Гост автор:Моника Ратбън (@SQLEspresso)
Понякога проблемите с хардуерната производителност, като латентността на дисковия вход/изход, се свеждат до неоптимизирано работно натоварване, а не до недостатъчна производителност на хардуера. Много администратори на бази данни, включително и аз, искат незабавно да обвинят хранилището за бавността. Преди да отидете и да похарчите много пари за нов хардуер, винаги трябва да проверявате натоварването си за ненужни I/O.
Неща за разглеждане
| Елемент | I/O въздействие | Възможни решения |
|---|---|---|
| Неизползвани индекси | Допълнителни записи | Премахване / Деактивиране на индекса |
| Липсващи индекси | Допълнителни четения | Добавяне на индекс/покриващи индекси |
| Неявни преобразувания | Допълнително четене и запис | Скрито или прехвърлено поле при източника преди оценка на стойността |
| Функции | Допълнително четене и запис | Премахна ги, преобразува данните преди оценка |
| ETL | Допълнително четене и запис | Използвайте SSIS, репликация, улавяне на промяна на данни, групи за наличност |
| Поръчка и групиране по | Допълнително четене и запис | Отстранете ги, където е възможно |
Неизползвани индекси
Всички знаем силата на индекса. Наличието на правилни индекси може да направи светлинни години разлика в скоростта на заявката. Въпреки това, колко от нас поддържат непрекъснато нашите индекси над и извън възстановяването на индекси и реорганизацията? Важно е редовно да изпълнявате индексен скрипт, за да прецените кои индекси всъщност се използват. Аз лично използвам диагностичните заявки на Glenn Berry, за да направя това.
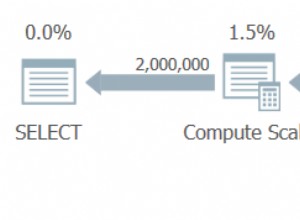
Ще се изненадате да откриете, че някои от вашите индекси изобщо не са прочетени. Тези индекси натоварват ресурсите, особено при много транзакционна таблица. Когато разглеждате резултатите, обърнете внимание на онези индекси, които имат голям брой записвания, съчетани с малък брой четения. В този пример можете да видите, че губя записи. Неклъстерираният индекс е записан до 11 милиона пъти, но е прочетен само два пъти.

Започвам с деактивиране на индексите, които попадат в тази категория, и след това ги пускам, след като потвърдя, че не са възникнали проблеми. Правенето на това упражнение рутинно може значително да намали ненужните I/O записи към вашата система, но имайте предвид, че статистическите данни за използването на вашите индекси са толкова добри, колкото и последното рестартиране, така че се уверете, че сте събирали данни за пълен бизнес цикъл, преди да отпишете индекс като "безполезен".
Липсващи индекси
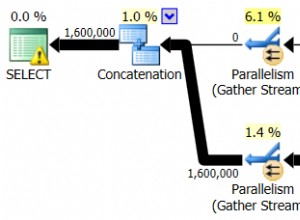
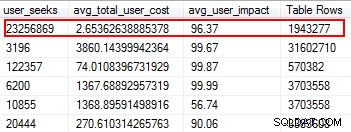
Липсващите индекси са едно от най-лесните за коригиране неща; в крайна сметка, когато стартирате план за изпълнение, той ще ви каже дали не са открити индекси, но това би било полезно. Но изчакайте, надявам се, че не просто добавяте произволно индекси въз основа на това предложение. Правейки това може да създаде дублиращи се индекси и индекси, които може да имат минимална употреба и следователно да губят I/O. Отново, да се върнем към скриптовете на Glenn, той ни дава страхотен инструмент за оценка на полезността на индекс, като предоставя търсене на потребителя, въздействие върху потребителя и брой редове. Обърнете внимание на тези с висока четива, заедно с ниска цена и въздействие. Това е чудесно място за начало и ще ви помогне да намалите I/O за четене.
Неявни реализации
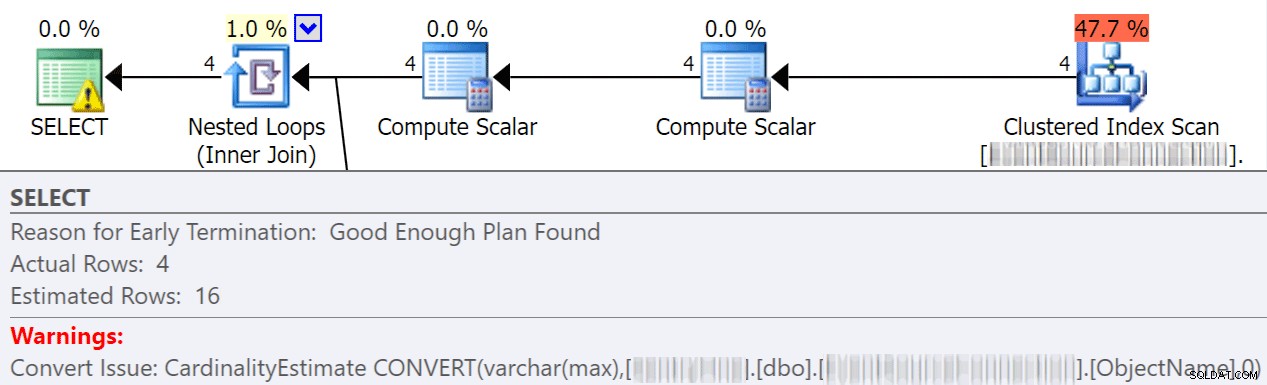
Неявните преобразувания често се случват, когато заявка сравнява две или повече колони с различни типове данни. В примера по-долу системата трябва да извърши допълнително I/O, за да сравни колона varchar(max) с колона nvarchar(4000), което води до имплицитно преобразуване и в крайна сметка до сканиране вместо търсене. Като коригирате таблиците да имат съвпадащи типове данни или просто преобразувате тази стойност преди оценка, можете значително да намалите I/O и да подобрите кардиналността (приблизителните редове, които оптимизаторът трябва да очаква).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias навлиза в много повече подробности в тази страхотна публикация:„Колко скъпи са имплицитните преобразувания отстрани на колони?“
Функции
Едно от най-избегнатите и лесни за коригиране неща, на които съм срещал, което спестява разходи за вход/изход, е премахването на функции от where клаузите. Перфектен пример е сравнение на дати, както е показано по-долу.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Независимо дали е в оператор JOIN или в клауза WHERE, това кара всяка колона да бъде преобразувана, преди да бъде оценена. Като просто преобразувате тези колони преди оценката във временна таблица, можете да елиминирате много ненужни I/O.
Или, още по-добре, изобщо не извършвайте никакви преобразувания (за този конкретен случай Аарон Бертран говори тук за избягването на функции в клаузата where и имайте предвид, че това все още може да е лошо, въпреки че преобразуването към дата може да се премести).
ETL
Отделете време, за да проверите как се зареждат вашите данни. Съкращавате и презареждате таблици? Можете ли вместо това да приложите репликация, реплика на AG само за четене или доставка на журнали? Всички таблици са записани, за да се четат? Как зареждате данните? Чрез съхранени процедури ли е или SSIS? Проучването на неща като това може да намали драстично I/O.
В моята среда открих, че съкращаваме 48 таблици дневно с над 120 милиона реда всяка сутрин. На всичкото отгоре зареждахме 9,6 милиона реда на час. Можете да си представите колко ненужен I/O създаде това. В моя случай внедряването на репликация на транзакции беше моето решение. Веднъж внедрени, имахме много по-малко потребителски оплаквания от забавяне по време на нашето зареждане, което първоначално беше приписано на бавното съхранение.
Поръчайте по и групирайте по
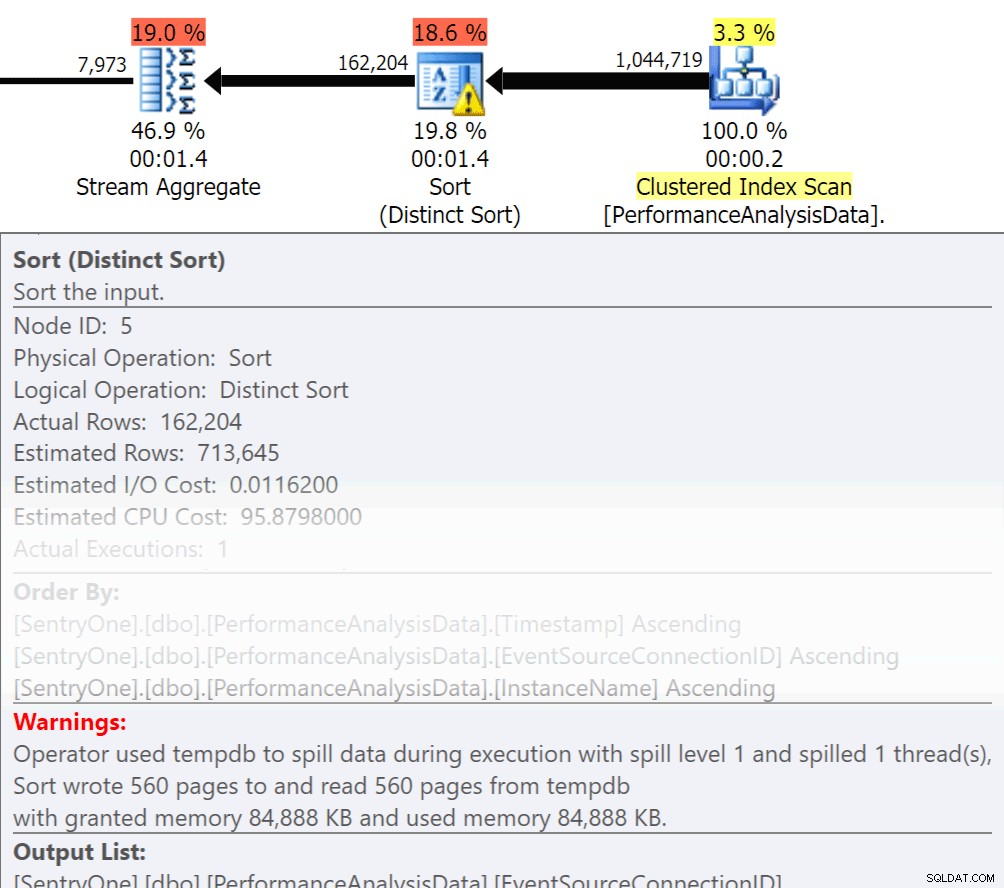 Запитайте се дали тези данни трябва да бъдат върнати по ред? Наистина ли трябва да се групираме в процедурата или можем да се справим с това в отчет или приложение? Операциите Order By и Group By могат да доведат до преливане на четенията върху диска, което причинява допълнителен дисков вход/изход. Ако тези действия са оправдани, уверете се, че имате поддържащи индекси и свежа статистика за колоните, които се сортират или групират. Това ще помогне на оптимизатора по време на създаването на план. Тъй като понякога използваме Order By и Group By във временните таблици. уверете се, че автоматичното създаване на статистика е включено за TEMPDB, както и вашите потребителски бази данни. Колкото по-актуални са статистическите данни, толкова по-добра кардиналност може да получи оптимизаторът, което води до по-добри планове, по-малко преливане и по-малко I/O.
Запитайте се дали тези данни трябва да бъдат върнати по ред? Наистина ли трябва да се групираме в процедурата или можем да се справим с това в отчет или приложение? Операциите Order By и Group By могат да доведат до преливане на четенията върху диска, което причинява допълнителен дисков вход/изход. Ако тези действия са оправдани, уверете се, че имате поддържащи индекси и свежа статистика за колоните, които се сортират или групират. Това ще помогне на оптимизатора по време на създаването на план. Тъй като понякога използваме Order By и Group By във временните таблици. уверете се, че автоматичното създаване на статистика е включено за TEMPDB, както и вашите потребителски бази данни. Колкото по-актуални са статистическите данни, толкова по-добра кардиналност може да получи оптимизаторът, което води до по-добри планове, по-малко преливане и по-малко I/O.
Сега Group By определено има своето място, когато става въпрос за агрегиране на данни, вместо за връщане на тон редове. Но ключът тук е да се намали I/O, добавянето на агрегирането добавя към I/O.
Резюме
Това са само най-важните неща за правене, но чудесно място да започнете да намалявате I/O. Преди да започнете да обвинявате хардуера за проблемите си с латентността, вижте какво можете да направите, за да сведете до минимум натиска върху диска.
За автора
 Моника Ратбън в момента е консултант в Denny Cherry &Associates Consulting и MVP на Microsoft Data Platform. Тя е самотен DBA от 15 години, като работи с всички аспекти на SQL Server и Oracle. Тя пътува, като говори в SQLSaturdays, помагайки на други Lone DBA с техники за това как човек може да върши работата на много хора. Моника е лидер на групата потребители на SQL Server на Hampton Roads и е регионален ментор на Mid-Atlantic Pass. Винаги можете да намерите Моника в Twitter (@SQLEspresso), която раздава полезни съвети и трикове на своите последователи. Когато не е заета с работа, ще я намерите да играе таксиметров шофьор за двете си дъщери напред-назад на уроци по танци.
Моника Ратбън в момента е консултант в Denny Cherry &Associates Consulting и MVP на Microsoft Data Platform. Тя е самотен DBA от 15 години, като работи с всички аспекти на SQL Server и Oracle. Тя пътува, като говори в SQLSaturdays, помагайки на други Lone DBA с техники за това как човек може да върши работата на много хора. Моника е лидер на групата потребители на SQL Server на Hampton Roads и е регионален ментор на Mid-Atlantic Pass. Винаги можете да намерите Моника в Twitter (@SQLEspresso), която раздава полезни съвети и трикове на своите последователи. Когато не е заета с работа, ще я намерите да играе таксиметров шофьор за двете си дъщери напред-назад на уроци по танци.