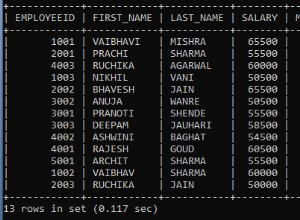
Тази статия е четвъртата част от поредицата за грешки в T-SQL, клопки и най-добри практики. По-рано разглеждах детерминизма, подзаявките и присъединяванията. Фокусът на статията от този месец са бъгове, клопки и най-добри практики, свързани с функциите на прозорците. Благодаря Ерланд Сомарског, Аарон Бертран, Алехандро Меса, Умачандар Джаячандран (UC), Фабиано Невес Аморим, Милош Радивоевич, Саймън Сабин, Адам Мачаник, Томас Гросер, Чан Минг Ман и Пол Уайт за предлагането на вашите идеи!
В моите примери ще използвам примерна база данни, наречена TSQLV5. Тук можете да намерите скрипта, който създава и попълва тази база данни, както и нейната диаграма за ER тук.
Има две често срещани клопки, включващи функциите на прозореца, като и двете са резултат от противоинтуитивни имплицитни настройки по подразбиране, наложени от стандарта SQL. Една клопка е свързана с изчисленията на текущите суми, където получавате рамка на прозорец с опцията имплицитна RANGE. Друг капан е донякъде свързан, но има по-сериозни последици, включващи имплицитна дефиниция на рамка за функциите FIRST_VALUE и LAST_VALUE.
Прозоречна рамка с неявна опция RANGE
Първият ни капан включва изчисляването на текущите суми с помощта на обобщена функция на прозореца, където изрично указвате клаузата за реда на прозореца, но не указвате изрично единицата на рамката на прозореца (ROWS или RANGE) и свързаната с нея степен на рамката на прозореца, например ROWS НЕОГРАНИЧЕН ПРЕДИШЕН. Неявното подразбиране е противоинтуитивно и последствията от него могат да бъдат изненадващи и болезнени.
За да демонстрирам този капан, ще използвам таблица, наречена Транзакции, съдържаща два милиона транзакции по банкови сметки с кредити (положителни стойности) и дебити (отрицателни стойности). Изпълнете следния код, за да създадете таблицата за транзакции и да я попълните с примерни данни:
ЗАДАДЕТЕ NOCOUNT ON; ИЗПОЛЗВАЙТЕ TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip ИЗПУСКАНЕ НА ТАБЛИЦА, АКО СЪЩЕСТВУВА dbo.Transactions; CREATE TABLE dbo.Transactions ( actid INT NOT NULL, tranid INT NOT NULL, val MONEY NOT NULL, CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid) -- създава POC индекс); ДЕКЛАРИРАНЕ @num_partitions КАТО INT =100, @rows_per_partition КАТО INT =20000; INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val) SELECT NP.n, RPP.n, (ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM( NEWID())%5)) ОТ dbo.GetNums(1, @num_partitions) КАТО NP CROSS JOIN dbo.GetNums(1, @rows_per_partition) КАТО RPP;
Нашата клопка има както логическа страна с потенциален логически бъг, така и страна на производителността с наказание за изпълнение. Наказанието за производителност е от значение само когато функцията на прозореца е оптимизирана с оператори за обработка в режим на ред. SQL Server 2016 въвежда оператора Window Aggregate в пакетен режим, който премахва частта от клопката за намаляване на производителността, но преди SQL Server 2019 този оператор се използва само ако имате индекс на columnstore, присъстващ в данните. SQL Server 2019 въвежда пакетен режим при поддръжка на rowstore, така че можете да получите обработка в пакетен режим, дори ако няма налични индекси на columnstore в данните. За да демонстрирате намаляването на производителността при обработката в режим на ред, ако изпълнявате примерните кодове в тази статия на SQL Server 2019 или по-нова версия или на Azure SQL база данни, използвайте следния код, за да зададете нивото на съвместимост на базата данни на 140, така че все още да не активирате пакетния режим в магазина на редове:
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL =140;
Използвайте следния код, за да включите времето и I/O статистиката в сесията:
ЗАДАЙТЕ ВРЕМЕ НА СТАТИСТИКАТА, ВКЛЮЧЕНО IO;
За да избегнете чакането на два милиона реда да бъдат отпечатани в SSMS, предлагам да стартирате примерните кодове в този раздел с включена опция Отхвърляне на резултатите след изпълнение (отидете на Опции за заявка, Резултати, Решетка и отметнете Отхвърляне на резултатите след изпълнение).
Преди да стигнем до клопката, помислете за следната заявка (наречете я Заявка 1), която изчислява салдото по банковата сметка след всяка транзакция чрез прилагане на текуща сума с помощта на агрегатна функция на прозорец с изрична спецификация на рамката:
ИЗБЕРЕТЕ actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИ ) КАТО баланс ОТ dbo.Transactions;
Планът за тази заявка, използващ обработка в режим на ред, е показан на Фигура 1.
 Фигура 1:План за заявка 1, обработка в режим на ред
Фигура 1:План за заявка 1, обработка в режим на ред
Планът изтегля предварително подредените данни от клъстерирания индекс на таблицата. След това използва операторите Segment и Sequence Project, за да изчисли номерата на редовете, за да разбере кои редове принадлежат на рамката на текущия ред. След това използва операторите Segment, Window Spool и Stream Aggregate, за да изчисли агрегатната функция на прозореца. Операторът Window Spool се използва за пулиране на редовете на рамката, които след това трябва да бъдат агрегирани. Без никаква специална оптимизация, планът би трябвало да запише на ред всичките си приложими редове на рамката в макарата и след това да ги обобщи. Това би довело до квадратична, или N, сложност. Добрата новина е, че когато рамката започне с UNBOUNDED PRECEDING, SQL Server идентифицира случая като бърза пътека случай, в който просто взема текущата сума на предишния ред и добавя стойността на текущия ред, за да изчисли текущата сума на текущия ред, което води до линейно мащабиране. В този бърз режим планът записва само два реда в шпулата на входен ред – един с агрегата и един с детайлите.
Window Spool може да бъде физически реализиран по един от двата начина. Или като бърза спула в паметта, която е специално проектирана за функции на прозорци, или като бавна на диска макара, която по същество е временна таблица в tempdb. Ако броят на редовете, които трябва да бъдат записани в пулта на основен ред може да надхвърли 10 000 или ако SQL Server не може да предвиди числото, той ще използва по-бавната на диска пул. В нашия план за заявка имаме точно два реда, записани в спула за всеки основен ред, така че SQL Server използва пулта в паметта. За съжаление, няма начин да разберете от плана какъв вид макара получавате. Има два начина да разберете това. Едното е да използвате разширено събитие, наречено window_spool_ondisk_warning. Друга опция е да активирате STATISTICS IO и да проверите броя на отчетените логически четения за таблица, наречена Worktable. Число, по-голямо от нула, означава, че имате макарата на диска. Нула означава, че имате макарата в паметта. Ето статистическите данни за I/O за нашата заявка:
Логически показания на таблица „Работна таблица“:0. Логически показания на таблица „Транзакции“:6208.Както можете да видите, използвахме макарата в паметта. Това обикновено е случаят, когато използвате прозоречната рамка ROWS с UNBOUNDED PRECEDING като първи разделител.
Ето статистическите данни за времето за нашата заявка:
Процесорно време:4297 ms, изминало време:4441 ms.Тази заявка отне около 4,5 секунди, за да завърши на моята машина с отхвърлени резултати.
Сега за улова. Ако използвате опцията RANGE вместо ROWS, със същите разделители, може да има фина разлика в значението, но голяма разлика в производителността в режим на ред. Разликата в значението е от значение само ако нямате пълна поръчка, т.е. ако поръчвате по нещо, което не е уникално. Опцията РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДШЕСТВУВАЩА спира с текущия ред, така че в случай на връзки, изчислението е недетерминистично. Обратно, опцията RANGE UNLOUNDED PRECEDING изглежда напред от текущия ред и включва връзки, ако има такива. Той използва подобна логика като опцията TOP WITH TIES. Когато имате пълно подреждане, т.е. поръчвате по нещо уникално, няма връзки за включване и следователно ROWS и RANGE стават логически еквивалентни в такъв случай. Проблемът е, че когато използвате RANGE, SQL Server винаги използва буфера на диска при обработка в режим на ред, тъй като при обработката на даден ред не може да предвиди колко още реда ще бъдат включени. Това може да доведе до сериозно увреждане на производителността.
Помислете за следната заявка (наречете я Заявка 2), която е същата като Заявка 1, използвайки само опцията RANGE вместо ROWS:
ИЗБЕРЕТЕ actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid RANGE НЕОГРАНИЧЕН ПРЕДИШЕН ) КАТО баланс ОТ dbo.Transactions;
Планът за тази заявка е показан на Фигура 2.
 Фигура 2:План за заявка 2, обработка в режим на ред
Фигура 2:План за заявка 2, обработка в режим на ред
Заявка 2 е логически еквивалентна на заявка 1, защото имаме пълен ред; въпреки това, тъй като използва RANGE, той се оптимизира с макарата на диска. Обърнете внимание, че в плана за заявка 2, Window Spool изглежда по същия начин, както в плана за заявка 1, а прогнозните разходи са същите.
Ето статистическите данни за времето и I/O за изпълнение на заявка 2:
Време на процесора:19515 ms, изминало време:20201 ms.Логически показания на таблица „Работна таблица“:12044701. Логически показания на таблица „Транзакции“:6208.
Забележете големия брой логически четения срещу Worktable, което показва, че сте получили макарата на диска. Времето за изпълнение е повече от четири пъти по-дълго, отколкото за заявка 1.
Ако мислите, че ако случаят е такъв, просто ще избегнете използването на опцията RANGE, освен ако наистина не трябва да включите връзки, това е добро мислене. Проблемът е, че ако използвате прозоречна функция, която поддържа рамка (агрегирани, FIRST_VALUE, LAST_VALUE) с изрична клауза за ред на прозореца, но без споменаване на елемента на рамката на прозореца и свързаната с него степен, получавате по подразбиране RANGE UNBOUNDED PRECEDING . Това подразбиране е продиктувано от стандарта SQL и стандартът го избра, защото обикновено предпочита по-детерминистични опции като стандартни. Следната заявка (наречете я Заявка 3) е пример, който попада в този капан:
ИЗБЕРЕТЕ actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid ) КАТО баланс ОТ dbo.Transactions;
Често хората пишат по този начин, като приемат, че получават РЕДОВЕ НЕОГРАНИЧЕН ПРЕДШЕСТВАЩ по подразбиране, без да осъзнават, че всъщност получават ОБЕЗГРАНИЧЕН ПРЕДПРЕД. Работата е там, че тъй като функцията използва пълен ред, вие получавате същия резултат като при ROWS, така че не можете да разберете, че има проблем от резултата. Но показателите за ефективност, които ще получите, са като за заявка 2. Виждам, че хората попадат в този капан през цялото време.
Най-добрата практика за избягване на този проблем е в случаите, когато използвате функция за прозорец с рамка, да бъдете изрични относно единицата на рамката на прозореца и нейната степен и като цяло предпочитате ROWS. Запазете използването на RANGE само в случаите, когато поръчката не е уникална и трябва да включите връзки.
Помислете за следната заявка, илюстрираща случай, когато има концептуална разлика между ROWS и RANGE:
ИЗБЕРЕТЕ дата на поръчка, идентификатор на поръчка, val, SUM(val) НАД( ПОРЪЧКА ПО дата на поръчка РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИ ) КАТО суми, SUM(val) НАД( ПОРЪЧКА ПО РЪДКА ЗА дата на поръчка ДИАПАЗОН НЕОГРАНИЧЕН ПРЕДИШЕН ) КАТО sumrange FROM Sales.OrderValues<поръчка; /предварително>Тази заявка генерира следния изход:
orderdate orderid val sumrows sumrange ---------- -------- -------- -------- -------- - 2017-07-04 10248 440.00 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2303.40 2017-07-08 10250 1552.60 3856.00 4510.06 2017-07-08 10251 654.06 4510.06 4510.06 2017-07-09 10252 3597.90 8107.96 8107.96 ...Наблюдавайте разликата в резултатите за редовете, където една и съща дата на поръчка се появява повече от веднъж, какъвто е случаят за 8 юли 2017 г. Забележете как опцията ROWS не включва връзки и следователно е недетерминистична и как опцията RANGE прави включва връзки и следователно винаги е детерминистичен.
Съмнително е обаче, ако на практика имате случаи, в които поръчвате от нещо, което не е уникално, и наистина се нуждаете от включване на връзки, за да направите изчислението детерминистично. Това, което вероятно е много по-често срещано на практика, е да направите едно от двете неща. Единият е да прекъснете връзките, като добавите нещо към подреждането на прозореца, за да го направи уникален и по този начин да доведе до детерминирано изчисление, като така:
ИЗБЕРЕТЕ дата на поръчка, идентификатор на поръчка, val, SUM(val) НАД( ПОРЪЧКА ПО дата на поръчка, идентификатор на поръчката РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИ ) КАТО текуща сума ОТ Sales.OrderValues ORDER BY orderdate;Тази заявка генерира следния изход:
orderdate orderid val runningsum ---------- -------- --------- ----------- 04.07.2017 г. 10248 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2017-07-08 10250 1552.60 3856.00 2017-07-08 10251 654.06 4510.06 2017-07-09 10252 3597.90 8107.96 ...Друга възможност е да приложите предварително групиране, в нашия случай, по дата на поръчка, така:
ИЗБЕРЕТЕ дата на поръчка, SUM(val) КАТО общ ден, SUM(SUM(val)) НАД( ПОРЪЧКА ПО дата на поръчка РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИ ) КАТО текуща сума ОТ Sales.OrderValues GROUP BY orderdate ORDER BY orderdate;Тази заявка генерира следния изход, където всяка дата на поръчка се появява само веднъж:
<предварителна> дата на поръчката денобща текуща сума ---------- --------- ----------- 04.07.2017 440,00 440,00 2017-07-05 1863,40 2303,40 2017-07-08 2206,66 4510,06 2017-07-09 3597,90 8107,96 ...Във всеки случай, не забравяйте да запомните най-добрата практика тук!
Добрата новина е, че ако работите на SQL Server 2016 или по-нова версия и имате индекс на columnstore в данните (дори ако това е фалшив филтриран индекс на columnstore), или ако работите на SQL Server 2019 или по-нова версия, или в Azure SQL база данни, независимо от наличието на индекси на columnstore, и трите гореспоменати заявки се оптимизират с оператора Window Aggregate в пакетен режим. С този оператор много от неефективността на обработката в режим на ред са елиминирани. Този оператор изобщо не използва шпула, така че няма проблем със шпула в паметта и на диска. Той използва по-сложна обработка, при която може да приложи множество паралелни преминавания върху прозореца от редове в паметта както за ROWS, така и за RANGE.
За да демонстрирате използването на оптимизацията в пакетен режим, уверете се, че нивото на съвместимост на вашата база данни е настроено на 150 или по-високо:
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL =150;Стартирайте отново заявка 1:
ИЗБЕРЕТЕ actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid РЕДОВЕ НЕОГРАНИЧЕНИ ПРЕДИ ) КАТО баланс ОТ dbo.Transactions;Планът за тази заявка е показан на Фигура 3.
Фигура 3:План за заявка 1, обработка в пакетен режим
Ето статистическите данни за ефективността, които получих за тази заявка:
Време на процесора:937 ms, изминало време:983 ms.
Логически показания на таблицата „Транзакции“:6208.Времето за изпълнение спадна до 1 секунда!
Стартирайте отново заявка 2 с изричната опция RANGE:
ИЗБЕРЕТЕ actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid RANGE НЕОГРАНИЧЕН ПРЕДИШЕН ) КАТО баланс ОТ dbo.Transactions;Планът за тази заявка е показан на Фигура 4.
Фигура 2:План за заявка 2, обработка в пакетен режим
Ето статистическите данни за ефективността, които получих за тази заявка:
Процесорно време:969 ms, изминало време:1048 ms.
Логически показания на таблицата „Транзакции“:6208.Производителността е същата като при заявка 1.
Стартирайте отново заявка 3 с неявната опция RANGE:
ИЗБЕРЕТЕ actid, tranid, val, SUM(val) OVER( PARTITION BY actid ORDER BY tranid ) КАТО баланс ОТ dbo.Transactions;Планът и номерата на производителността, разбира се, са същите като за заявка 2.
Когато сте готови, изпълнете следния код, за да изключите статистиката за ефективността:
ЗАДАЙТЕ ВРЕМЕ НА СТАТИСТИКАТА, ИЗКЛЮЧЕТЕ IO;Също така, не забравяйте да изключите опцията Отхвърляне на резултатите след изпълнение в SSMS.
Неявна рамка с FIRST_VALUE и LAST_VALUE
Функциите FIRST_VALUE и LAST_VALUE са функции за изместване на прозореца, които връщат съответно израз от първия или последния ред в рамката на прозореца. Трудната част при тях е, че често, когато хората ги използват за първи път, те не осъзнават, че поддържат рамка, а по-скоро си мислят, че се отнасят за целия дял.
Помислете за следния опит за връщане на информация за поръчка плюс стойностите на първата и последната поръчка на клиента:
ИЗБЕРЕТЕ custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) КАТО firstval, LAST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS lastval FROM Safe. Стойности на поръчката ORDER BY custid, orderdate, orderid;Ако погрешно смятате, че тези функции работят върху целия дял на прозореца, което е убеждението на много хора, които използват тези функции за първи път, естествено очаквате FIRST_VALUE да върне стойността на поръчката на първата поръчка на клиента и LAST_VALUE да върне стойност на поръчката на последната поръчка на клиента. На практика обаче тези функции поддържат рамка. Като напомняне, с функции, които поддържат рамка, когато посочите клаузата за реда на прозореца, но не и единицата на рамката на прозореца и свързаната с нея степен, по подразбиране получавате RANGE UNBOUNDED PRECEDING. С функцията FIRST_VALUE ще получите очаквания резултат, но ако заявката ви бъде оптимизирана с оператори в режим на ред, вие ще платите неустойката за използване на буфера на диска. С функцията LAST_VALUE е още по-лошо. Не само, че ще платите неустойката за макарата на диска, но вместо да получите стойността от последния ред в дяла, ще получите стойността от текущия ред!
Ето изхода от горната заявка:
custid orderdate orderid val firstval lastval ------- ---------- --------- ---------- ------ ------------ 1 2018-08-25 10643 814,50 814,50 814,50 1 2018-10-03 10692 878,00 878,00 1 2018-10-30 0 0 0 1 0 0 0 10835 845.80 814.50 845.80 1 2019-03-16 10952 471.20 814.50 471.20 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 88.80 2 2018-08-08 10625 479.75 88.80 479.75 2 2018-11-28 10759 320.00 88.80 320.00 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 403.20 3 2018-04-15 10507 749.06 403.20 749.06 3 2018-05-13 10535 1940.85 403.20 1940.85 3 2018-06-19 10573 2082,00 403,20 2082,00 3 2018-09-22 10677 813,37 403,20 813,37 3 2018-09-25 10682 375,50 403,20 375,50 3 2019-01-28 10856 660,00 403,20 660,00 ...Често, когато хората виждат такъв изход за първи път, те мислят, че SQL Server има грешка. Но разбира се, не става; това е просто стандартът по подразбиране на SQL. Има грешка в заявката. Осъзнавайки, че има включена рамка, искате да сте изрични относно спецификацията на рамката и да използвате минималния кадър, който улавя реда, който търсите. Също така се уверете, че използвате модула ROWS. Така че, за да получите първия ред в дяла, използвайте функцията FIRST_VALUE с рамката РЕДОВЕ МЕЖДУ НЕЗГРАНИЧЕН ПРЕДХОДЕН И ТЕКУЩ РЕД. За да получите последния ред в дяла, използвайте функцията LAST_VALUE с рамката РЕДОВЕ МЕЖДУ ТЕКУЩИЯ РЕД И НЕОГРАНИЧЕНО СЛЕДВАНЕ.
Ето нашата преработена заявка с отстранена грешка:
ИЗБЕРЕТЕ custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid РЕДОВЕ МЕЖДУ НЕОГРАНИЧЕН ПРЕДШЕСТВЕН И ТЕКУЩ РЕД ) КАТО firstval, LAST_VALUE(val) OVER( CUSTITION order BY ORD orderid РЕДОВЕ МЕЖДУ ТЕКУЩ РЕД И НЕЗГРАНИЧЕН СЛЕД ) КАТО lastval FROM Sales.OrderValues ORDER BY custid, orderdate, orderid;Този път получавате правилния резултат:
custid orderdate orderid val firstval lastval ------- ---------- --------- ---------- ------ ---- ---------- 1 2018-08-25 10643 814,50 814,50 933,50 1 2018-10-03 10692 878,00 814,50 1 2018-10-30 10 10 10 10 10 10835 845.80 814.50 933.50 1 2019-03-16 10952 471.20 814.50 933.50 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 514.40 2 2018-08-08 10625 479.75 88.80 514.40 2 2018-11-28 10759 320.00 88.80 514.40 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 660.00 3 2018-04-15 10507 749.06 403.20 660.00 3 2018-05-13 10535 1940.85 403.20 660.00 3 2018-06-19 10573 2082,00 403,20 660,00 3 2018-09-22 10677 813,37 403,20 660,00 3 2018-09-25 10682 375,50 403,20 660,00 3 2019-01-28 10856 660,00 403,20 660,00 ...Човек се чуди каква е била мотивацията стандартът дори да поддържа рамка с тези функции. Ако се замислите, най-вече ще ги използвате, за да получите нещо от първия или последния ред в дяла. Ако имате нужда от стойността, да речем, два реда преди текущия, вместо да използвате FIRST_VALUE с рамка, която започва с 2 PRECEDING, не е ли много по-лесно да използвате LAG с изрично отместване от 2, като така:
ИЗБЕРЕТЕ custid, orderdate, orderid, val, LAG(val, 2) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) КАТО prevtwoval FROM Sales.OrderValues ORDER BY custid, orderdate, orderid;Тази заявка генерира следния изход:
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ------- ---- 1 2018-08-25 10643 814.50 NULL 1 2018-10-03 10692 878.00 NULL 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 NULL 2 2018-08-08 10625 479.75 NULL 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10365 403.20 NULL 3 2018-04-15 10507 749.06 NULL 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 -01-28 10856 660,00 813,37 ...Очевидно има семантична разлика между горното използване на функцията LAG и FIRST_VALUE с рамка, която започва с 2 PRECEDING. При първото, ако ред не съществува в желаното отместване, получавате NULL по подразбиране. С последното все още получавате стойността от първия ред, който присъства, т.е. стойността от първия ред в дяла. Помислете за следната заявка:
SELECT custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid РЕДОВЕ МЕЖДУ 2 ПРЕДИШНИ И ТЕКУЩ РЕД ) КАТО prevtwoval FROM Sales.OrderValues ORDERBYdacustid поръчка, поръчка; предварително>Тази заявка генерира следния изход:
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ------- ---- 1 2018-08-25 10643 814.50 814.50 1 2018-10-03 10692 878.00 814.50 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-03-16 10952 471.20 330.00 1 2019-03-16 10952 471.20 330.00 1 2019-03-16 10952 471.20 330. 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 88.80 2 2018-08-08 10625 479.75 88.80 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10625 479.75 88.80 2 2018-11-28 10759 320,00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10625 479.75 88.80 2 2018-11-28 10759 320.00 88.80 2 10365 403.20 403.20 3 2018-04-15 10507 749.06 403.20 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 -01-28 10856 660,00 813,37 ...Обърнете внимание, че този път няма NULL в изхода. Така че има някаква стойност в поддържането на рамка с FIRST_VALUE и LAST_VALUE. Просто се уверете, че помните най-добрата практика винаги да сте изрични относно спецификацията на рамката с тези функции и да използвате опцията ROWS с минималната рамка, която съдържа реда, който търсите.
Заключение
Тази статия се фокусира върху грешки, клопки и най-добри практики, свързани с функциите на прозорците. Не забравяйте, че както функциите за агрегатиране на прозореца, така и функциите за изместване на прозореца FIRST_VALUE и LAST_VALUE поддържат рамка и че ако посочите клаузата за ред на прозореца, но не посочите единицата на рамката на прозореца и свързаната с нея степен, получавате RANGE UNBOUNDED PRECEDING от по подразбиране. Това води до намаляване на производителността, когато заявката бъде оптимизирана с оператори в режим на ред. С функцията LAST_VALUE това води до получаване на стойностите от текущия ред вместо от последния ред в дяла. Не забравяйте да бъдете изрични относно рамката и като цяло да предпочитате опцията ROWS пред RANGE. Чудесно е да видите подобренията в производителността с оператора Window Aggregate в пакетен режим. Когато е приложимо, най-малкото клопката на производителността е елиминирана.