В предишна статия от тази серия създадохме клъстер PostgreSQL 12 с два възела в облака AWS. Също така инсталирахме и конфигурирахме 2ndQuadrant OmniDB в трети възел. Изображението по-долу показва архитектурата:
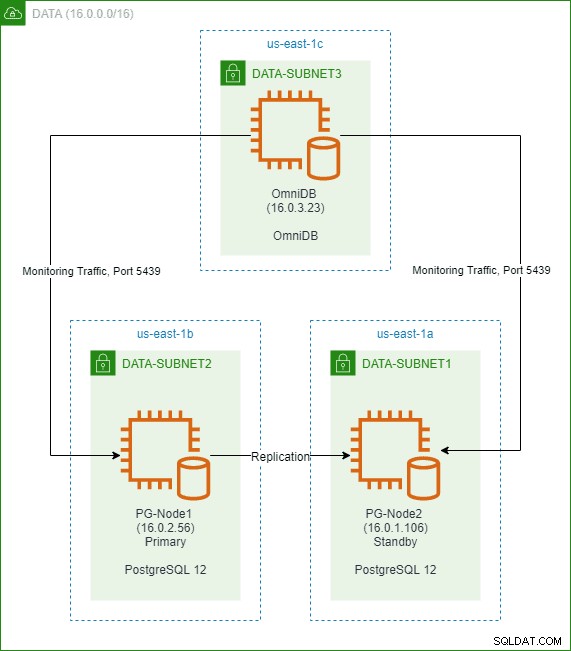
Бихме могли да се свържем както към основния, така и към резервния възел от уеб-базирания потребителски интерфейс на OmniDB. След това възстановихме примерна база данни, наречена „dvdrental“ в първичния възел, която започна да се репликира в режим на готовност.
В тази част от поредицата ще научим как да създадем и използваме табло за наблюдение в OmniDB. DBA и оперативните екипи често предпочитат графични инструменти, а не сложни заявки за визуална проверка на здравето на базата данни. OmniDB идва с редица важни джаджи, които могат лесно да се използват в таблото за наблюдение. Както ще видим по-късно, той също така позволява на потребителите да пишат свои собствени джаджи за наблюдение.
Създаване на табло за наблюдение на производителността
Нека започнем с таблото за управление по подразбиране, което OmniDB доставя.
На изображението по-долу сме свързани към основния възел (PG-Node1). Щракваме с десния бутон върху името на екземпляра и след това от изскачащото меню избираме „Монитор“ и след това „Табло за управление“.
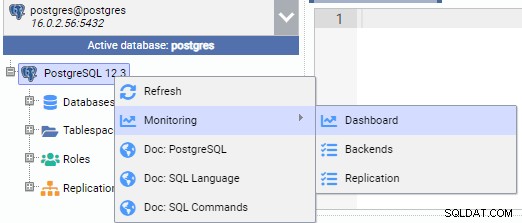
Това отваря табло за управление с някои приспособления в него.
В термините на OmniDB, правоъгълните джаджи в таблото за управление се наричат мониторни единици . Всяка от тези единици показва конкретен показател от екземпляра на PostgreSQL, с който е свързан, и динамично опреснява данните си.
Разбиране на единиците за наблюдение
OmniDB се предлага с четири типа модули за наблюдение:
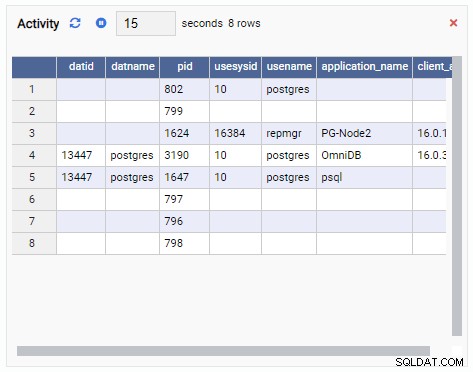
- Решетка е таблична структура, която показва резултата от заявка. Например, това може да бъде изходът на SELECT * FROM pg_stat_replication. Решетка изглежда така:
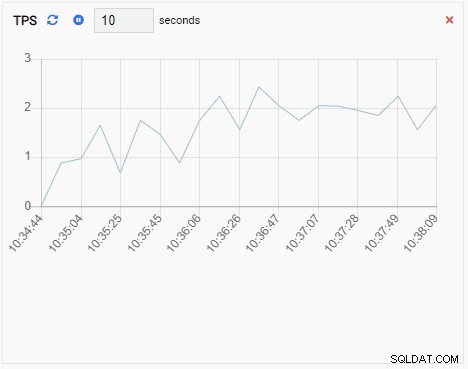
- Диаграма показва данните в графичен формат, като линии или кръгови диаграми. Когато се опресни, цялата диаграма се преначертава на екрана с нова стойност, а старата стойност е изчезнала. С тези единици за наблюдение можем да видим само текущата стойност на метриката. Ето пример за диаграма:
- Приложена диаграма е също единица за наблюдение от тип диаграма, освен когато се опреснява, тя добавя новата стойност към съществуващата серия. С Chart-Append можем лесно да видим тенденциите във времето. Ето един пример:
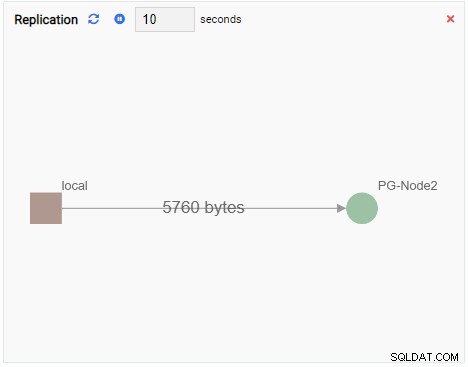
- А Графика показва връзки между екземпляри на PostgreSQL клъстер и свързан показател. Подобно на модула за наблюдение на графики, блокът за наблюдение на графики също обновява старата си стойност с нова. Изображението по-долу показва, че текущият възел (PG-Node1) се репликира към PG-Node2:
Всяко звено за наблюдение има редица общи елементи:
- Име на звеното за наблюдение
- Бутон „опресняване“ за ръчно опресняване на устройството
- Бутон „пауза“ за временно спиране на опресняването на модула за наблюдение
- Текстово поле, показващо текущия интервал на опресняване. Това може да се промени
- Бутон „затваряне“ (червен кръст), за да премахнете модула за наблюдение от таблото.
- Реалната област за рисуване на мониторинга
Предварително изградени модули за наблюдение
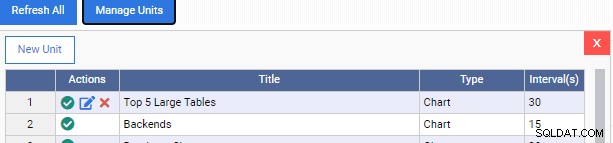
OmniDB идва с редица модули за наблюдение за PostgreSQL, които можем да добавим към нашето табло. За достъп до тези единици щракваме върху бутона „Управление на единици“ в горната част на таблото:
Това отваря списъка „Управление на единици“:
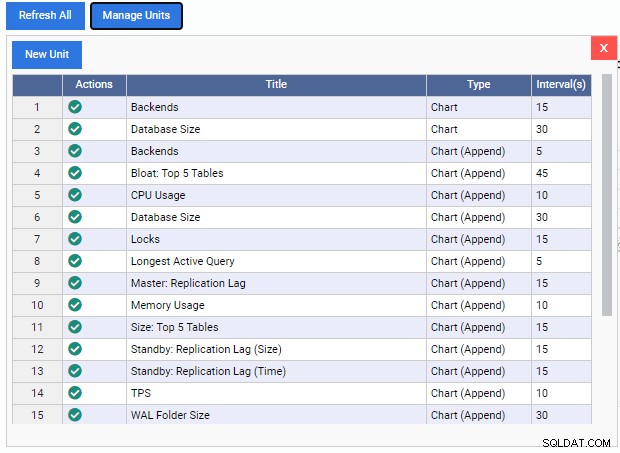
Както виждаме, тук има няколко предварително изградени модули за наблюдение. Кодовете за тези модули за наблюдение се изтеглят безплатно от репозитория GitHub на 2ndQuadrant. Всяка единица, изброена тук, показва своето име, тип (диаграма, добавяне на диаграма, графика или решетка) и честотата на опресняване по подразбиране.
За да добавим единица за наблюдение към таблото, просто трябва да щракнем върху зелената отметка под колоната „Действия“ за това устройство. Можем да смесваме и съпоставяме различни единици за наблюдение, за да изградим желаното от нас табло.
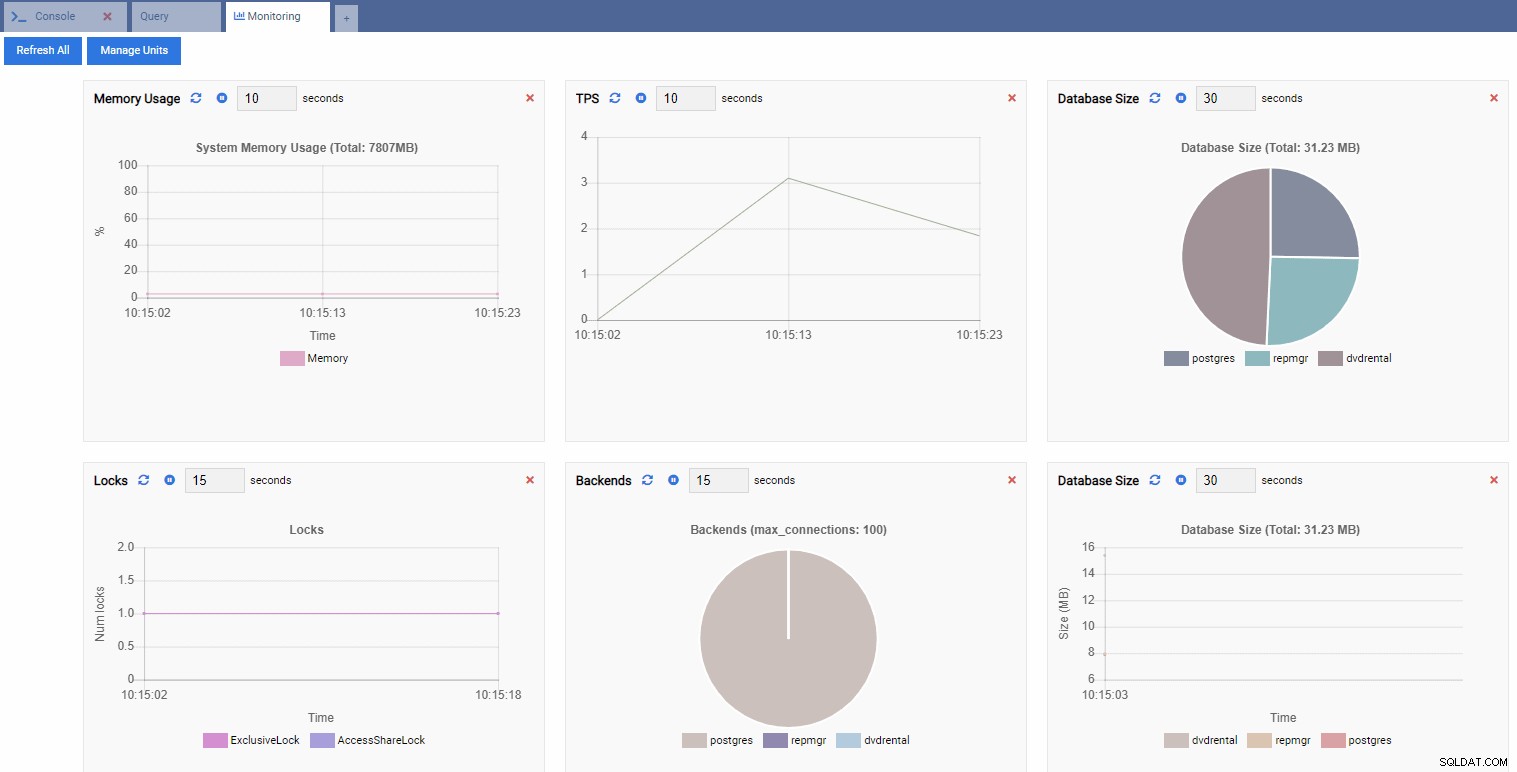
На изображението по-долу сме добавили следните единици за нашето табло за мониторинг на производителността и премахнахме всичко останало:
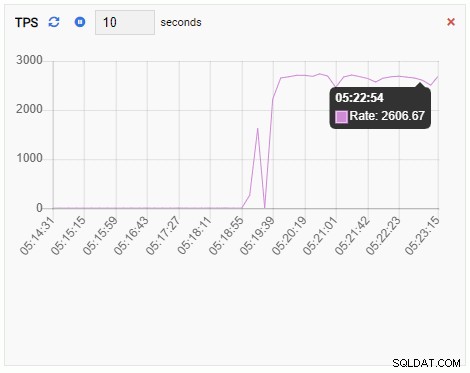
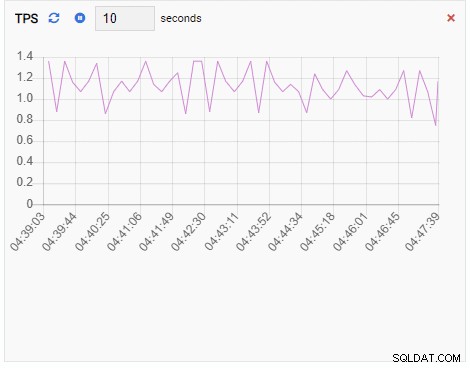
TPS (транзакция в секунда):
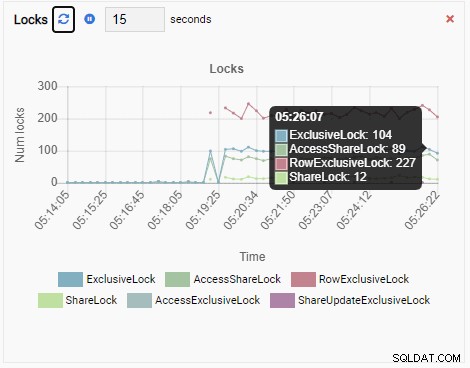
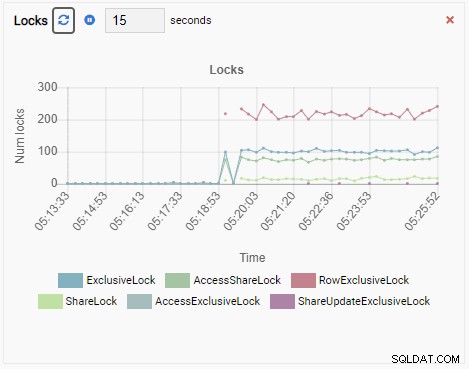
Брой ключалки:
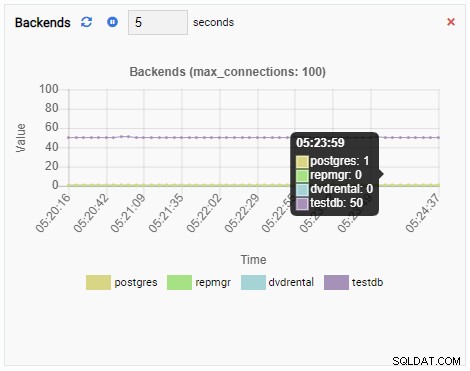
Брой бекендове:
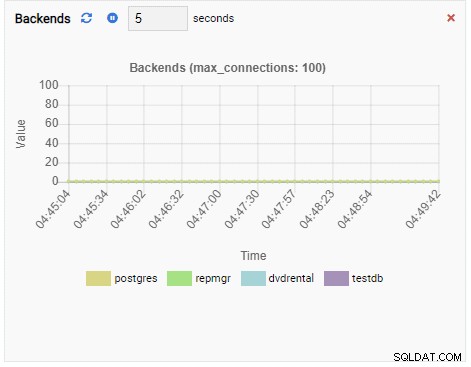
Тъй като нашият екземпляр е неактивен, можем да видим, че стойностите на TPS, Locks и Backends са минимални.
Тестване на таблото за наблюдение
Сега ще стартираме pgbench в нашия първичен възел (PG-Node1). pgbench е прост инструмент за сравнителен анализ, който се доставя с PostgreSQL. Подобно на повечето други инструменти от този вид, pgbench създава примерна схема и таблици на OLTP системи в база данни, когато се инициализира. След това може да емулира множество клиентски връзки, като всяка изпълнява определен брой транзакции в базата данни. В този случай няма да правим сравнителен анализ на основния възел на PostgreSQL; ще създадем базата данни само за pgbench и ще видим дали нашите единици за наблюдение на таблото ще приемат промяната в здравето на системата.
Първо, създаваме база данни за pgbench в основния възел:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "СЪЗДАВАНЕ НА БАЗА ДАННИ testdb"; СЪЗДАВАНЕ НА БАЗА ДАННИ
След това инициализираме базата данни “testdb” за pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbdropping стари таблици...създаване на таблици...генериране данни...100000 от 2000000 кортежи (5%) извършени (изминали 0,02 s, оставащи 0,43 s) 200 000 от 2000000 кортежи (10%) направени (изминали 0,05 s, оставащи 0,41 s)……20000000 (изминали 0,41 s)……20000000000 готово (изминали 1,84 s, оставащи 0,00 s) вакуумиране... създаване на първични ключове... готово.
С инициализираната база данни, сега започваме действителния процес на зареждане. В кодовия фрагмент по-долу молим pgbench да започне с 50 едновременни клиентски връзки към базата данни testdb, като всяка връзка изпълнява 100 000 транзакции в своите таблици. Тестът за натоварване ще се проведе в две нишки.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100 000 testdbстартиране на вакуум...край.……Ако сега се върнем към нашето табло за управление на OmniDB, ще видим, че единиците за наблюдение показват някои много различни резултати.
Показателят TPS показва доста висока стойност. Има внезапен скок от по-малко от 2 до повече от 2000:
Броят на бекендовете се е увеличил. Както се очаква, testdb има 50 връзки към него, докато други бази данни са неактивни:
И накрая, броят на изключителните заключване на редове в базата данни testdb също е голям:
Сега си представете това. Вие сте DBA и използвате OmniDB за управление на флота от екземпляри на PostgreSQL. Получавате обаждане, за да проучите бавната производителност в един от случаите.
Използвайки табло за управление като това, което току-що видяхме (въпреки че е много просто), можете лесно да намерите основната причина. Можете да проверите броя на задните части, заключванията, наличната памет и т.н., за да видите какво причинява проблема.
И точно тук OmniDB може да бъде наистина полезен инструмент.
Създаване на персонализирани единици за наблюдение
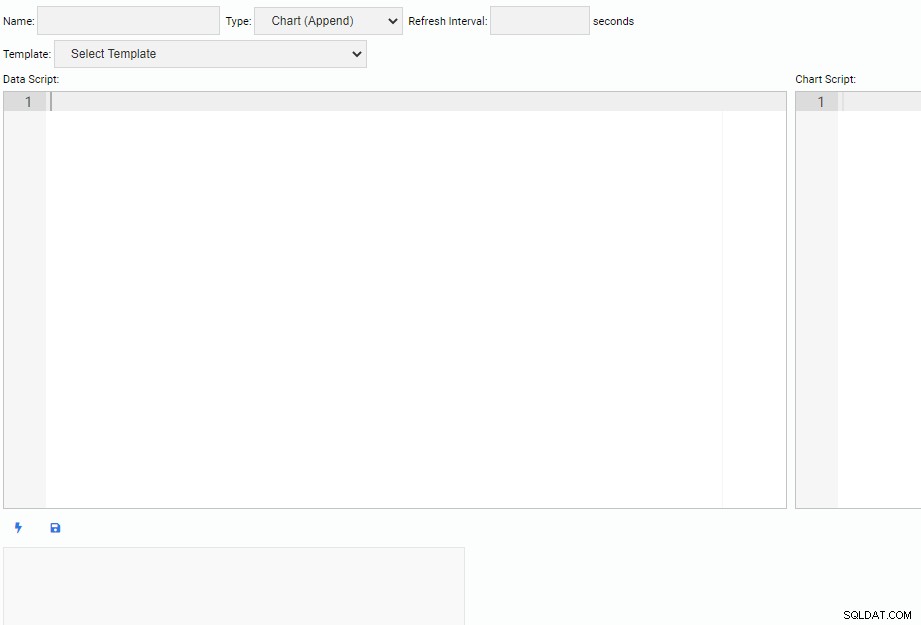
Понякога ще трябва да създадем наши собствени звена за наблюдение. За да напишете нова единица за наблюдение, щракваме върху бутона „Нова единица“ в списъка „Управление на единици“. Това отваря нов раздел с празно платно за писане на код:
В горната част на екрана трябва да посочим име за нашия модул за наблюдение, да изберем неговия тип и да посочим неговия интервал за опресняване по подразбиране. Можем също да изберем съществуваща единица като шаблон.
Под заглавната секция има две текстови полета. Редакторът „Data Script“ е мястото, където пишем код, за да получим данни за нашето звено за наблюдение. Всеки път, когато единица се обновява, кодът на скрипта за данни ще се изпълнява. Редакторът "Chart Script" е мястото, където пишем код за чертане на действителната единица. Това се изпълнява, когато единицата е изтеглена за първи път.
Целият код на скрипт за данни е написан на Python. За единицата за наблюдение на типа диаграма, OmniDB се нуждае от скрипт на диаграмата да бъде написан в Chart.js.
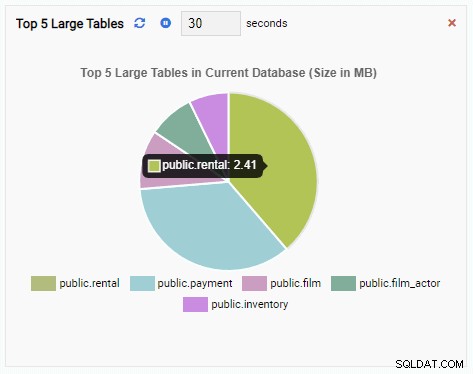
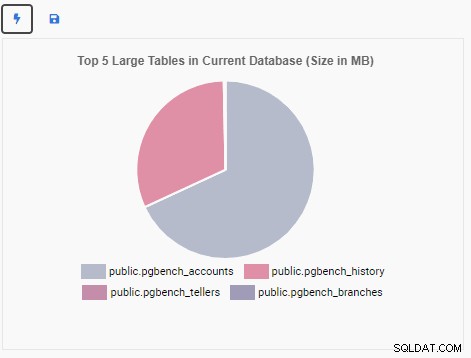
Сега ще създадем звено за наблюдение, за да покажем първите 5 големи таблици в текущата база данни. Въз основа на базата данни, избрана в OmniDB, звеното за наблюдение ще промени дисплея си, за да отразява имената на петте най-големи таблици в тази база данни.
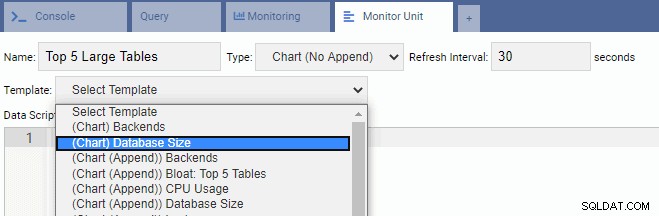
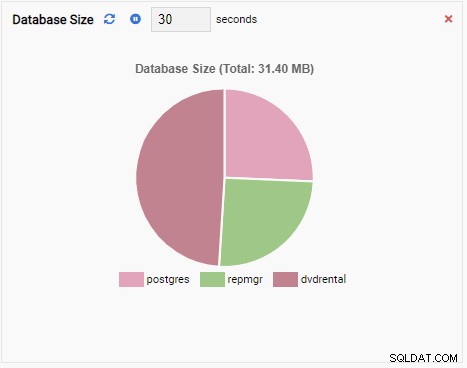
За да напишете нова единица, най-добре е да започнете със съществуващ шаблон и да промените кода му. Това ще спести както време, така и усилия. На следващото изображение нарекохме нашето звено за наблюдение „Топ 5 големи маси“. Избрахме го да бъде от тип диаграма (без добавяне) и осигурихме честота на опресняване от 30 секунди. Ние също така основаваме нашето звено за наблюдение на шаблона за размер на базата данни:
Текстовото поле Data Script се попълва автоматично с кода за единица за наблюдение на размера на базата данни:
от datetime import datetimefrom произволно импортиране randintdatabases =connection.Query(''' SELECT d.datname AS datname, round(pg_catalog.pg_database_size(d.datname)/1048576.0/1048576.0.datname)/1048576.0, d. datname не е в ('template0','template1')''')data =[]color =[]label =[]за db в бази данни.Редове: data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_databaseE N res WHER" ":етикет, "набори от данни":[ { "data":данни, "backgroundColor":цвят, "label":"Dataset 1" } (Dataset 1" „ MB)“}И текстовото поле Chart Script също се попълва с код:
total_size =connection.ExecuteScalar(''' ИЗБЕРЕТЕ кръг(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) ОТ pg_catalog.pg_database КЪДЕ НЕ НЕ НЕ ВЪЗНАЧИ""" datisulte"'' , "data":Няма, "options":{ "responsive":Вярно, "title":{ "display":True, "text":"Total S "_" } }}Можем да модифицираме Data Script, за да получим първите 5 големи таблици в базата данни. В скрипта по-долу сме запазили по-голямата част от оригиналния код, с изключение на SQL израза:
от datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" ОТ pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) КЪДЕ nspname НЕ В ('pg_catalog', 'information_schema') И C.relkind <> 'i' ~ AND '^p ER !_ ! BY 2 DESC LIMIT 5;'')data =[]color =[]label =[]за таблица в таблици.Редове: data.append(table["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(table["tablename" ])result ={ "labels":етикет, "datasets":[ { "data":данни, "backgroundColor":цвят, " pred. Таблица 5" "Тук получаваме комбинирания размер на всяка таблица и нейните индекси в текущата база данни. Сортираме резултатите в низходящ ред и избираме първите пет реда.
След това попълваме три масива на Python чрез повторение на набора от резултати.
И накрая, ние изграждаме JSON низ въз основа на стойностите на масивите.
В текстовото поле Chart Script сме променили кода, за да премахнем оригиналната SQL команда. Тук уточняваме само козметичния аспект на диаграмата. Ние дефинираме диаграмата като тип пай и предоставяме заглавие за нея:
result ={ "type":"pie", "data":Няма, "options":{ "responsive":True, "title":{ "display":True, 5" " " Таблици в текущата база данни (размер в MB)" } }}Сега можем да тестваме уреда, като щракнем върху иконата на светкавицата. Това ще покаже новата единица за наблюдение в областта за рисуване за предварителен преглед:
След това запазваме устройството, като щракнете върху иконата на диска. Кутия за съобщение потвърждава, че устройството е запазено:
Сега се връщаме към нашето табло за наблюдение и добавяме новия модул за наблюдение:
Забележете как имаме още две икони под колоната „Действия“ за нашия персонализиран модул за наблюдение. Единият е за редактирането му, а другият е за премахването му от OmniDB.
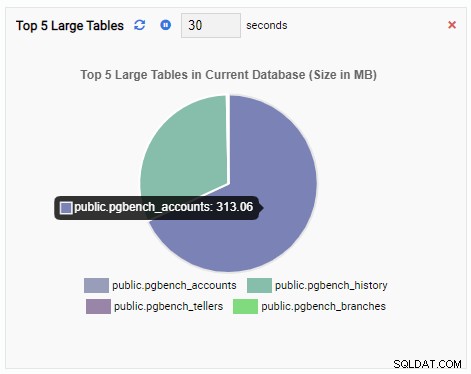
Звеното за наблюдение „Топ 5 големи таблици“ вече показва петте най-големи таблици в текущата база данни:
Ако затворим таблото, превключим към друга база данни от навигационния панел и отворим отново таблото, ще видим, че модулът за наблюдение се е променил, за да отразява таблиците на тази база данни:
Последни думи
Това завършва нашата серия от две части на OmniDB. Както видяхме, OmniDB има някои страхотни модули за наблюдение, които PostgreSQL DBA ще намерят за полезни за проследяване на производителността. Видяхме как можем да използваме тези единици, за да идентифицираме потенциални тесни места в сървъра. Видяхме и как да създадем свои собствени персонализирани единици. Читателите се насърчават да създават и тестват модули за наблюдение на производителността за техните специфични натоварвания. 2ndQuadrant приветства всеки принос към репозитория на OmniDB Monitoring Unit GitHub.