Миналата седмица публикувах публикация, наречена #BackToBasics :DATEFROMPARTS() , където показах как да използвам тази функция от 2012+ за по-чисти заявки за период от време, които могат да се саргират. Използвах го, за да демонстрирам, че ако използвате предикат за дата с отворен край и имате индекс в съответната колона дата/час, можете да получите много по-добро използване на индекса и по-ниско I/O (или, в най-лошия случай , същото, ако търсенето не може да се използва по някаква причина или ако не съществува подходящ индекс):
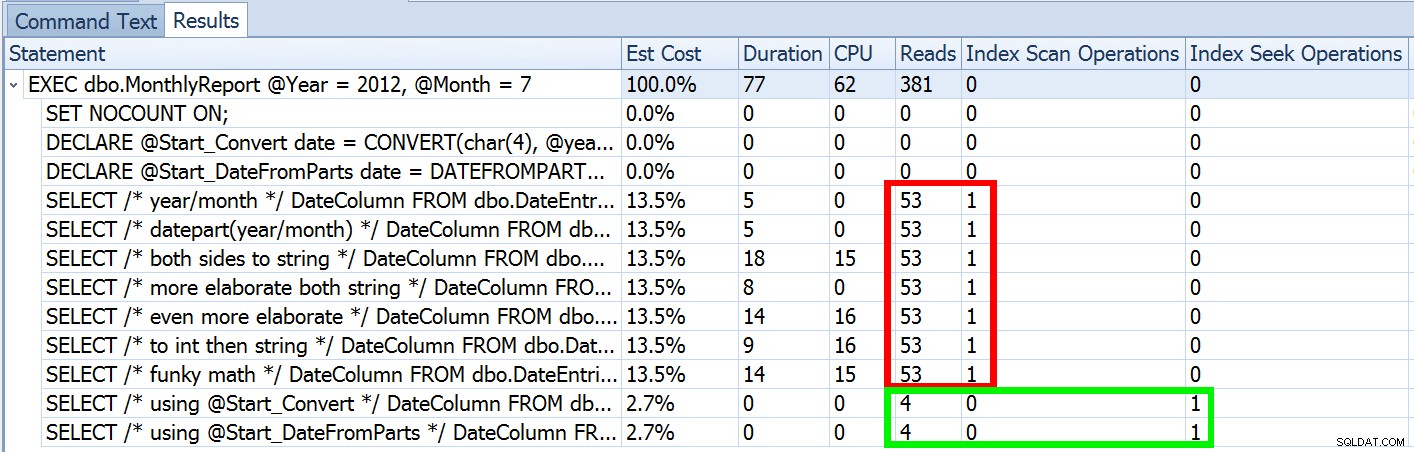
Но това е само част от историята (и за да е ясно, DATEFROMPARTS() технически не се изисква за търсене, просто е по-чисто в този случай). Ако намалим малко, забелязваме, че нашите оценки далеч не са точни, сложност, която не исках да представям в предишната публикация:
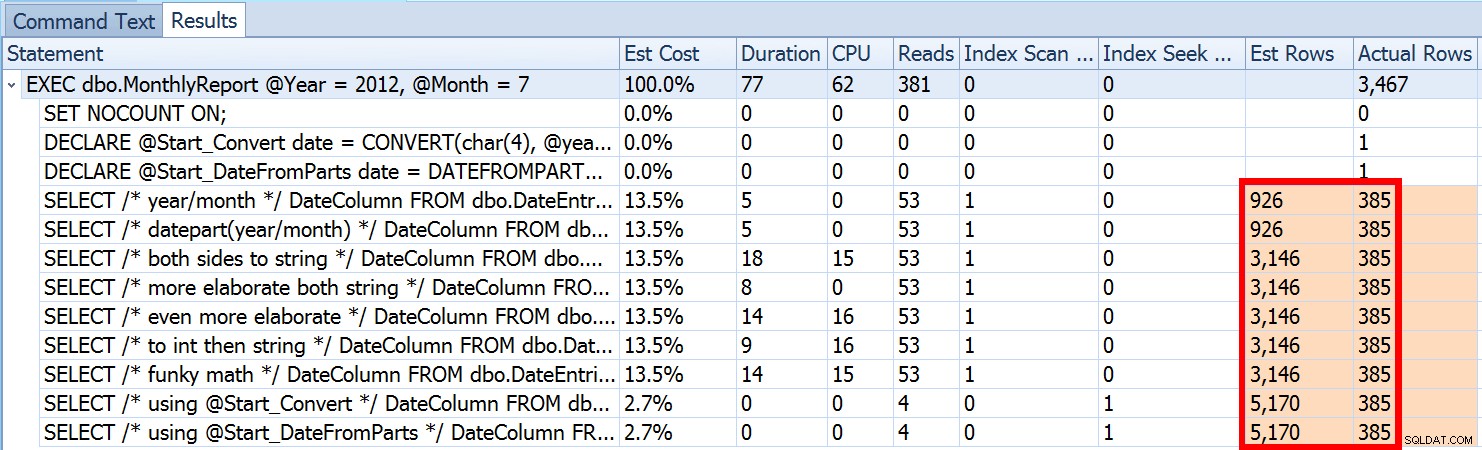
Това не е необичайно както за предикатите на неравенството, така и за принудителното сканиране. И разбира се, дали методът, който предложих, нямаше да даде най-неточните статистически данни? Ето основния подход (можете да получите схемата на таблицата, индексите и примерните данни от предишната ми публикация):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Сега неточните оценки не винаги ще бъдат проблем, но могат да причинят проблеми с неефективния избор на план в двете крайности. Един план може да не е оптимален, когато избраният диапазон ще даде много малък или много голям процент от таблицата или индекса и това може да стане много трудно за SQL Server да предвиди кога разпределението на данните е неравномерно. Джоузеф Сак очерта по-типичните неща, които лошите оценки могат да повлияят в публикацията си „Десет често срещани заплахи за качеството на плана за изпълнение:“
„[…] лошите оценки на редовете могат да повлияят на различни решения, включително избор на индекс, операции за търсене и сканиране, паралелно срещу серийно изпълнение, избор на алгоритъм за присъединяване, избор на вътрешно срещу външно физическо свързване (напр. изграждане срещу сонда), генериране на шпула, търсене на отметки спрямо пълен клъстерен или хеп достъп до таблици, избор на поток или хеш агрегат и дали модификацията на данни използва широк или тесен план.“
Има и други, като например предоставянето на памет, които са твърде големи или твърде малки. Той продължава да описва някои от най-честите причини за лоши оценки, но основната причина в този случай липсва в неговия списък:предположенията. Тъй като използваме локална променлива за промяна на входящия int параметри към една локална date променлива, SQL Server не знае каква ще бъде стойността, така че прави стандартизирани предположения за мощност въз основа на цялата таблица.
Видяхме по-горе, че оценката за предложения от мен подход е 5170 реда. Сега знаем, че с предикат на неравенство и със SQL Server, който не знае стойностите на параметрите, той ще познае 30% от таблицата. 31,645 * 0.3 не е 5,170. Нито е 31,465 * 0.3 * 0.3 , когато си спомним, че всъщност има два предиката, работещи срещу една и съща колона. И така, откъде идва тази стойност от 5170?
Както Пол Уайт описва в публикацията си „Оценка на кардиналността за множество предикати“, новият оценител на мощността в SQL Server 2014 използва експоненциално отстъпление, така че умножава броя на редовете на таблицата (31 465) по селективността на първия предикат (0,3) и след това умножава това по квадратния корен на селективността на втория предикат (~0,547723).
31 645 * (0,3) * SQRT (0,3) ~=5 170,227И така, сега можем да видим къде SQL Server излезе с оценката си; какви са някои от методите, които можем да използваме, за да направим нещо по въпроса?
- Подаване на параметри за дата. Когато е възможно, можете да промените приложението, така че да предава правилни параметри за дата вместо отделни целочислени параметри.
- Използвайте процедура за обвиване. Вариант на метод №1 – например, ако не можете да промените приложението – би бил да създадете втора съхранена процедура, която приема конструирани параметри за дата от първата.
- Използвайте
OPTION (RECOMPILE). При лека цена на компилация всеки път, когато се изпълнява заявката, това принуждава SQL Server да оптимизира въз основа на представените всеки път стойности, вместо да оптимизира един план за неизвестни, първи или средни стойности на параметрите. (За задълбочено разглеждане на тази тема, вижте Пол Уайт „Параметър Sniffing, Embedding, and the RECOMPILE Options.“
- Използвайте динамичен SQL. Наличието на динамичен SQL приема конструираната
dateпроменливата принуждава правилна параметризация (точно както ако сте извикали съхранена процедура сdateпараметър), но е малко грозен и по-труден за поддържане.
- Бърка се с намеци и флагове за проследяване. Пол Уайт говори за някои от тях в гореспоменатата публикация.
Няма да предполагам, че това е изчерпателен списък и няма да повтарям съвета на Пол относно намеци или флагове за проследяване, така че просто ще се съсредоточа върху показването как първите четири подхода могат да смекчат проблема с лоши оценки .
1. Параметри за дата
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Процедура за обвиване
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. ОПЦИЯ (ПРЕКОМПИЛИРАНЕ)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Динамичен SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Тестовете
С четирите набора процедури беше лесно да се конструират тестове, които да ми покажат плановете и оценките, извлечени от SQL Server. Тъй като някои месеци са по-натоварени от други, избрах три различни месеца и ги изпълних няколко пъти.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Резултатът? Всеки отделен план дава едно и също търсене на индекси, но прогнозите са правилни само в трите периода от време в OPTION (RECOMPILE) версия. Останалите продължават да използват оценките, получени от първия набор от параметри (юли 2012 г.) и така докато получават по-добри оценки за първия изпълнение, тази оценка не е задължително да е по-добра за последващи изпълнения, използващи различни параметри (класически, учебник случай на подслушване на параметри):
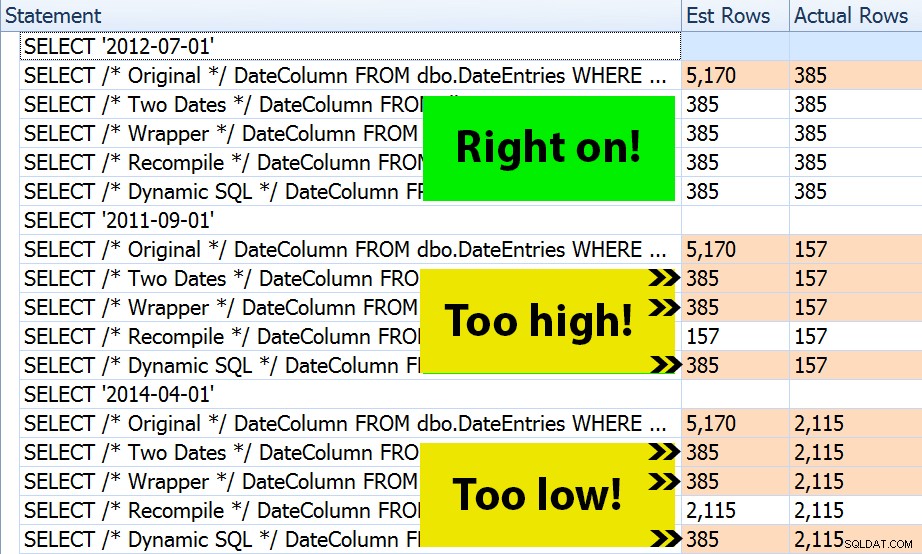
Обърнете внимание, че горното не е *точен* изход от SQL Sentry Plan Explorer – например премахнах редовете на дървото на инструкциите, които показват извикванията на външните съхранени процедури и декларациите на параметри.
От вас ще зависи да определите дали тактиката на компилиране всеки път е най-подходяща за вас, или на първо място трябва да "поправите" нещо. Тук се оказахме със същите планове и без забележими разлики в показателите за ефективност по време на изпълнение. Но при по-големи таблици, с по-изкривено разпределение на данните и по-големи отклонения в стойностите на предикатите (например, помислете за отчет, който може да обхване седмица, година и всичко между тях), може да си струва да се проучи. И имайте предвид, че можете да комбинирате методи тук – например можете да превключите към правилни параметри за дата *и* да добавите OPTION (RECOMPILE) , ако искаш.
Заключение
В този конкретен случай, който е умишлено опростяване, усилията за получаване на правилните оценки не се изплатиха – не получихме различен план, а производителността по време на изпълнение беше еквивалентна. Със сигурност обаче има и други случаи, в които това ще доведе до промяна и е важно да разпознаете несъответствието в оценките и да определите дали това може да се превърне в проблем с нарастването на вашите данни и/или изкривяването на разпространението ви. За съжаление, няма черен или бял отговор, тъй като много променливи ще повлияят на това дали режийните разходи за компилация са оправдани – както при много сценарии, IT DEPENDS™ …