Накратко споменах, че данните в пакетния режим са нормализирани в последната ми статия Растерни изображения в пакетен режим в SQL Server. Всички данни в пакет се представят с осем байтова стойност в този конкретен нормализиран формат, независимо от основния тип данни.
Това твърдение без съмнение повдига някои въпроси, не на последно място относно това как е възможно данни с дължина много по-голяма от осем байта да се съхраняват по този начин. Тази статия изследва нормализираното представяне на пакетните данни, обяснява защо не всички осембайтови типове данни могат да се поберат в рамките на 64 бита и показва пример за това как всичко това се отразява на производителността в пакетния режим.
Демо
Ще започна с пример, който показва, че форматът на пакетните данни прави важна разлика в плана за изпълнение. Ще ви трябват SQL Server 2016 (или по-нова версия) и издание за разработчици (или еквивалент), за да възпроизведете резултатите, показани тук.
Първото нещо, което ще ни трябва, е таблица на bigint числа от 1 до 102 400 включително. Тези числа ще бъдат използвани за попълване на таблица с columnstore скоро (броят на редовете е минимумът, необходим за получаване на един компресиран сегмент).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Успешно обобщено избутване надолу
Следният скрипт използва таблицата с числа, за да създаде друга таблица, съдържаща същите числа, изместени с конкретна стойност. Тази таблица използва columnstore за основното си хранилище, за да произведе изпълнение в пакетен режим по-късно.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Изпълнете следните тестови заявки към новата таблица columnstore:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Добавката вътре в SUM е да се избегне преливане. Можете да пропуснете WHERE клаузи (за да избегнете тривиален план), ако използвате SQL Server 2017.
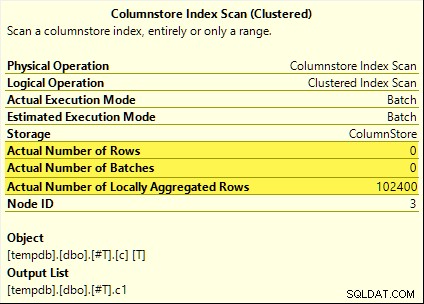
Всички тези заявки се възползват от обобщено избутване. Агрегатът се изчислява при Сканиране на индекса на Columnstore вместо Hash Aggregate в пакетен режим оператор. Плановете след изпълнение показват нулеви редове, излъчени от сканирането. Всичките 102 400 реда бяха „локално агрегирани“.
SUM планът е показан по-долу като пример:

Неуспешно обобщено избутване надолу
Сега пуснете и след това създайте отново тестовата таблица на columnstore с отместване, намалено с едно:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Изпълнете точно същите обобщени тестови заявки за натискане, както преди:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Този път само COUNT_BIG aggregate постига избутване на агрегата (само за SQL Server 2017). MAX и SUM агрегатите не го правят. Ето новия SUM план за сравнение с този от първия тест:

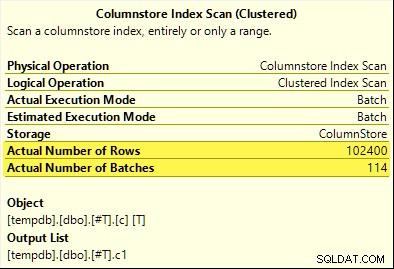
Всички 102 400 реда (в 114 партиди) се излъчват от Columnstore Index Scan , обработена от Compute Scalar , и се изпраща до Hash Aggregate .
Защо разликата? Всичко, което направихме, беше да компенсираме диапазона от числа, съхранени в таблицата columnstore, с едно!
Обяснение
Споменах във въведението, че не всички осембайтови типове данни могат да се поберат в 64 бита. Този факт е важен тъй като много оптимизации на производителността на columnstore и пакетен режим работят само с данни с размер 64 бита. Агрегатното избутване е едно от тези неща. Има много повече функции за производителност (не всички документирани), които работят най-добре (или изобщо) само когато данните се побират в 64 бита.
В нашия конкретен пример обобщеното избутване е деактивирано за сегмент на columnstore, когато съдържа дори един стойност на данните, която не се побира в 64 бита. SQL Server може да определи това от метаданните за минимална и максимална стойност, свързани с всеки сегмент, без да проверява всички данни. Всеки сегмент се оценява отделно.
Обобщеното избутване все още работи за COUNT_BIG агрегат само във втория тест. Това е оптимизация, добавена в някакъв момент в SQL Server 2017 (тестовете ми бяха проведени на CU16). Логично е да не деактивираме обобщеното избутване, когато броим само редове и не правим нищо с конкретните стойности на данните. Не можах да намеря никаква документация за това подобрение, но това не е толкова необичайно в наши дни.
Като странична бележка забелязах, че SQL Server 2017 CU16 позволява обобщено избутване за неподдържаните преди това типове данни real , float , datetimeoffset и numeric с точност по-голяма от 18 — когато данните се побират в 64 бита. Това също е недокументирано към момента на писане.
Добре, но защо?
Може би си задавате много разумния въпрос:Защо един набор от bigint тестовите стойности очевидно се вписват в 64 бита, но другите не?
Ако сте предположили, че причината е свързана с NULL , дайте си отметка. Въпреки че колоната на тестовата таблица е дефинирана като NOT NULL , SQL Server използва същото нормализирано оформление на данни за bigint дали данните позволяват нулеви стойности или не. Има причини за това, които ще разопаковам малко по малко.
Нека започна с някои наблюдения:
- Всяка стойност на колона в партида се съхранява в точно осем байта (64 бита), независимо от основния тип данни. Това оформление с фиксиран размер прави всичко по-лесно и по-бързо. Изпълнението в пакетен режим е свързано със скоростта.
- Пакетът е с размер 64 КБ и съдържа между 64 и 900 реда, в зависимост от броя на колоните, които се проектират. Това има смисъл, като се има предвид, че размерите на данните в колоните са фиксирани на 64 бита. Повече колони означава, че по-малко редове могат да се поберат във всяка партида от 64 КБ.
- Не всички типове данни на SQL Server могат да се поберат в 64 бита, дори по принцип. Дълъг низ (за един пример) може дори да не се побере в цяла партида от 64 КБ (ако това беше разрешено), да не говорим за един 64-битов запис.
SQL Server решава този последен проблем, като съхранява 8-байтова препратка към данни, по-големи от 64 бита. „Голямата“ стойност на данните се съхранява другаде в паметта. Можете да наречете това подреждане „извънредово“ или „извънпартидно“ съхранение. Вътрешно се наричат дълбоки данни .
Сега осембайтовите типове данни не могат да се поберат в 64 бита, когато са нулеви. Вземете bigint NULL например . Ненулевият диапазон от данни може да изисква пълните 64 бита и ние все още се нуждаем от още един бит, за да посочим нула или не.
Решаване на проблемите
Творческото и ефективно решение на тези предизвикателства е да се запазят най-ниската значима част (LSB) на 64-битовата стойност като флаг. Знамето показва в партида съхранение на данни, когато LSB е изчистен (настроен на нула). Когато LSB енастроен (до едно), това може да означава едно от двете неща:
- Стойността е нула; или
- Стойността се съхранява извън пакета (това са дълбоки данни).
Тези два случая се отличават със състоянието на останалите 63 бита. Когато са всички нула , стойността е NULL . В противен случай „стойността“ е указател към дълбоки данни, съхранявани другаде.
Когато се разглежда като цяло число, задаването на LSB означава, че указателите към дълбоки данни винаги ще бъдат нечетни числа. Нулевите числа са представени с (нечетно) число 1 (всички останали битове са нула). Данните в партидата са представени с четни числа, защото LSB е нула.
Това ене означава, че SQL Server може да съхранява само четни числа в рамките на партида! Това просто означава, че нормализираното представяне от стойностите на основните колони винаги ще имат нулев LSB, когато се съхраняват „в партида“. Това ще има повече смисъл след момент.
Нормализация на пакетни данни
Нормализирането се извършва по различни начини, в зависимост от основния тип данни. За bigint процесът е:
- Ако данните са нулеви , съхранява стойността 1 (само LSB е зададено).
- Ако стойността може да бъде представена в 63 бита , изместете всички битове едно място наляво и нулирайте LSB. Когато разглеждате стойността като цяло число, това означава удвояване стойността. Например
bigintстойност 1 се нормализира до стойност 2. В двоичен формат това е седем байта с всички нула, последвани от00000010. LSB е нула означава, че това са данни, съхранявани на линия. Когато SQL Server се нуждае от оригиналната стойност, той измества надясно 64-битовата стойност с една позиция (изхвърля LSB флага). - Ако стойността не може бъде представена в 63 бита, стойността се съхранява извън пакета като дълбоки данни . Указателят в партидата има зададен LSB (което го прави нечетно число).
Процесът на тестване дали е bigint стойността, която може да се побере в 63 бита, е:
- Съхранете необработения*
bigintстойност в регистъра на 64-битов процесорr8. - Запазване на двойна стойност на
r8в регистъраrax. - Изместете битовете на
raxедно място вдясно. - Проверете дали стойностите в
raxиr8са равни.
* Обърнете внимание, че необработената стойност не може да бъде надеждно определена за всички типове данни чрез T-SQL преобразуване в двоичен тип. Резултатът от T-SQL може да има различен ред на байтове и може също да съдържа метаданни, напр. time дробна секунда точност.
Ако тестът в стъпка 4 премине, ние знаем, че стойността може да бъде удвоена и след това намалена наполовина в рамките на 64 бита – запазвайки оригиналната стойност.
Намален диапазон
Резултатът от всичко това е, че диапазонът на bigint стойностите, които могат да се съхраняват в партида, се намалява с един бит (тъй като LSB не е наличен). Следните включващи диапазони на bigint стойностите ще се съхраняват извън пакета като дълбоки данни :
- -4,611,686,018,427,387,905 до -9,223,372,036,854,775,808
- +4,611,686,018,427,387,904 до +9,223,372,036,854,775,807
В замяна на приемането на тези bigint ограничения на диапазона, нормализирането позволява на SQL Server да съхранява (повечето) bigint стойности, нулеви стойности и дълбоки препратки към данни в партида . Това е много по-просто и по-ефективно, отколкото да имате отделни структури за нулиране и дълбоки препратки към данни. Освен това прави обработката на пакетни данни с инструкции на SIMD процесора много по-лесна.
Нормализация на други типове данни
SQL Server съдържа нормализация код за всеки от типовете данни, поддържани от пакетно изпълнение. Всяка рутина е оптимизирана да обработва ефективно входящото двоично оформление и да създава дълбоки данни само когато е необходимо. Нормализирането винаги води до това, че LSB е запазен за нулеви или дълбоки данни, но оформлението на останалите 63 бита варира в зависимост от типа данни.
Винаги в партида
Нормализираните данни за следните типове данни винаги се съхраняват в пакет тъй като никога не се нуждаят от повече от 63 бита:
datetime(n)– вътрешно мащабирано доtime(7)datetime2(n)– вътрешно мащабирано доdatetime2(7)integersmallinttinyintbit– използваtinyintизпълнение.smalldatetimedatetimerealfloatsmallmoney
Зависи
Следните типове данни могат да се съхраняват в пакет или дълбоки данни в зависимост от стойността на данните:
bigint– както е описано по-горе.money– същият диапазон в партида катоbigintно разделено на 10 000.numeric/decimal– 18 десетични цифри или по-малко в партида независимо с декларирана прецизност. Напримерdecimal(38,9)стойност -999999999,999999999 може да бъде представена като цяло число от 8 байта -999999999999999999 (f21f494c589c0001шестнадесетичен), който може да се удвои до -1999999999999999998 (e43e9298b1380002hex) обратимо в рамките на 64 бита. SQL Server знае къде отива десетичната запетая от скалата на типа данни.datetimeoffset(n)– в партида, ако стойността по време на изпълнение ще се побере вdatetimeoffset(2)независимо с декларирана точност в дробни секунди.timestamp– вътрешният формат е различен от дисплея. Напримерtimestampпоказва се от T-SQL като0x000000000099449Aе представен вътрешно като9a449900 00000000(в шестнадесетичен). Тази стойност се съхранява като дълбоки данни, тъй като не се вписва в 64-бита, когато се удвои (изместено наляво с един бит).
Винаги дълбоки данни
Следните винаги се съхраняват като дълбоки данни (с изключение на нулеви стойности) :
uniqueidentifiervarbinary(n)– включително(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameвключително(max)– тези типове могат да използват и речник (когато е наличен).text/ntext/image/xml– използваvarbinary(n)изпълнение.
За да бъде ясно, нула за всички Типовете данни, съвместими с пакетен режим, се съхраняват в пакета като специалната стойност „един“.
Последни мисли
Може да очаквате да направите най-доброто от наличните оптимизации на columnstore и пакетен режим, когато използвате типове данни и стойности, които се вписват в 64 бита. Освен това ще имате най-добрия шанс да се възползвате от постепенните подобрения на продуктите с течение на времето, например най-новите подобрения на обобщаващото избутване, отбелязани в основния текст. Не всички предимства на производителността ще бъдат толкова видими в плановете за изпълнение или дори документирани. Независимо от това, разликите могат да бъдат изключително значителни.
Трябва също да спомена, че данните се нормализират, когато оператор на план за изпълнение в режим на ред предоставя данни на родител в пакетен режим или когато сканиране без колони произвежда партиди (партиден режим на rowstore). Има невидим адаптер ред към партида, който извиква подходяща нормализираща програма за всяка стойност на колона, преди да я добави към партидата. Избягването на типове данни със сложна нормализиране и дълбоко съхранение на данни може да доведе до ползи за производителността и тук.