Работите с разработчик, който отчита бавна производителност за следното извикване на съхранена процедура:
EXEC [dbo].[charge_by_date] '2/28/2013';
Питате какъв проблем вижда разработчикът, но единствената допълнителна информация, която чувате е, че той „работи бавно“. Така че скачате на екземпляра на SQL Server и разглеждате действителния план за изпълнение. Правите това, защото се интересувате не само от това как изглежда планът за изпълнение, но и какъв е прогнозният спрямо действителния брой редове за плана:
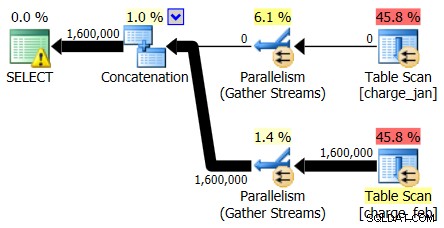
Поглеждайки първо само към операторите на плана, можете да видите няколко забележителни подробности:
- Има предупреждение в основния оператор
- Има сканиране на таблицата и за двете таблици, посочени на ниво лист (charge_jan и charge_feb) и се чудите защо и двете все още са купища и нямат клъстерирани индекси
- Виждате, че има само редове, преминаващи през таблицата charge_feb, а не таблицата charge_jan
- Виждате паралелни зони в плана
Що се отнася до предупреждението в основния итератор, задържате курсора на мишката върху него и виждате, че липсват предупреждения за индекси с препоръка за следните индекси:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Питате първоначалния разработчик на база данни защо няма клъстериран индекс и отговорът е „Не знам“.
Продължавайки разследването, преди да направите каквито и да било промени, поглеждате раздела Plan Tree в SQL Sentry Plan Explorer и наистина виждате, че има значителни отклонения между прогнозните спрямо действителните редове за една от таблиците:

Изглежда има два проблема:
- Подценяване за редове в сканирането на таблицата charge_jan
- Надценяване за редове в сканирането на таблицата charge_feb
Така че оценките за кардиналност са изкривени и се чудите дали това е свързано с подслушване на параметри. Решавате да проверите компилираната стойност на параметъра и да я сравните със стойността на параметъра по време на изпълнение, която можете да видите в раздела Параметри:

Наистина има разлики между стойността на времето за изпълнение и компилираната стойност. Копирате базата данни в среда за тестване, подобна на prod, и след това тествате изпълнението на съхранената процедура със стойността на времето за изпълнение първо 28.02.2013 г. и след това 31.1.2013 г.
Плановете за 28.02.2013 г. и 31.1.2013 г. имат идентични форми, но различни действителни потоци от данни. Планът за 28.02.2013 г. и оценките за кардиналите бяха както следва:
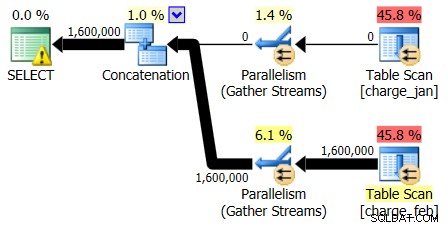

И докато планът от 28.02.2013 г. не показва проблем с оценката на кардиналността, планът от 31.1.2013 г. прави:
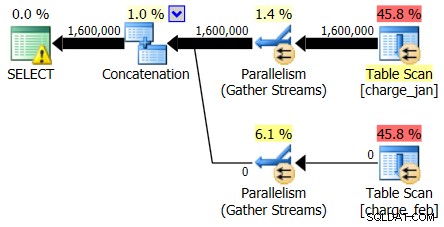

Така че вторият план показва същото надценяване и подценяване, просто обърнато от първоначалния план, който разгледахте.
Решавате да добавите предложените индекси към тестовата среда, подобна на prod, както за таблиците charge_jan, така и за charge_feb и вижте дали това изобщо помага. Изпълнявайки съхранените процедури в ред януари/февруари, виждате следните нови форми на плана и свързаните оценки за мощността:
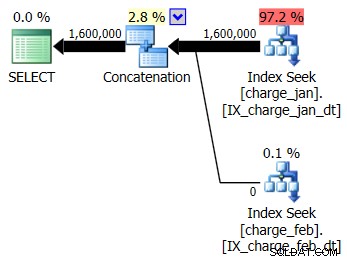

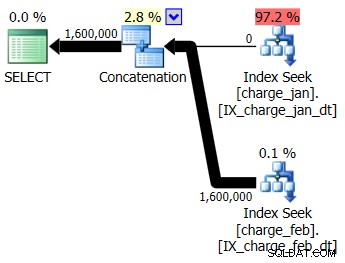

Новият план използва операция Index Seek от всяка таблица, но все още виждате нулеви редове, течащи от една таблица, а не от другата, и все още виждате изкривявания на оценката на мощността въз основа на подслушване на параметри, когато стойността по време на изпълнение е в различен месец от компилирането времева стойност.
Вашият екип има политика да не добавя индекси без доказателство за достатъчна полза и свързано регресионно тестване. Вие решавате за момента да премахнете неклъстерираните индекси, които току-що създадохте. Въпреки че не се справяте веднага с липсващите клъстери index, решавате, че ще се погрижите за това по-късно.
В този момент разбирате, че трябва да погледнете по-нататък в дефиницията на съхранената процедура, която е както следва:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
След това разглеждате дефиницията на обекта charge_view:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
Изгледът препраща към данни за таксуване, които са разделени в различни таблици по дата. И тогава се чудите дали второто изкривяване на плана за изпълнение на заявка може да бъде предотвратено чрез промяна на дефиницията на съхранената процедура.
Може би ако оптимизаторът знае по време на изпълнение каква е стойността, проблемът с оценката на кардиналността ще изчезне и ще подобри цялостната производителност?
Продължавате и предефинирате извикването на съхранената процедура, както следва, като добавяте намек за RECOMPILE (знайки, че сте чували също, че това може да увеличи използването на процесора, но тъй като това е тестова среда, се чувствате сигурни, ако опитате):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
След това изпълнявате отново съхранената процедура, като използвате стойността 31.1.2013 г. и след това стойността 28.2.2013 г.
Формата на плана остава същата, но сега проблемът с оценката на кардиналността е премахнат.
Данните за оценка на кардиналитета от 31.01.2013 г. показват:

И данните за кардиналност от 28.02.2013 г. показват:

Това ви прави щастливи за момент, но след това разбирате, че продължителността на цялостното изпълнение на заявката изглежда сравнително същата, както беше преди. Започвате да се съмнявате, че разработчикът ще бъде доволен от вашите резултати. Решихте изкривяването на оценката на кардиналността, но без очакваното повишаване на производителността, не сте сигурни дали сте помогнали по някакъв смислен начин.
В този момент осъзнавате, че планът за изпълнение на заявката е само подмножество от информацията, която може да ви е необходима, и затова разширявате допълнително проучването си, като погледнете раздела Таблица I/O. Виждате следния изход за изпълнението от 31.1.2013 г.:

И за изпълнението от 28.02.2013 г. виждате подобни данни:

Точно в този момент се чудите дали операциите за достъп до данни за и двете таблици са необходими във всеки план. Ако оптимизаторът знае, че имате нужда само от януарски редове, защо изобщо да имате достъп до февруари и обратно? Освен това помните, че оптимизаторът на заявки няма гаранции, че няма действителните редове от другите месеци в „грешната“ таблица, освен ако такива гаранции не са били изрично направени чрез ограничения върху самата таблица.
Проверявате дефинициите на таблицата чрез sp_help за всяка таблица и не виждате никакви ограничения, дефинирани за нито една таблица.
Така че като тест добавяте следните две ограничения:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Изпълнявате повторно съхранените процедури и виждате следните форми на планове и оценки за мощност.
31.1.2013 г. изпълнение:
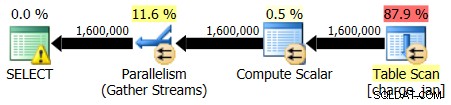

28.02.2013 г. изпълнение:


Поглеждайки отново към Table I/O, виждате следния изход за изпълнението от 31.1.2013 г.:

И за изпълнението от 28.02.2013 г. виждате подобни данни, но за таблицата charge_feb:

Спомняйки си, че имате RECOMPILE все още в дефиницията на съхранената процедура, опитайте да го премахнете и да видите дали виждате същия ефект. След като направите това, виждате връщането на достъп до две таблици, но без действителни логически показания за таблицата, която няма редове в нея (в сравнение с оригиналния план без ограниченията). Например, изпълнението от 31.1.2013 г. показа следния изход на Таблица I/O:

Решавате да продължите напред с тестване на натоварването на новите ограничения CHECK и решението RECOMPILE, като премахвате достъпа до таблицата изцяло от плана (и свързаните оператори на плана). Вие също се подготвяте за дебат относно ключа за клъстериран индекс и подходящ поддържащ неклъстериран индекс, който ще побере по-широк набор от работни натоварвания, които в момента имат достъп до свързаните таблици.