Пагинацията е често срещан случай на използване в клиентски и уеб приложения навсякъде. Google ви показва 10 резултата наведнъж, вашата онлайн банка може да показва 20 сметки на страница, а софтуерът за проследяване на грешки и контрол на източника може да показва 50 елемента на екрана.
Исках да разгледам общия подход за пагинация в SQL Server 2012 – OFFSET / FETCH (стандартен еквивалент на първостепенната клауза LIMIT на MySQL) – и да предложа вариант, който ще доведе до по-линейна производителност на страници в целия набор, вместо да бъде само оптимална в началото. Което, за съжаление, е всичко, което много магазини ще тестват.
Какво е пагинация в SQL Server?
Въз основа на индексирането на таблицата, необходимите колони и избрания метод за сортиране, пагинацията може да бъде сравнително безболезнена. Ако търсите "първите" 20 клиента и клъстерираният индекс поддържа това сортиране (да речем, клъстериран индекс на колона IDENTITY или колона DateCreated), тогава заявката ще бъде относително ефективна. Ако трябва да поддържате сортиране, което изисква неклъстерни индекси, и особено ако имате колони, необходими за изход, които не са обхванати от индекса (няма значение, ако няма поддържащ индекс), заявките могат да станат по-скъпи. И дори една и съща заявка (с различен параметър @PageNumber) може да стане много по-скъпа, тъй като @PageNumber става по-висок – тъй като може да са необходими повече четения, за да се стигне до този „фрагмент“ от данните.
Някои ще кажат, че напредването към края на комплекта е нещо, което можете да решите, като отделите повече памет за проблема (така че елиминирате всяко физическо I/O) и/или използвате кеширане на ниво приложение (така че няма да базата данни изобщо). Нека приемем за целите на тази публикация, че повече памет не винаги е възможно, тъй като не всеки клиент може да добави RAM към сървър, който няма слотове за памет или не е под техния контрол, или просто да щракне с пръсти и да има готови по-нови, по-големи сървъри да отида. Особено, тъй като някои клиенти са на Standard Edition, така че са ограничени до 64 GB (SQL Server 2012) или 128 GB (SQL Server 2014), или използват дори по-ограничени издания като Express (1 GB) или едно от многото облачни предложения.
Така че исках да разгледам общия подход за пейджинг в SQL Server 2012 – OFFSET / FETCH – и да предложа вариант, който ще доведе до по-линейна производителност на пейджинг в целия набор, вместо да е оптимален само в началото. Което, за съжаление, е всичко, което много магазини ще тестват.
Настройка на данните за пагинация / Пример
Ще взема назаем от друга публикация, Лоши навици:Фокусиране само върху дисковото пространство при избора на ключове, където попълних следната таблица с 1 000 000 реда произволни (но не напълно реалистични) данни за клиенти:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Тъй като знаех, че ще тествам I/O тук и ще тествам както от топъл, така и от студен кеш, направих теста поне малко по-честен, като възстанових всички индекси, за да минимизирам фрагментацията (както ще се прави по-малко смущаващо, но редовно, в повечето натоварени системи, които извършват всякакъв вид поддръжка на индекси):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
След повторното изграждане сега фрагментацията идва на 0,05% – 0,17% за всички индекси (ниво на индекса =0), страниците се запълват над 99%, а броят на редовете / броят на страниците за индексите е както следва:
| Индекс | Брой страници | Брой редове |
|---|---|---|
| C_PK_Customers_I (клъстериран индекс) | 19 210 | 1 000 000 |
| C_Email_Customers_I | 7344 | 1 000 000 |
| C_Active_Customers_I (филтриран индекс) | 13 648 | 815 235 |
| C_Name_Customers_I | 16 824 | 1 000 000 |
Индекси, брой страници, брой редове
Това очевидно не е супер широка таблица и този път съм оставил компресията извън картината. Може би ще проуча повече конфигурации в бъдещ тест.
Как ефективно да пагинирате SQL заявка
Концепцията за пагинация – показваща на потребителя само редове наведнъж – е по-лесна за визуализиране, отколкото за обяснение. Помислете за индекса на физическа книга, която може да има няколко страници с препратки към точки в книгата, но организирани по азбучен ред. За простота, да кажем, че десет елемента се побират на всяка страница от индекса. Това може да изглежда така:
Сега, ако вече съм прочел страници 1 и 2 от индекса, знам, че за да стигна до страница 3, трябва да пропусна 2 страници. Но тъй като знам, че има 10 елемента на всяка страница, мога също да мисля за това като пропускане на 2 x 10 елемента и започване на 21-вия елемент. Или, казано по друг начин, трябва да пропусна първите (10*(3-1)) елемента. За да направя това по-общо, мога да кажа, че за да започна на страница n, трябва да пропусна първите (10 * (n-1)) елементи. За да стигна до първата страница, пропускам 10*(1-1) елемента, за да завърша на т. 1. За да стигна до втората страница, пропускам 10*(2-1) елемента, за да завърша на т. 11. И така включено.
С тази информация потребителите ще формулират пейджинг заявка като тази, като се има предвид, че клаузите OFFSET / FETCH, добавени в SQL Server 2012, са специално проектирани да пропускат толкова много редове:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Както споменах по-горе, това работи добре, ако има индекс, който поддържа ORDER BY и който покрива всички колони в клаузата SELECT (и, за по-сложни заявки, клаузите WHERE и JOIN). Въпреки това, разходите за сортиране може да са огромни без поддържащ индекс и ако изходните колони не са покрити, или ще се окажете с цял куп ключови търсения, или дори може да получите сканиране на таблица в някои сценарии.
Най-добри практики за сортиране на SQL страници
Като се има предвид таблицата и индексите по-горе, исках да тествам тези сценарии, където искаме да покажем 100 реда на страница и да изведем всички колони в таблицата:
- По подразбиране –
ORDER BY CustomerID(клъстериран индекс). Това е най-удобното подреждане за хората в базата данни, тъй като не изисква допълнително сортиране и са включени всички данни от тази таблица, които биха могли да са необходими за показване. От друга страна, това може да не е най-ефективният индекс, който да използвате, ако показвате подмножество от таблицата. Поръчката също може да няма смисъл за крайните потребители, особено ако CustomerID е сурогатен идентификатор без външно значение. - Телефонен указател –
ORDER BY LastName, FirstName(поддържа неклъстериран индекс). Това е най-интуитивното подреждане за потребителите, но ще изисква неклъстериран индекс, който да поддържа както сортиране, така и покритие. Без поддържащ индекс ще трябва да се сканира цялата таблица. - Дефинирани от потребителя –
ORDER BY FirstName DESC, EMail(няма поддържащ индекс). Това представлява възможността на потребителя да избере произволен ред на сортиране, за който Майкъл Дж. Суорт предупреждава в „Модели за дизайн на потребителски интерфейс, които не се мащабират“.
Исках да тествам тези методи и да сравня планове и показатели, когато – и при сценарии за топъл и студен кеш – гледам страница 1, страница 500, страница 5 000 и страница 9 999. Създадох тези процедури (различни само от клаузата ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail В действителност вероятно ще имате само една процедура, която или използва динамичен SQL (като в моя пример за „кухненска мивка“), или CASE израз, за да диктува реда.
И в двата случая може да видите най-добри резултати, като използвате OPTION (RECOMPILE) в заявката, за да избегнете повторно използване на планове, които са оптимални за една опция за сортиране, но не за всички. Създадох отделни процедури тук, за да премахна тези променливи; Добавих ОПЦИЯ (ПРЕКОМПИЛИРАНЕ) за тези тестове, за да стоя далеч от подслушване на параметри и други проблеми с оптимизацията, без да промивам многократно целия кеш на плана.
Алтернативен подход към пагинацията на SQL Server за по-добра производителност
Малко по-различен подход, който не виждам прилаган много често, е да се намери "страницата", която използваме, използвайки само ключа за клъстериране, и след това да се присъедините към него:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Това е по-подробен код, разбира се, но да се надяваме, че е ясно какво може да бъде принуден да направи SQL Server:избягване на сканиране или поне отлагане на търсене, докато не бъде намален много по-малък набор от резултати. Пол Уайт (@SQL_Kiwi) проучи подобен подход още през 2010 г., преди OFFSET/FETCH да бъде въведен в ранните бета версии на SQL Server 2012 (за първи път писах в блог за това по-късно същата година).
Предвид горните сценарии създадох още три процедури с единствената разлика между колоните, посочени в клаузите ORDER BY (сега ни трябват две, една за самата страница и една за подреждане на резултата):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Забележка:Това може да не работи толкова добре, ако вашият първичен ключ не е клъстериран – част от трика, който прави тази работа по-добра, когато може да се използва поддържащ индекс, е, че ключът за клъстериране вече е в индекса, така че търсенето често се избягва.
Тестване на сортирането на ключове за клъстери
Първо тествах случая, в който не очаквах голяма разлика между двата метода – сортиране по ключа за клъстериране. Изпълних тези изрази в пакет в SQL Sentry Plan Explorer и наблюдавах продължителността, четенията и графичните планове, като се уверих, че всяка заявка започва от напълно студен кеш:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
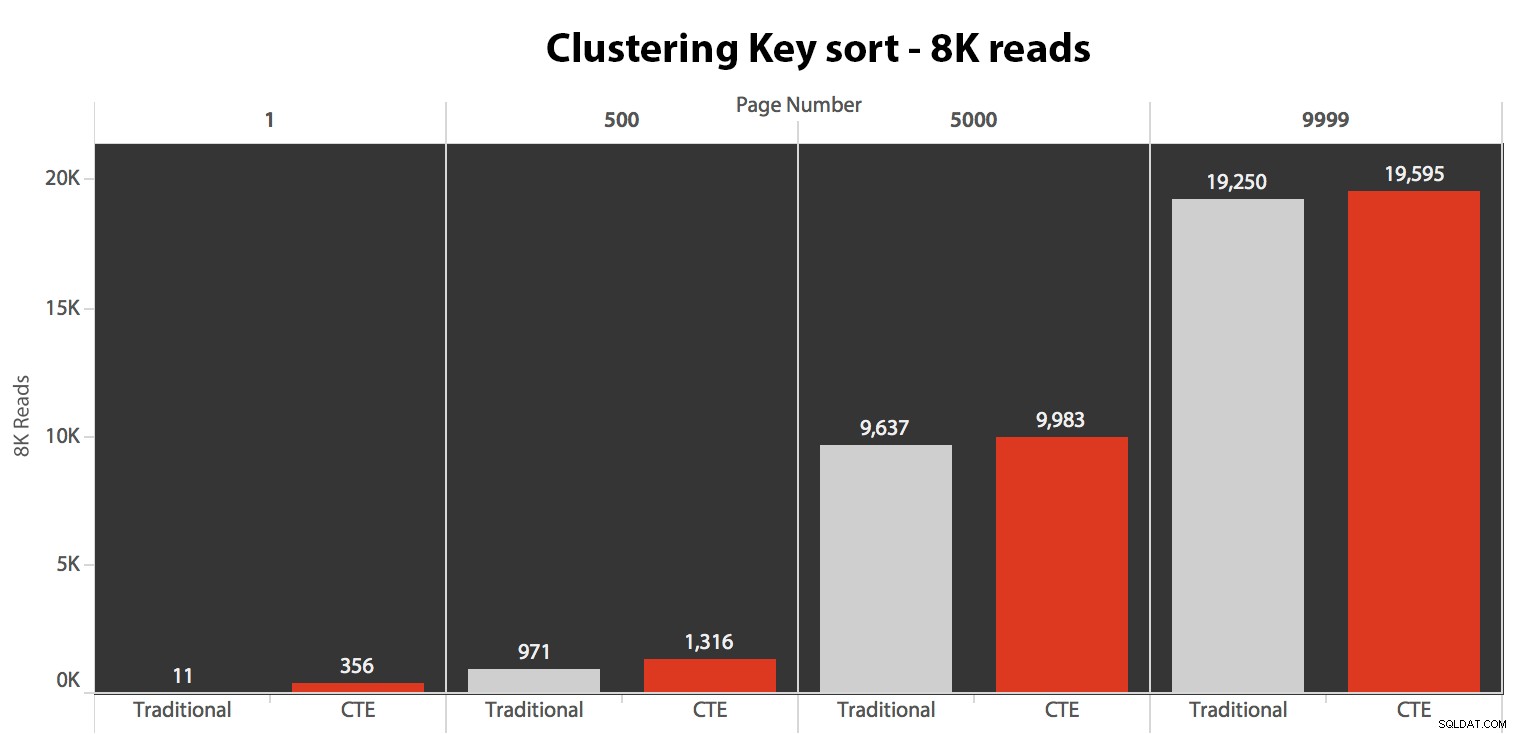
Резултатите тук не бяха изумителни. Над 5 изпълнения средният брой четения е показан тук, показвайки незначителни разлики между двете заявки, за всички номера на страници, при сортиране по ключа за групиране:
Планът за метода по подразбиране (както е показано в Plan Explorer) във всички случаи беше както следва:
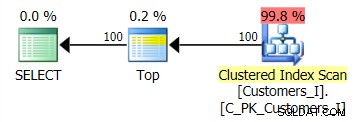
Докато планът за метода, базиран на CTE, изглеждаше така:
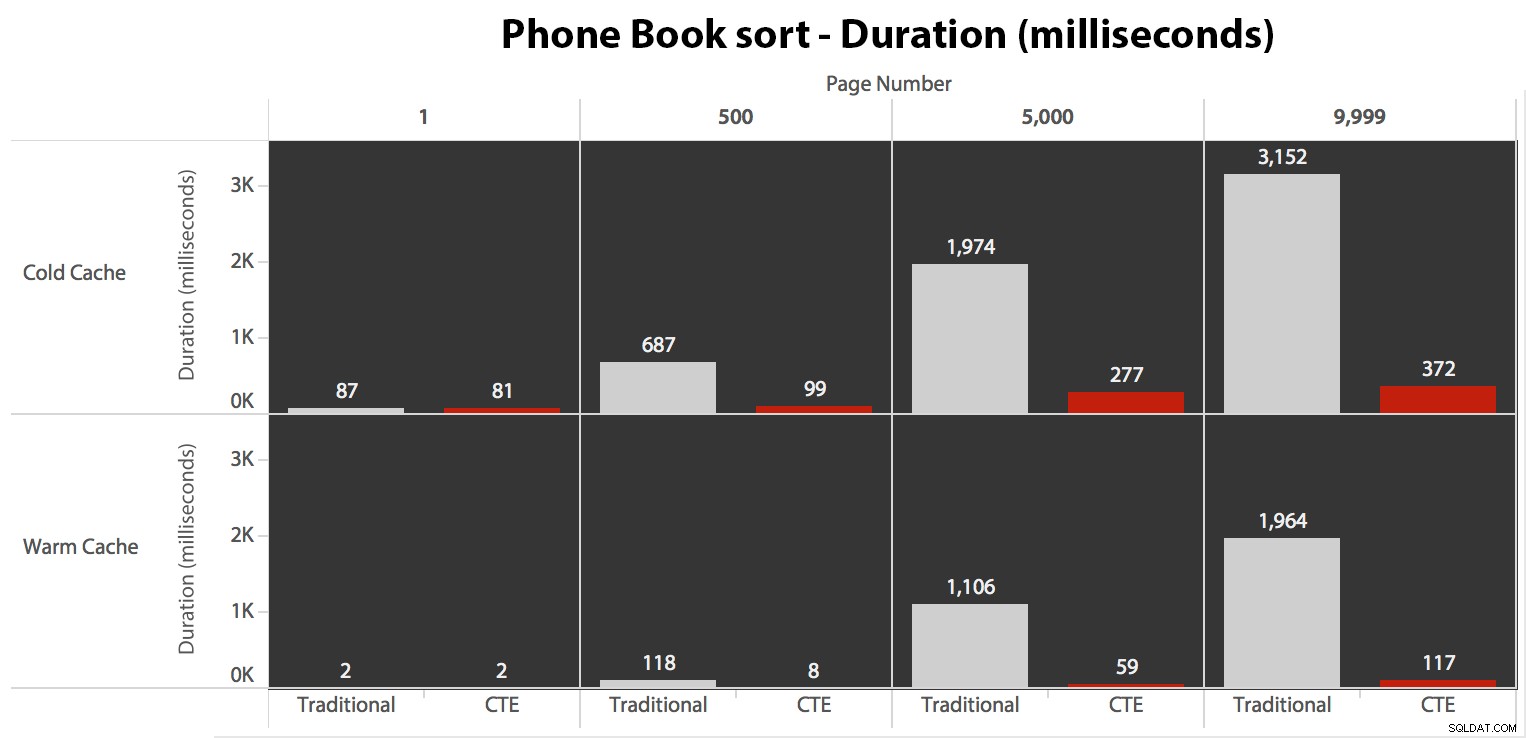
Сега, докато I/O беше един и същ, независимо от кеширането (само много повече четения напред в сценария със студен кеш), измерих продължителността със студен кеш, а също и с топъл кеш (където коментирах командите DROPCLEANBUFFERS и изпълни заявките няколко пъти преди измерване). Тези продължителности изглеждаха така:
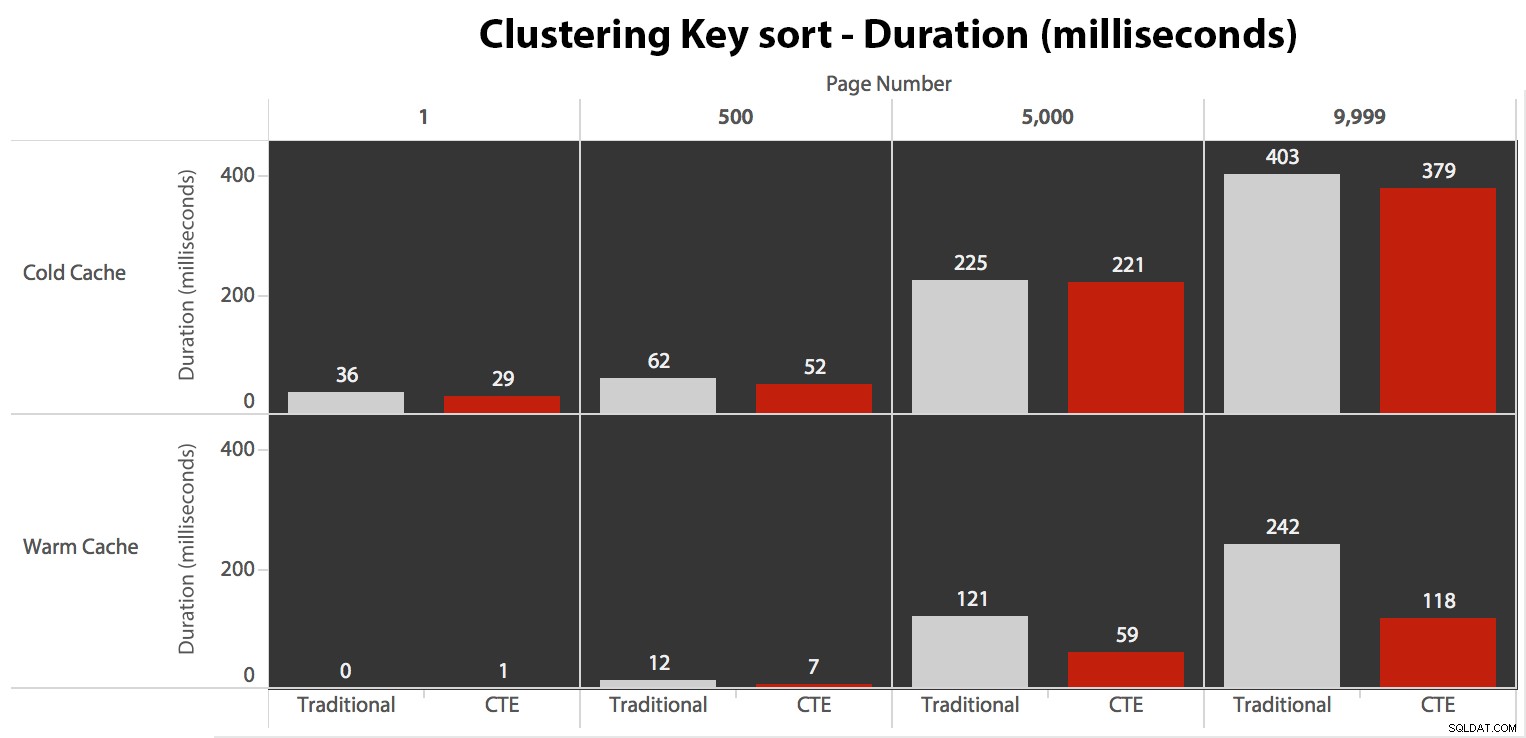
Въпреки че можете да видите модел, който показва, че продължителността се увеличава с увеличаване на броя на страницата, имайте предвид мащаба:за да достигнете редове 999 801 -> 999 900, говорим за половин секунда в най-лошия случай и 118 милисекунди в най-добрия случай. Подходът CTE печели, но не с много.
Тестване на сортирането на телефонния указател
След това тествах втория случай, при който сортирането беше подкрепено от непокриващ индекс на LastName, FirstName. Заявката по-горе току-що промени всички екземпляри на Test_1 към Test_2 . Ето четенията с помощта на студен кеш:
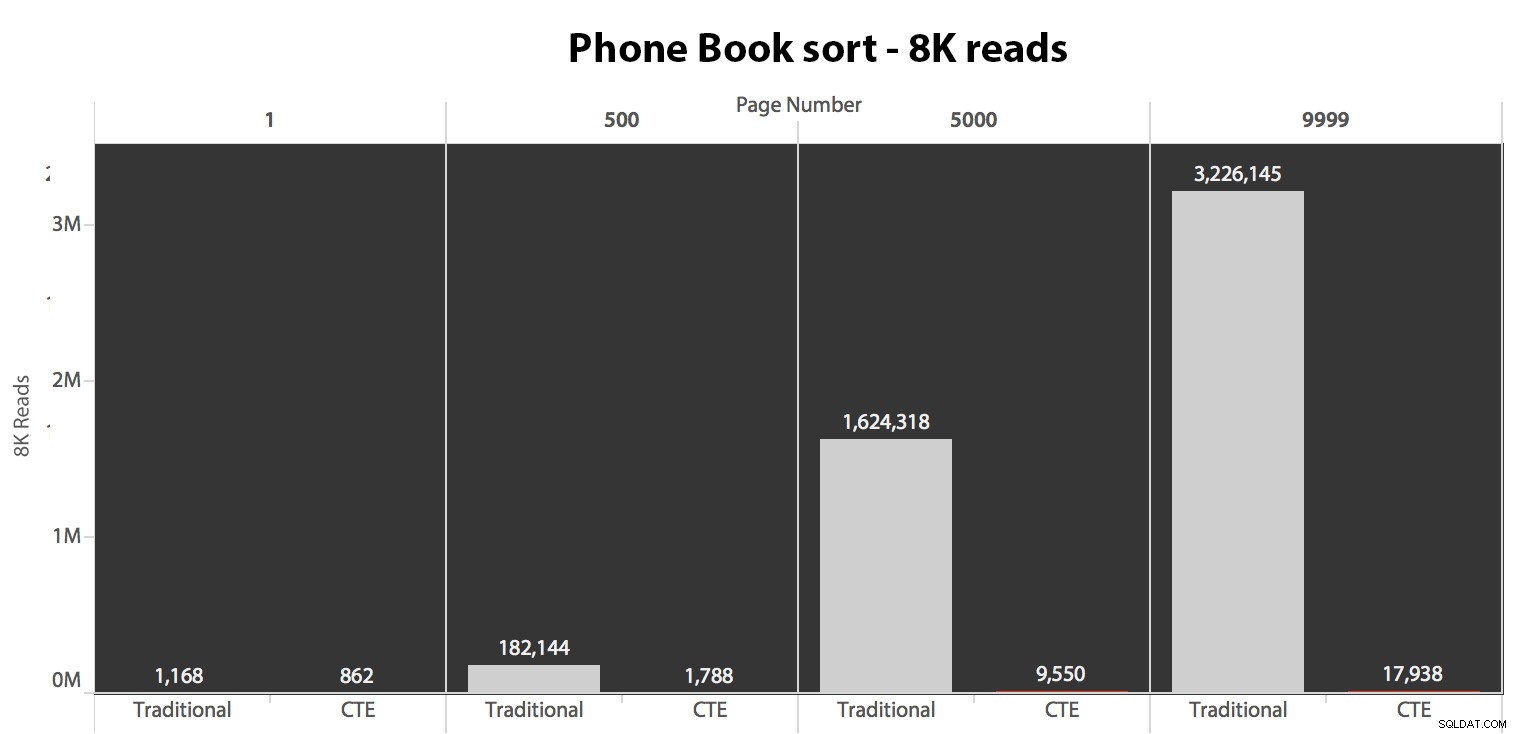
(Показанията под топъл кеш следваха същия модел – действителните числа се различаваха леко, но не достатъчно, за да оправдаят отделна диаграма.)
Когато не използваме клъстерирания индекс за сортиране, е ясно, че разходите за I/O, свързани с традиционния метод OFFSET/FETCH, са много по-лоши, отколкото когато идентифицираме ключовете първо в CTE и изтегляме останалите колони само за това подмножество.
Ето плана за традиционния подход на заявка:
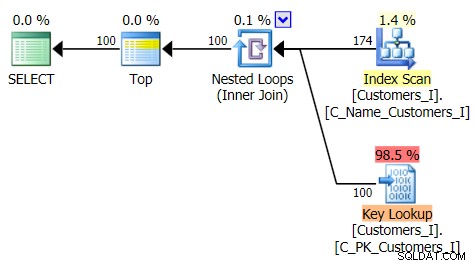
И планът за моя алтернативен подход, CTE:
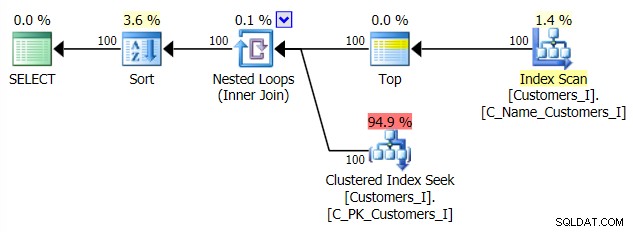
И накрая, продължителността:
Традиционният подход показва много очевиден нарастване на продължителността, докато вървите към края на пагинацията. Подходът на CTE също показва нелинеен модел, но той е далеч по-слабо изразен и дава по-добро време за всеки номер на страница. Виждаме 117 милисекунди за предпоследната страница, в сравнение с традиционния подход, който идва за почти две секунди.
Тестване на дефинираното от потребителя сортиране
Накрая промених заявката, за да използвам Test_3 съхранени процедури, тествайки случая, когато сортирането е дефинирано от потребителя и няма поддържащ индекс. I/O беше последователен във всеки набор от тестове; графиката е толкова безинтересна, просто ще дам линк към нея. Накратко:имаше малко над 19 000 прочитания във всички тестове. Причината е, че всеки един вариант трябваше да извърши пълно сканиране поради липсата на индекс, който да поддържа подреждането. Ето плана за традиционния подход:
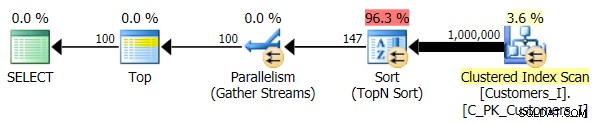
И докато планът за CTE версията на заявката изглежда тревожно по-сложен...
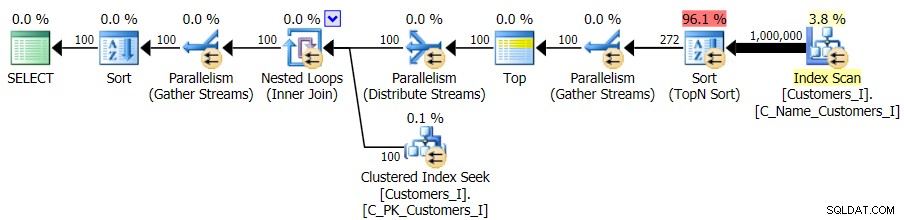
…това води до по-ниска продължителност във всички случаи освен в един. Ето и продължителността:
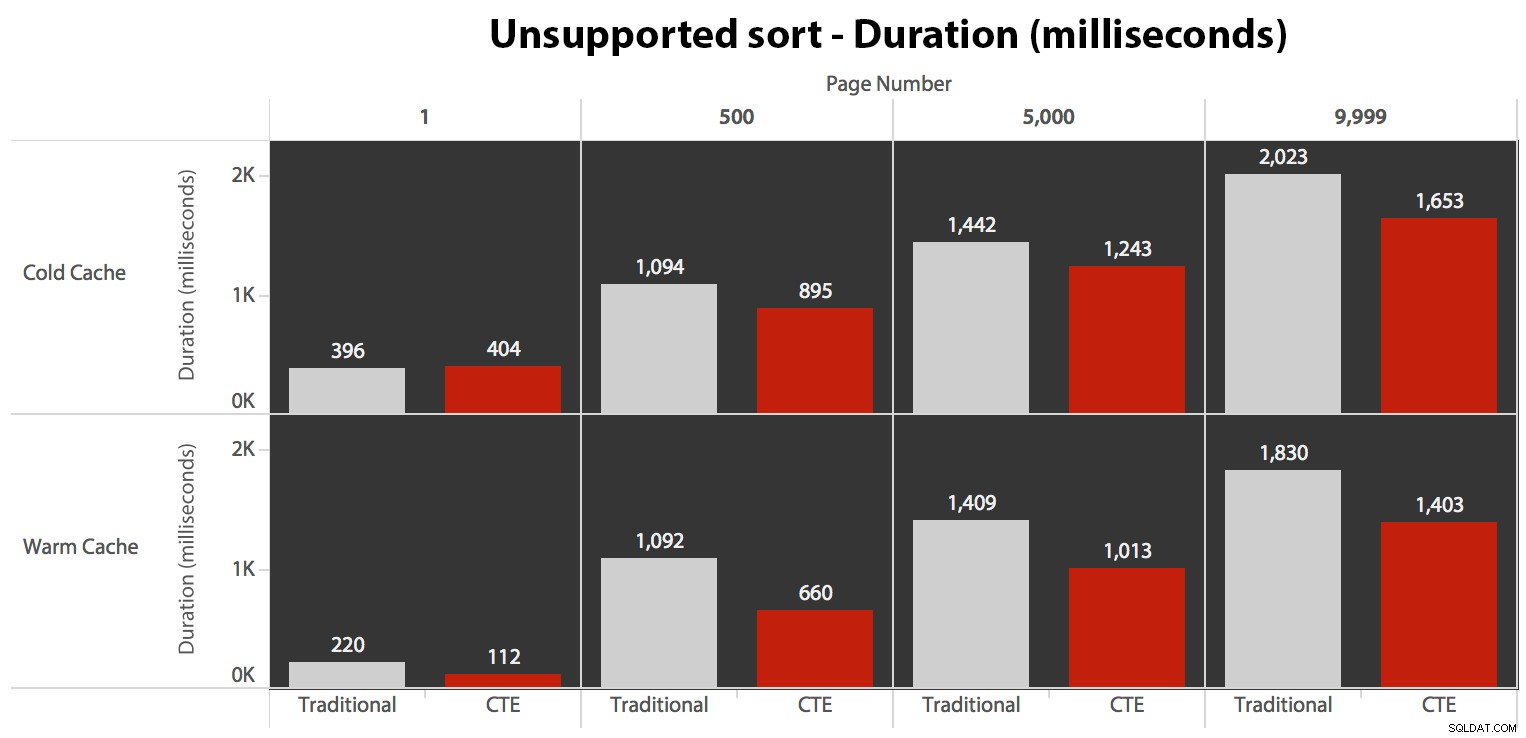
Можете да видите, че не можем да постигнем линейна производителност тук, използвайки нито един от двата метода, но CTE излиза начело с добра разлика (от 16% до 65% по-добре) във всеки отделен случай, с изключение на заявката за студен кеш спрямо първия страница (където загуби с невероятните 8 милисекунди). Също така е интересно да се отбележи, че традиционният метод изобщо не помага много от топъл кеш в "средата" (страници 500 и 5000); само към края на комплекта си струва да се спомене всякаква ефективност.
По-висок обем
След индивидуално тестване на няколко изпълнения и вземане на средни стойности, реших, че също би имало смисъл да тествам голям обем транзакции, които донякъде биха симулирали реален трафик в натоварена система. Така че създадох задание с 6 стъпки, по една за всяка комбинация от метод на заявка (традиционен пейджинг срещу CTE) и тип на сортиране (кластерен ключ, телефонен указател и неподдържан), със 100-стъпкова последователност от натискане на четирите номера на страниците по-горе , по 10 пъти всеки и 60 други номера на страници, избрани на случаен принцип (но еднакви за всяка стъпка). Ето как генерирах скрипта за създаване на работа:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Ето получения списък със стъпки на заданието и едно от свойствата на стъпката:
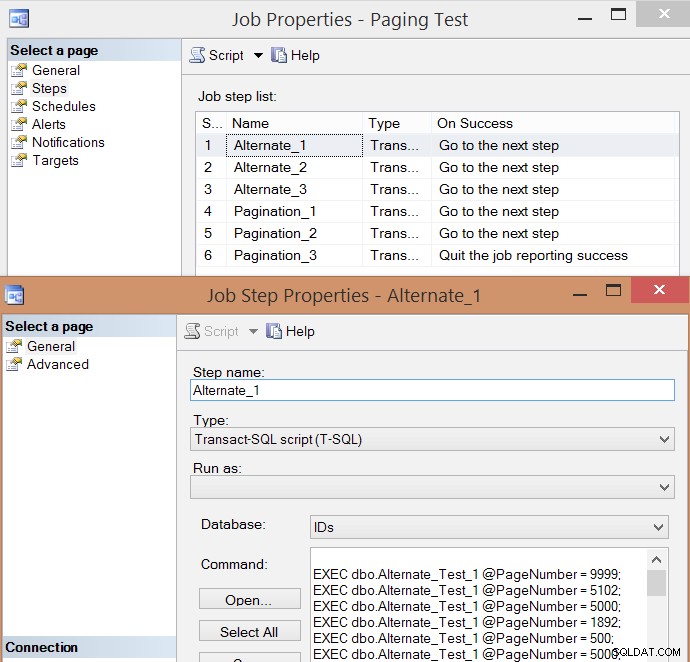
Изпълних заданието пет пъти, след това прегледах историята на заданията и ето средното време на изпълнение на всяка стъпка:
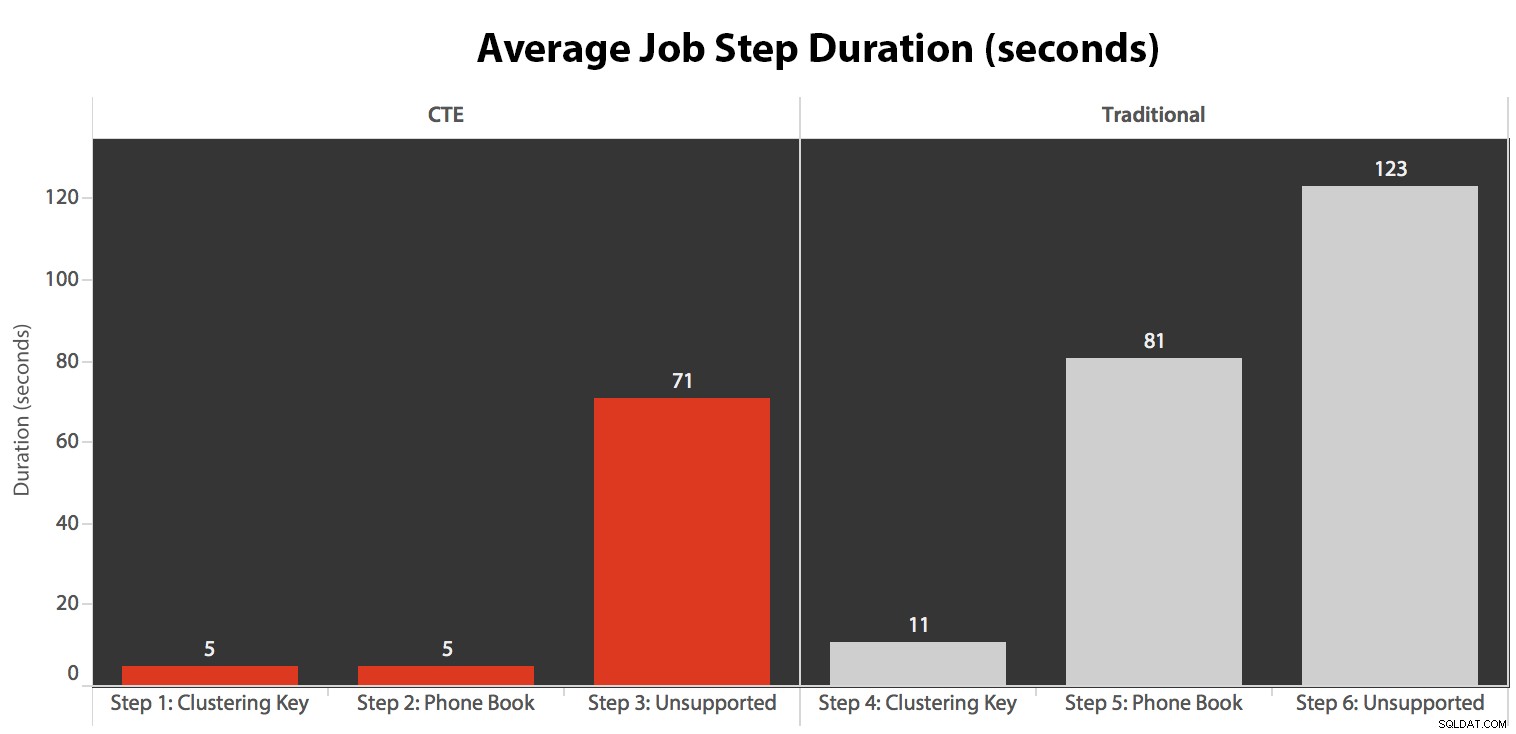
Също така съпоставих едно от изпълненията в календара на SQL Sentry Event Manager...
…с таблото за управление на SQL Sentry и ръчно отбелязано приблизително къде е извършена всяка от шестте стъпки. Ето диаграмата за използване на процесора от страната на Windows на таблото:
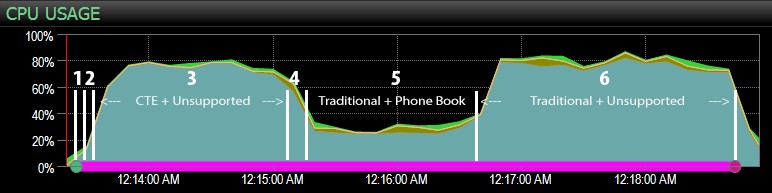
А от страната на SQL Server на таблото за управление интересните показатели бяха в графиките за ключови търсения и изчаквания:
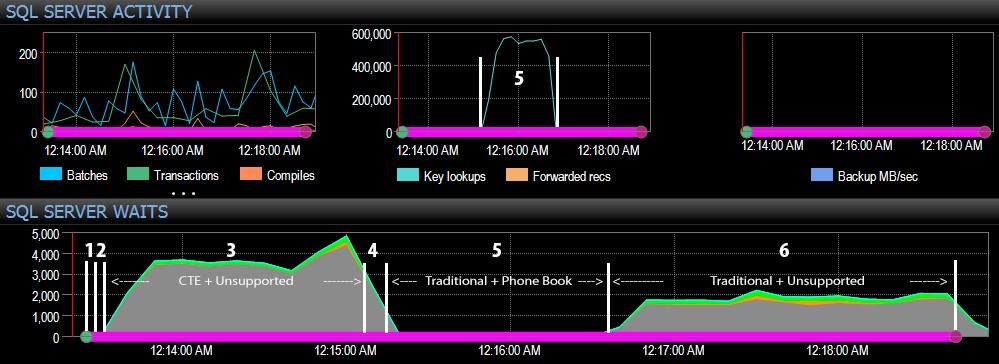
Най-интересните наблюдения само от чисто визуална гледна точка:
- CPU е доста горещ, около 80%, по време на стъпка 3 (CTE + без поддържащ индекс) и стъпка 6 (традиционен + без поддържащ индекс);
- CXPACKET чаканията са относително високи по време на стъпка 3 и в по-малка степен по време на стъпка 6;
- можете да видите огромния скок в ключовите търсения до почти 600 000 за около една минута (съответстващо на стъпка 5 – традиционният подход с индекс в стил телефонен указател).
В бъдещ тест – както с предишната ми публикация за GUID – бих искал да тествам това на система, където данните не се вписват в паметта (лесни за симулиране) и където дисковете са бавни (не толкова лесни за симулиране) , тъй като някои от тези резултати вероятно имат полза от неща, които не всяка производствена система има – бързи дискове и достатъчно RAM. Също така трябва да разширя тестовете, за да включа още вариации (използвайки тънки и широки колони, тънки и широки индекси, индекс на телефонния указател, който всъщност обхваща всички изходни колони и сортиране в двете посоки). Намаляването на обхвата определено ограничи обхвата на моето тестване за този първи набор от тестове.
Как да подобрим пагинацията на SQL Server
Пагинацията не винаги трябва да е болезнена; SQL Server 2012 със сигурност прави синтаксиса по-лесен, но ако просто включите естествения синтаксис, може да не винаги виждате голяма полза. Тук показах, че малко по-подробен синтаксис, използващ CTE, може да доведе до много по-добра производителност в най-добрия случай и може би незначителни разлики в производителността в най-лошия случай. Чрез разделянето на местоположението на данни от извличането на данни в две различни стъпки, можем да видим огромна полза в някои сценарии, извън по-високите изчаквания CXPACKET в един случай (и дори тогава паралелните заявки завършват по-бързо от другите заявки, показващи малко или никакви изчаквания, така че е малко вероятно те да бъдат "лошите" CXPACKET, за които всички ви предупреждават).
Все пак дори по-бързият метод е бавен, когато няма поддържащ индекс. Въпреки че може да се изкушите да внедрите индекс за всеки възможен алгоритъм за сортиране, който потребителят може да избере, може да помислите за предоставяне на по-малко опции (тъй като всички знаем, че индексите не са безплатни). Например, необходимо ли е приложението ви да поддържа сортиране по възходящо * и* низходящо фамилно име? Ако искат да отидат директно до клиентите, чиито фамилни имена започват с Z, не могат ли да отидат на *последната* страница и да работят назад? Това е решение за бизнес и използваемост повече от техническо, просто го запазете като опция, преди да поставите индекси на всяка колона за сортиране в двете посоки, за да получите най-добрата производителност дори и за най-неясни опции за сортиране.