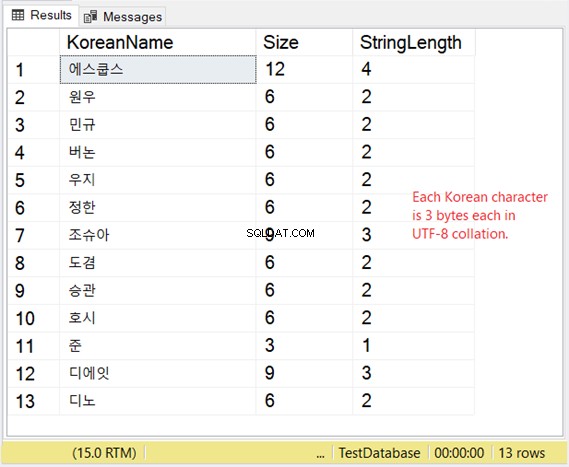
Горният код ще изведе стойността на низа, неговия размер в байтове и броя на знаците. Ако това са не-Unicode знаци, броят на знаците е равен на размера в байтове. Но това не е така. Вижте фигура 4 по-долу.
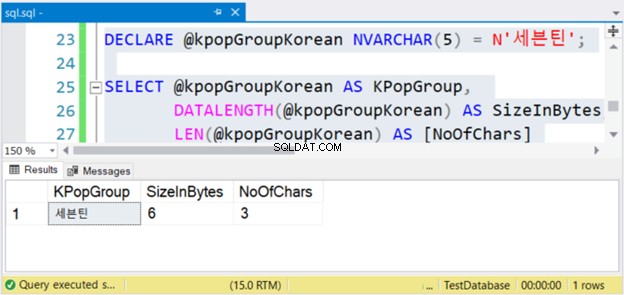
Виждаш ли? Ако NVARCHAR има 3 знака, размерът в байтове е два пъти. Но не и с VARCHAR. Същото важи и ако използвате английски знаци.
Но какво ще кажете за NCHAR? NCHAR е двойникът на CHAR за Unicode знаци.
SQL сървър VARCHAR с поддръжка на UTF-8
VARCHAR с поддръжка на UTF-8 е възможен на ниво сървър, ниво база данни или ниво колона на таблица чрез промяна на информацията за съпоставяне. Използваното съпоставяне трябва да поддържа UTF-8.
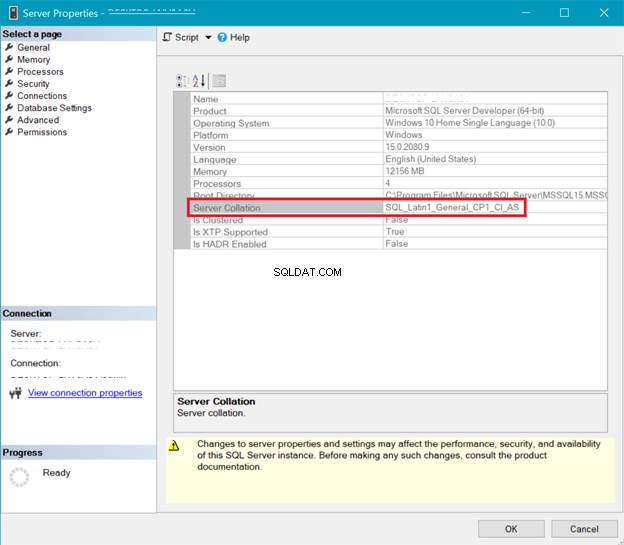
СЪБОРЯВАНЕ НА СЪРВЪР SQL
Фигура 5 представя прозореца в SQL Server Management Studio, който показва сортиране на сървъра.
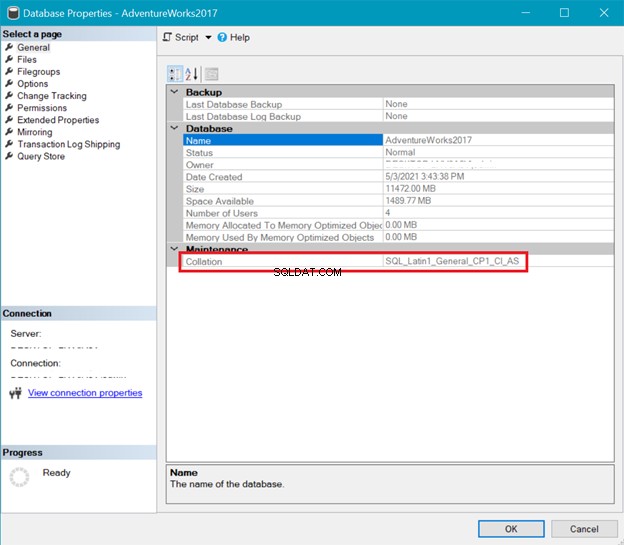
СЪБРАНЕ НА БАЗА ДАННИ
Междувременно Фигура 6 показва съпоставянето на AdventureWorks база данни.
СЪБОРЯВАНЕ НА КОЛОНА НА ТАБЛИЦА
Съпоставянето на сървъра и базата данни по-горе показва, че UTF-8 не се поддържа. Низът за съпоставяне трябва да има _UTF8 в него за поддръжка на UTF-8. Но все пак можете да използвате поддръжка на UTF-8 на ниво колона на таблица. Вижте примера.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
Горният код има Latin1_General_100_BIN2_UTF8 съпоставяне за корейско име колона. Въпреки че VARCHAR, а не NVARCHAR, тази колона ще приема знаци на корейски език. Нека вмъкнем някои записи и след това да ги прегледаме.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
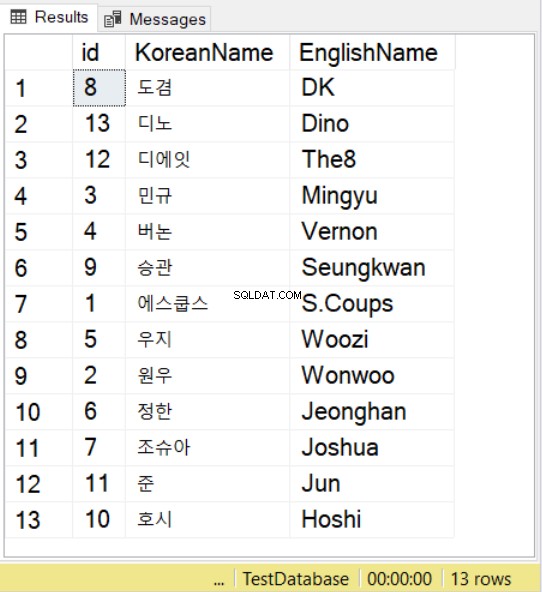
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Използваме имена от групата Seventeen K-pop, използвайки корейски и английски колеги. За корейски знаци, обърнете внимание, че все пак трябва да поставите префикс на стойността с N , точно като това, което правите със стойностите на NVARCHAR.
След това, когато използвате SELECT с ORDER BY, можете да използвате и сортиране. Можете да наблюдавате това в примера по-горе. Това ще следва правилата за сортиране за посоченото съпоставяне.
СЪХРАНЕНИЕ НА VARCHAR С ПОДДРЪЖКА НА UTF-8
Но как става съхранението на тези знаци? Ако очаквате 2 байта на знак, тогава ви очаква изненада. Вижте фигура 8.
Така че, ако съхранението има голямо значение за вас, помислете за таблицата по-долу, когато използвате VARCHAR с поддръжка на UTF-8.
| Знаци | Размер в байтове |
| Ascii 0 – 127 | 1 |
| Азписма, базирана на латиница, както и гръцки, кирилица, коптски, арменски, иврит, арабски, сирийски, Tāna и N’Ko | 2 |
| Източноазиатска писменост като китайски, корейски и японски | 3 |
| Знаци в диапазона 010000–10FFFF | 4 |
Нашият пример за корейски е източноазиатски скрипт, така че е 3 байта на знак.
След като приключихме с описването и сравняването на VARCHAR с други типове низове, нека сега да покрием какво трябва и какво не трябва
Правите при използването на VARCHAR в SQL Server
1. Посочете размер
Какво може да се обърка без да посочите размера?
ОТСЪЖАВАНЕ НА СТРУНА
Ако ви мързи да посочите размера, ще настъпи съкращаване на низа. Вече видяхте пример за това по-рано.
ВЪЗДЕЙСТВИЕ ЗА СЪХРАНЕНИЕ И ИЗПЪЛНЕНИЕ
Друго съображение е съхранението и производителността. Трябва само да зададете правилния размер за вашите данни, не повече. Но как би могъл да знаеш? За да избегнете съкращаване в бъдеще, може просто да го зададете на най-големия размер. Това е VARCHAR(8000) или дори VARCHAR(MAX). И 2 байта ще бъдат съхранени както са. Същото е и с 2GB. Има ли значение?
Отговорът на това ще ни отведе до концепцията за това как SQL Server съхранява данни. Имам друга статия, която обяснява това подробно с примери и илюстрации.
Накратко, данните се съхраняват в 8KB страници. Когато ред с данни надвиши този размер, SQL Server го премества в друга единица за разпределение на страници, наречена ROW_OVERFLOW_DATA.
Да предположим, че имате 2-байтови VARCHAR данни, които може да отговарят на оригиналната единица за разпределение на страници. Когато съхранявате низ, по-голям от 8000 байта, данните ще бъдат преместени на страницата с препълване на ред. След това го свийте отново до по-нисък размер и той ще бъде преместен обратно към оригиналната страница. Движението напред-назад причинява много I/O и затруднение в производителността. Извличането на това от 2 страници вместо от 1 също се нуждае от допълнително I/O.
Друга причина е индексирането. VARCHAR(MAX) е голямо НЕ като индексен ключ. Междувременно VARCHAR(8000) ще надвиши максималния размер на индексния ключ. Това е 1700 байта за неклъстерирани индекси и 900 байта за клъстерирани индекси.
ВЪЗДЕЙСТВИЕ НА КОНВЕРСИЯТА НА ДАННИ
И все пак има още едно съображение:преобразуване на данни. Опитайте го с CAST без размера като кода по-долу.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Този код ще извърши преобразуване на дата/час с информация за часовата зона във VARCHAR.
Така че, ако ни мързи да посочим размера по време на CAST или CONVERT, резултатът е ограничен само до 30 знака.
Какво ще кажете за конвертиране на NVARCHAR в VARCHAR с поддръжка на UTF-8? По-късно има подробно обяснение за това, така че продължавайте да четете.
2. Използвайте VARCHAR, ако размерът на низа варира значително
Имена от AdventureWorks базата данни се различават по размер. Едно от най-кратките имена е Мин Су, докато най-дългото име е Osarumwense Uwaifiokun Agbonile. Това е между 6 и 31 знака, включително интервалите. Нека импортираме тези имена в 2 таблици и да сравним между VARCHAR и CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Кои от 2-те са по-добри? Нека проверим логическите показания, като използваме кода по-долу и инспектираме изхода на STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
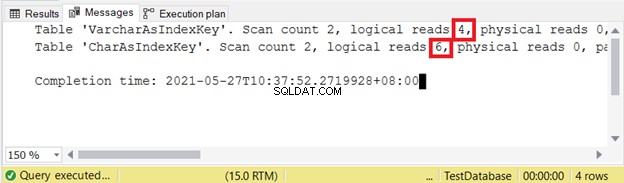
Логически чете:
Колкото по-малко логично се чете, толкова по-добре. Тук колоната CHAR използва повече от два пъти аналога VARCHAR. Така VARCHAR печели в този пример.
3. Използвайте VARCHAR като индексен ключ вместо CHAR, когато стойностите варират по размер
Какво се случи, когато се използва като индексни ключове? Ще се справи ли CHAR по-добре от VARCHAR? Нека използваме същите данни от предишния раздел и да отговорим на този въпрос.
Ще потърсим някои данни и ще проверим логическите показания. В този пример филтърът използва индексния ключ.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
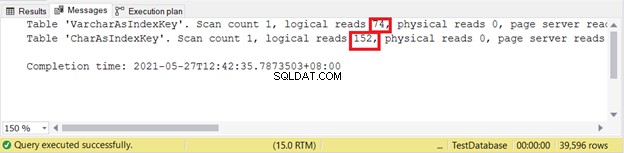
Логически чете:
Следователно индексните ключове VARCHAR са по-добри от индексните ключове CHAR, когато ключът има различни размери. Но какво ще кажете за INSERT и UPDATE, които ще променят записите в индекса?
КОГАТО ИЗПОЛЗВАТЕ INSERT AND UPDATE
Нека тестваме 2 случая и след това да проверим логическите показания, както обикновено правим.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Логически чете:
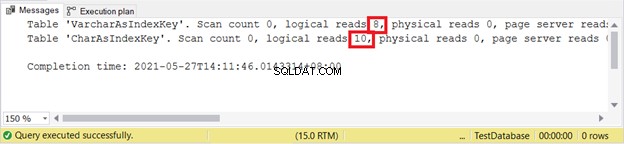
VARCHAR все още е по-добър при вмъкване на записи. Какво ще кажете за АКТУАЛИЗИРАНЕ?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Логически чете:
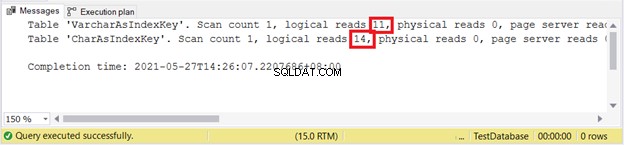
Изглежда, че VARCHAR отново печели.
В крайна сметка печели нашия тест, макар че може да е малък. Имате ли по-голям тестов случай, който доказва обратното?
4. Помислете за VARCHAR с поддръжка на UTF-8 за многоезични данни (SQL Server 2019+)
Ако във вашата таблица има комбинация от Unicode и не-Unicode знаци, можете да помислите за VARCHAR с поддръжка на UTF-8 над NVARCHAR. Ако повечето от знаците са в диапазона от ASCII от 0 до 127, това може да предложи спестяване на място в сравнение с NVARCHAR.
За да разберете какво имам предвид, нека направим сравнение.
NVARCHAR КЪМ VARCHAR С ПОДДРЪЖКА UTF-8
Мигрирахте ли вече вашите бази данни към SQL Server 2019? Планирате ли да мигрирате вашите низови данни към UTF-8 съпоставяне? Ще имаме пример за смесена стойност на японски и неяпонски знаци, за да ви дадем представа.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
След като данните са зададени, ще проверим размера в байтове на 2-те стойности:

Изненада! При NVARCHAR размерът е 30 байта. Това е 15 пъти повече от 2 знака. Но когато се преобразува във VARCHAR с поддръжка на UTF-8, размерът е само 27 байта. Защо 27? Проверете как се изчислява това.

Така 9 от символите са по 1 байт всеки. Това е интересно, защото с NVARCHAR английските букви също са 2 байта. Останалите японски символи са по 3 байта.
Ако това са били всички японски символи, низът от 15 символа ще бъде 45 байта и също така ще използва максималния размер на VarcharUTF8 колона. Забележете, че размерът на NVarcharValue колоната е по-малка от VarcharUTF8 .
Размерите не могат да бъдат равни при конвертиране от NVARCHAR или данните може да не паснат. Можете да се обърнете към предишната таблица 1.
Помислете за въздействието върху размера, когато конвертирате NVARCHAR в VARCHAR с поддръжка на UTF-8.
Не трябва да използвате VARCHAR в SQL Server
1. Когато размерът на низа е фиксиран и не подлежи на нула, използвайте вместо това CHAR.
Общото правило, когато се изисква низ с фиксиран размер, е да се използва CHAR. Следвам това, когато имам изискване за данни, което се нуждае от десни интервали. В противен случай ще използвам VARCHAR. Имах няколко случая на употреба, когато трябваше да изхвърля низове с фиксирана дължина без разделители в текстов файл за клиент.
Освен това използвам колони CHAR само ако колоните няма да бъдат нула. Защо? Тъй като размерът в байтове на колоните CHAR, когато NULL е равен на определения размер на колоната. И все пак VARCHAR, когато NULL има размер 1, независимо колко е дефинираният размер. Изпълнете кода по-долу и вижте сами.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Не използвайте VARCHAR(n) Ако n Ще надхвърли 8000 байта. Вместо това използвайте VARCHAR(MAX).
Имате ли низ, който ще надвишава 8000 байта? Това е моментът да използвате VARCHAR(MAX). Но за най-често срещаните форми на данни като имена и адреси, VARCHAR(MAX) е излишно и ще повлияе на производителността. В моя личен опит не си спомням изискване да използвам VARCHAR(MAX).
3. Когато използвате многоезични знаци със SQL Server 2017 и по-долу. Вместо това използвайте NVARCHAR.
Това е очевиден избор, ако все още използвате SQL Server 2017 и по-долу.
Дъното
Типът данни VARCHAR ни послужи добре за толкова много аспекти. Това беше за мен от SQL Server 7. Но понякога все още правим лош избор. В тази публикация SQL VARCHAR е дефиниран и сравнен с други типове низови данни с примери. И отново, ето какво трябва и не трябва да се прави за по-бърза база данни:
Направете:
- Посочете размера n в VARCHAR[(n)] дори и да е по избор.
- Използвайте го, когато размерът на низа варира значително.
- Разглеждайте колоните VARCHAR като индексни ключове вместо CHAR.
- И ако сега използвате SQL Server 2019, помислете за VARCHAR за многоезични низове с поддръжка на UTF-8.
Не трябва:
- Не използвайте VARCHAR, когато размерът на низа е фиксиран и не подлежи на нула.
- Не използвайте VARCHAR(n), когато размерът на низа надвишава 8000 байта.
- И не използвайте VARCHAR за многоезични данни, когато използвате SQL Server 2017 и по-стари версии.
Имате ли още нещо да добавите? Уведомете ни в секцията за коментари. Ако смятате, че това ще помогне на приятелите ви разработчици, моля, споделете това в любимите си социални медийни платформи.