Често срещан сценарий в много приложения клиент-сървър позволява на крайния потребител да диктува реда на сортиране на резултатите. Някои хора искат първо да видят най-евтините артикули, други искат първо да видят най-новите артикули, а някои искат да ги видят по азбучен ред. Това е сложно нещо за постигане в Transact-SQL, защото не можете просто да кажете:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.SortOnSomeTable @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN ... ORDER BY @SortColumn; -- или ... ПОРЪЧАЙТЕ ПО @SortColumn @SortDirection;ENDGO
Това е така, защото T-SQL не позволява променливи в тези местоположения. Ако просто използвате @SortColumn, получавате:
Съобщение 1008, ниво 16, състояние 1, ред xЕлементът SELECT, идентифициран с ORDER BY номер 1, съдържа променлива като част от израза, идентифициращ позицията на колона. Променливите са разрешени само при подреждане по израз, препращащ име на колона.
(И когато съобщението за грешка казва „израз, препращащ име на колона“, може да го намерите за двусмислен и аз съм съгласен. Но мога да ви уверя, че това не означава, че променливата е подходящ израз.)
Ако се опитате да добавите @SortDirection, съобщението за грешка е малко по-непрозрачно:
Съобщение 102, ниво 15, състояние 1, ред xНеправилен синтаксис близо до „@SortDirection“.
Има няколко начина да заобиколите това и първият ви инстинкт може да е да използвате динамичен SQL или да въведете CASE израза. Но както при повечето неща, има усложнения, които могат да ви принудят да тръгнете по един или друг път. И така, кой трябва да използвате? Нека проучим как могат да работят тези решения и да сравним въздействието върху производителността за няколко различни подхода.
Примерни данни
Използвайки изглед на каталог, който вероятно всички разбираме доста добре, sys.all_objects, създадох следната таблица въз основа на кръстосано присъединяване, ограничавайки таблицата до 100 000 реда (исках данни, които запълват много страници, но не отне много време за заявка и тест):
CREATE DATABASE OrderBy;GOUSE OrderBy;GO SELECT TOP (100000) key_col =ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- BIGINT с клъстериран индекс s1.[object_id], -- INT без INT без номер_на_обекта. име на индекс =s1.name -- NVARCHAR с поддържащ индекс COLLATE SQL_Latin1_General_CP1_CI_AS, type_desc =s1.type_desc -- NVARCHAR(60) без индекс COLLATE SQL_Latin1_General_CP1_CI_AS, s1.modify_timeobject без FROM_timeobject дата на FROM. sys.all_objects AS s1 КРЪСТО ПРИСЪЕДИНЯВАНЕ sys.all_objects КАТО s2 ПОРЪЧАЙТЕ ПО s1.[object_id];
(Тръкът COLLATE е, защото много каталожни изгледи имат различни колони с различни съпоставяния и това гарантира, че двете колони ще съвпадат за целите на тази демонстрация.)
След това създадох типична двойка клъстериран/неклъстериран индекс, която може да съществува в такава таблица, преди оптимизацията (не мога да използвам object_id за ключа, защото кръстосаното свързване създава дубликати):
СЪЗДАЙТЕ УНИКАЛЕН КЛУСТРИРАН ИНДЕКС key_col НА dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Случаи на употреба
Както бе споменато по-горе, потребителите може да искат да видят тези данни, подредени по различни начини, така че нека изложим някои типични случаи на употреба, които искаме да поддържаме (и под поддръжка, имам предвид, демонстрира):
- Поредено по key_col нарастващо ** по подразбиране, ако потребителят не го интересува
- Поредено по object_id (възходящ/низходящ)
- Пореден по име (възходящ/низходящ)
- Поредено по type_desc (възходящ/низходящ)
- Поредено по modify_date (възходящ/низходящ)
Ще оставим подреждането key_col по подразбиране, защото трябва да бъде най-ефективно, ако потребителят няма предпочитание; тъй като key_col е произволен сурогат, който не трябва да означава нищо за потребителя (и дори може да не е изложен на тях), няма причина да се разрешава обратното сортиране на тази колона.
Подходи, които не работят
Най-често срещаният подход, който виждам, когато някой за първи път започне да се справя с този проблем, е въвеждането на логика за контрол на потока в заявката. Те очакват да могат да направят това:
SELECT key_col, [object_id], name, type_desc, modify_dateFROM dbo.sys_objectsORDER BY IF @SortColumn ='key_col' key_colIF @SortColumn ='object_id' [object_id]IF @Sort'name'name' IF @Sort'name' ='ASC' ASCELSE DESC;
Това очевидно не работи. След това виждам, че CASE е въведен неправилно, използвайки подобен синтаксис:
SELECT key_col, [object_id], name, type_desc, modify_dateFROM dbo.sys_objects ORDER BY CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] WHEN 'name 'name' ENDre THEN 'ASC' THEN ASC ELSE DESC END;
Това е по-близо, но се проваля по две причини. Единият е, че CASE е израз, който връща точно една стойност от конкретен тип данни; това обединява типове данни, които са несъвместими и следователно ще наруши CASE израза. Другият е, че няма начин условно да се приложи посоката на сортиране по този начин, без да се използва динамичен SQL.
Подходи, които работят
Трите основни подхода, които видях, са следните:
Групирайте съвместими типове и упътвания заедно
За да използвате CASE с ORDER BY, трябва да има отделен израз за всяка комбинация от съвместими типове и посоки. В този случай ще трябва да използваме нещо подобно:
CREATE PROCEDURE dbo.Sort_CaseExpanded @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ key_col, [object_id], name, type_desc, modify_date ОТ dbo.sys_objects ПОРЪЧАЙТЕ ПО СЛУЧАЙ, КОГАТО @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN'] NASE WHEN_id THEN 'NASE WHEN_id SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] END END DESC, CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn'name WHEN' THEHN_type WHN име WHN type_desc END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'name' THEN name WHEN 'type_desc' THEN type_desc END END DESC, CASE WHEN @SortColumn ='modifySortColumn THE 'date @SortColumn' AND , CASE WHEN @SortColumn ='modify_date' И @SortDirection ='DESC' THEN modify_date END DESC;END
Може да кажете, уау, това е грозен къс код и бих се съгласил с вас. Мисля, че това е причината много хора да кешират данните си в предния край и оставят нивото на презентацията да се занимава с жонглирането им в различни редове. :-)
Можете да свиете тази логика още малко, като преобразувате всички ненизови типове в низове, които ще сортират правилно, напр.
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.Sort_CaseCollapsed @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; ИЗБЕРЕТЕ key_col, [object_id], name, type_desc, modify_date ОТ dbo.sys_objects ПОРЪЧАЙТЕ ПО СЛУЧАЙ, КОГАТО @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN 'key_col' THEN RIGHT('0000000EN'0) object_id' ТОГАВА НАДЯСНО(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([object_id]), 24) КОГА 'name' THEN name WHEN 'type_desc' THEN type_desc КОГА 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn'key WHEN' 000000000000' + RTRIM(key_col), 12) КОГАТО 'object_id' ТОГАВА НАДЯСНО(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) ) + RTRIM([object_id]), 24) КОГА 'име' СЛЕД име КОГА 'type_desc' СЛЕД type_desc КОГА 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END END DESC;END Все пак това е доста грозна бъркотия и трябва да повторите изразите два пъти, за да се справите с различните посоки на сортиране. Също така бих подозирал, че използването на OPTION RECOMPILE за тази заявка ще ви попречи да бъдете ужилени от подслушване на параметри. Освен в случая по подразбиране, не е като по-голямата част от работата, която се извършва тук, ще бъде компилация.
Прилагане на ранг с помощта на прозоречни функции
Открих този чист трик от AndriyM, въпреки че е най-полезен в случаите, когато всички потенциални колони за подреждане са от съвместими типове, в противен случай изразът, използван за ROW_NUMBER(), е еднакво сложен. Най-умната част е, че за да превключваме между възходящ и низходящ ред, ние просто умножаваме ROW_NUMBER() по 1 или -1. Можем да го приложим в тази ситуация, както следва:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.Sort_RowNumber @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON;;С x AS ( ИЗБЕРЕТЕ ключ_col, [object_id], име, type_desc, modify_date, rn =ROW_NUMBER() НАД ( ПОРЪЧКА ПО СЛУЧАЙ @SortColumn WHEN 'key_col' THEN RIGHT('000000000000') + RTRIM(ke1) object_id' ТОГАВА НАДЯСНО(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([object_id]), 24) КОГА 'name' THEN name WHEN 'type_desc' THEN type_desc КОГА 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120) END ) * CASE @SortDirection, КОГАТО 'ASC' THEN 1 ELSE -1 END FROM djectbo. , [object_id], name, type_desc, modify_date FROM x ORDER BY rn;ENDGO Отново, OPTION RECOMPILE може да помогне тук. Също така може да забележите в някои от тези случаи, че връзките се обработват по различен начин от различните планове – когато поръчвате по име, например, обикновено ще видите, че key_col идва във възходящ ред във всеки набор от дублиращи се имена, но може също да видите стойностите се смесват. За да осигурите по-предвидимо поведение в случай на връзки, винаги можете да добавите допълнителна клауза ORDER BY. Имайте предвид, че ако трябва да добавите key_col към първия пример, ще трябва да го направите израз, така че key_col да не е посочен в ORDER BY два пъти (можете да направите това, като използвате key_col + 0, например).
Динамичен SQL
Много хора имат резерви относно динамичния SQL – невъзможно е за четене, това е среда за SQL инжектиране, води до раздуване на кеша на планове, побеждава целта за използване на съхранени процедури... Някои от тях са просто неверни, а някои от тях са лесни за смекчаване. Тук добавих малко валидиране, което също толкова лесно може да се добави към някоя от горните процедури:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.Sort_DynamicSQL @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; -- отхвърли всички невалидни посоки за сортиране:IF UPPER(@SortDirection) NOT IN ('ASC','DESC') BEGIN RAISERROR('Невалиден параметър за @SortDirection:%s', 11, 1, @SortDirection); ВРЪЩАНЕ -1; END -- отхвърлете всички неочаквани имена на колони:IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date') BEGIN RAISERROR('Невалиден параметър за @SortColumn:%s', 11, 1, @SortColumn); ВРЪЩАНЕ -1; END SET @SortColumn =QUOTENAME(@SortColumn); ДЕКЛАРИРАНЕ @sql NVARCHAR(MAX); SET @sql =N'SELECT key_col, [object_id], name, type_desc, modify_date FROM dbo.sys_objects ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';'; EXEC sp_executesql @sql;END Сравнения на производителността
Създадох съхранена процедура за всяка процедура по-горе, за да мога лесно да тествам всички сценарии. Четирите процедури за обвивка изглеждат така, като името на процедурата, разбира се, варира:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.Test_Sort_CaseExpandedASBEGIN ЗАДАДЕТЕ NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- по подразбиране EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC';END
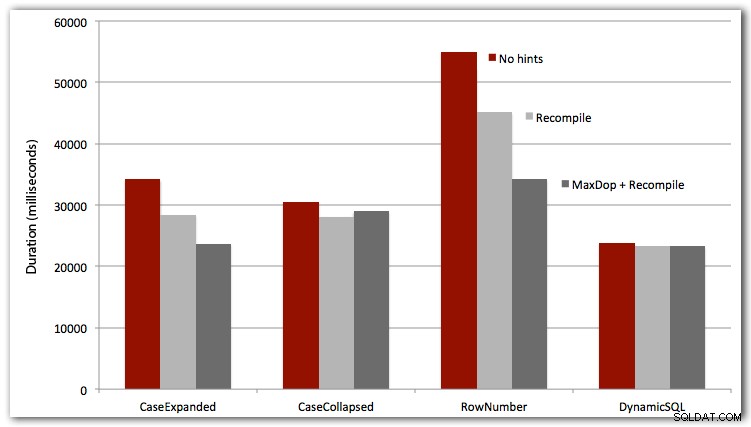
След това, използвайки SQL Sentry Plan Explorer, генерирах действителни планове за изпълнение (и показателите, които да вървят заедно с него) със следните заявки и повторих процеса 10 пъти, за да обобщя общата продължителност:
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;EXEC dbo.Test_Sort_CaseExpanded;--EXEC dbo.Test_Sort_CaseCollapsed;--EXEC dbo.Test_Sort_RowNumber;--EXEC dbo.Test_namic;-EXEC dbo.Test_namic;Тествах също първите три случая с OPTION RECOMPILE (няма много смисъл за динамичния SQL случай, тъй като знаем, че всеки път ще бъде нов план), и всичките четири случая с MAXDOP 1 за елиминиране на намесата на паралелизъм. Ето резултатите:
Заключение
За пълна производителност динамичният SQL печели всеки път (макар и само с малка разлика в този набор от данни). Подходът ROW_NUMBER(), макар и умен, беше губещ във всеки тест (съжалявам, AndriyM).
Става още по-забавно, когато искате да въведете клауза WHERE, без значение пейджинг. Тези три са като перфектната буря за въвеждане на сложност на това, което започва като проста заявка за търсене. Колкото повече пермутации има вашата заявка, толкова по-вероятно ще искате да изхвърлите четливостта през прозореца и да използвате динамичен SQL в комбинация с настройката „оптимизиране за ad hoc работни натоварвания“, за да сведете до минимум въздействието на плановете за еднократна употреба в кеша на плана си.