С въвеждането на Azure SQL база данни и добавянето на повече функционалност във v12, администраторите на бази данни започват да виждат, че организациите им се интересуват повече от преместване на бази данни към тази платформа.
Наскоро започнах да се гмуркам повече в Azure SQL база данни, за да видя какво е драстично различно от поддържането на кутията версия в центрове за данни по целия свят и Azure SQL база данни. В предишната си статия „Настройка:Добро място за начало“ разгледах подхода си за започване с настройка на SQL Server. Реших да прегледам това спрямо Azure SQL база данни, за да открия основните разлики.
В оригиналната си статия започнах с общи настройки на ниво екземпляр, които виждам игнорирани или оставени по подразбиране, както и елементи за поддръжка. Те включват памет, maxdop, праг на разходите за паралелизъм, позволяващ оптимизиране за ad hoc работни натоварвания и конфигуриране на tempdb. С Azure SQL Database вие не носите отговорност за екземпляра и не можете да променяте тези настройки. Azure SQL база данни е платформа като услуга (PaaS), което означава, че Microsoft управлява екземпляра вместо вас; вие сте просто наемател с вашата база данни или бази данни.
Вие обаче носите отговорност за поддръжката, така че трябва да актуализирате статистическите данни и да се справяте с фрагментацията на индекса, както правите за кутията. За тези задачи открих, че повечето клиенти управляват тези процеси със специална Azure VM, изпълняваща SQL Server и използвайки SQL Server Agent с планирани задачи.
Следвайки стъпките от моята статия, следващите области, които започвам да разглеждам, са статистиката за файлове и чакане и скъпите заявки. Ако се чудите дали този аспект от работата ви като производствен dba с локални бази данни ще се промени, когато работите с Azure SQL база данни, отговорът е не наистина . Статистиката за файлове и чакане все още има, но трябва да стигнем до тях по малко по-различен начин. Ако сте свикнали да използвате скриптовете на Пол Рандал за статистически данни за файлове и статистики за чакане (или заявките за статистически данни за файлове за определен период от време и статистика за изчакване за определен период от време), тогава ще трябва да направите някои промени, за да тези скриптове за работа с Azure SQL база данни.
Когато за първи път опитах скрипта за статистически данни на Paul, той се провали поради Azure SQL база данни, която не поддържа sys.master_files :
Невалидно име на обект 'sys.master_files'.
Успях да модифицирам скрипта, за да използвам sys.databases в присъединяването, за да получите името на базата данни и премахнете частта от скрипта, за да получите имената на отделните файлове, тъй като ще работим само с един файл с данни и регистрационен файл. Можете да видите промените, които трябваше да направя на следното изображение:
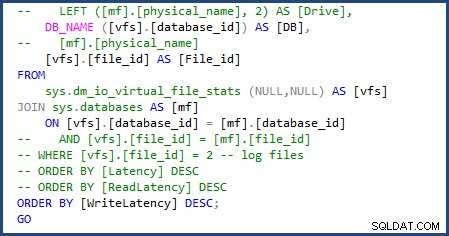
Когато изпълних скрипта file-stats-over-a-period-of-time, направих същата промяна в sys.databases и премахване на препратките към file_id в присъединяването се провали, тъй като Azure SQL Database v12 не поддържа глобални ##temp таблици.
След като промених всички глобални ##temp таблици на локални, имах друг проблем със скрипта, който не можеше да махне съществуващите временни таблици, които бяха използвани, тъй като локалните #temp таблици не могат да бъдат препращани директно по име, както глобалните ##temp таблици могат, но това беше лесно за преодоляване, като промените тези проверки на OBJECT_ID('tempdb..#SQLskillsStats1') . Направих същата промяна за втората временна таблица и актуализирах блока от код в началото и края на скрипта.
Трябваше да направя още една промяна и да премахна [mf].[type_desc] и LEFT ([mf].[physical_name], 2) AS [Drive] тъй като те зависят от sys.master_files . След това скриптът беше завършен и готов за използване с Azure SQL база данни.
Използвам файл-статистика-за-период от време редовно, когато отстранявам проблеми с производителността. Кумулативните данни имат своята цел, но аз се интересувам повече от конкретни сегменти от време, когато се изпълняват потребителски натоварвания.
Със статистическите данни за файловете сме загрижени за нашата латентност на файл на база данни и как можем да настроим, за да помогнем за намаляване на общия I/O. Подходът е същият като SQL Server, където трябва да настроите правилно заявките си и да имате правилните индекси. Ако работното натоварване е твърде голямо, тогава трябва да преминете към по-бързо работещо ниво на база данни на DTU. За мен това е страхотно:просто хвърляш хардуер към него; но всъщност не е хардуер в традиционния смисъл. С Azure SQL Database можете да започнете с по-евтино ниво и мащаб с нарастването на изискванията на вашия бизнес и I/O – по същество само с натискане на превключвател.
Опитът да се намери най-добрият метод за получаване на статистика за чакане беше по-лесен. Стандартният скрипт, който много от нас използват, все още работи, но извлича статистика за изчакване за контейнера, в който се изпълнява вашата база данни. Тези изчаквания все още се отнасят за вашата система, но могат да включват изчаквания, направени от други бази данни в същия контейнер. Azure SQL база данни съдържа нов DMV, sys.dm_db_wait_stats , който филтрира към текущата база данни. Ако сте като мен и използвате предимно скрипта за статистика на чакане на Пол, който пропуска всички доброкачествени изчаквания, просто променете sys.dm_os_wait_stats към sys.dm_db_wait_stats . Същата промяна работи и за скрипта за изчакване-над-период от време, но също така трябва да направите промяната от глобални променливи към локални.
Когато става въпрос за намиране на заявки с висока цена, един от любимите ми скриптове за изпълнение намира най-използваните планове за изпълнение. Според моя опит настройката на заявка, която се извиква 100 000 пъти на ден, обикновено е по-голяма печалба от настройката на заявка, която има най-висок IO, но се изпълнява само веднъж седмично. Следната заявка е това, което използвам, за да намеря най-използваните планове:
ИЗБЕРЕТЕ usecounts , cacheobjtype , objtype , [текст]ОТ sys.dm_exec_cached_plans КРЪСТНО ПРИЛАГАНЕ sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 И objtype IN ( N'Adhoc'), N'Prepared's DEPREPARED; предварително>Когато използвам тази заявка в демонстрации, винаги промивам кеша на плана си, за да нулирам стойностите. Когато се опитах да стартирам
DBCC FREEPROCCACHEв Azure SQL база данни получих следната грешка:Оказва се, че
SQL Azure в момента не поддържа DBCC FREEPROCCACHE (Transact-SQL), така че не можете ръчно да премахнете план за изпълнение от кеша. Въпреки това, ако направите промени в таблицата или изгледа, посочени от заявката (ALTER TABLE и ALTER VIEW), планът ще бъде премахнат от кеша.DBCC FREEPROCCACHEне се поддържа в Azure SQL база данни. Това ме притесняваше, какво ще стане, ако съм в производство и имам лоши планове и искам да изчистя кеша на процедурите, както мога с кутията версия. Малко проучване на Google/Bing ме накара да намеря статията на Microsoft „Разбиране на кеша на процедурите в SQL Azure“, която гласи:Обсъждайки това с Кимбърли Трип, след като не вижда описаното поведение, той не изтрива плана от кеша, но прави плана невалиден (и тогава планът в крайна сметка ще бъде остарял от кеша). Въпреки че това е полезно в определени ситуации, това не беше това, от което имах нужда. За моята демонстрация исках да нулирам броячите в sys.dm_exec_cached_plans. Генерирането на нов план няма да ми даде желаните резултати. Свързах се с моя екип и Глен Бери ми каза да опитам следния скрипт:
ПРОМЕНЯ КОНФИГУРАЦИЯ С ОБХВАТ НА БАЗА ДАННИ ИЗЧИСТВАНЕ НА ПРОЦЕДУРА_КЕШ;Тази команда работи; Успях да изчистя кеша на процедурите за конкретната база данни. Конфигурациите с обхват на базата данни е нова функция, добавена в SQL Server 2016 RC0; Глен пише за това тук:Използване на ALTER DATABASE SCOPED CONFIGURATION в SQL Server 2016.
Развълнуван съм да преместя няколко от моите собствени бази данни в Azure SQL база данни и да продължа да уча за новите функции и опции за мащабируемост. Също така с нетърпение очаквам да работя със SentryOne DB Sentry, скорошно допълнение към платформата SentryOne. Най-много се интересувам от експериментиране с таблото за използване на DTU, което Майк Ууд описа в скорошната си публикация.