Ако използвате разделяне на таблици с един или повече дялове, съхранени във файлова група само за четене, SQL изразите за актуализиране и изтриване може да се провалят с грешка. Разбира се, това е очакваното поведение, ако някоя от модификациите изисква запис във файлова група само за четене; но също така е възможно да срещнете това условие за грешка, когато промените са ограничени до файлови групи, маркирани като четене-запис.
Примерна база данни
За да демонстрираме проблема, ще създадем проста база данни с една персонализирана файлова група, която по-късно ще маркираме като само за четене. Имайте предвид, че ще трябва да добавите пътя към името на файла, за да отговаря на вашия тестов екземпляр.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Функция и схема на разделяне
Сега ще създадем основна функция за разделяне и схема, която ще насочва редове с данни преди 1 януари 2000 г. към дяла само за четене. По-късните данни ще се съхраняват в основната файлова група за четене и запис:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); Спецификацията на диапазона вдясно означава, че редове с гранична стойност 1 януари 2000 г. ще бъдат в дяла за четене и запис.
Разделена таблица и индекси
Вече можем да създадем нашата тестова таблица:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); Таблицата има клъстериран първичен ключ в колоната дата и час и също е разделена на тази колона. В другите две колони с цели числа има неклъстерирани индекси, които са разделени по същия начин (индексите са подравнени с основната таблица).
Примерни данни
Накрая добавяме няколко реда примерни данни и правим дяла с данни преди 2000 г. само за четене:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
Можете да използвате следните тестови инструкции за актуализиране, за да потвърдите, че данните в дяла само за четене не могат да бъдат променени, докато данните с dt стойност на или след 1 януари 2000 г. може да бъде записана на:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Неочакван провал
Имаме два реда:един само за четене (1999-12-31); и едно четене-запис (2000-01-01):

Сега опитайте следната заявка. Той идентифицира същия ред за запис "2000-01-01", който току-що актуализирахме успешно, но използва различен предикат where клауза:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Прогнозният (предварително изпълнение) план е:

Четирите (!) Изчислителни скалари не са важни за тази дискусия. Те се използват, за да се определи дали неклъстерираният индекс трябва да се поддържа за всеки ред, който пристига в оператора за актуализиране на клъстериран индекс.
По-интересното е, че тази декларация за актуализация неуспешна с грешка, подобна на:
Msg 652, ниво 16, състояние 1Индексът "PK_dbo_Test__c1_dt" за таблица "dbo.Test" (RowsetId 72057594039042048) се намира във файлова група само за четене ("ReadOnlyFileGro"), която не може да бъде модифицирана.
Не елиминиране на дял
Ако сте работили с разделяне преди, може би си мислите, че причината може да е „елиминирането на дяла“. Логиката би била нещо подобно:
В предишните изявления литерална стойност за колоната за разделяне беше предоставена в клаузата where, така че SQL Server ще може да определи незабавно до кой дял(и) да има достъп. Чрез промяна на клаузата where така, че вече да не се позовава на колоната за разделяне, ние принудихме SQL Server да има достъп до всеки дял, използвайки сканиране на клъстериран индекс.
Като цяло това е вярно, но не това е причината, поради която изявлението за актуализиране се проваля тук.
Очакваното поведение е SQL Server да може да чете от всеки и всички дялове по време на изпълнение на заявка. Операция за промяна на данни трябва само неуспешна ако машината за изпълнение всъщност се опитва да промени ред, съхранен във файлова група само за четене.
За да илюстрираме, нека направим малка промяна в предишната заявка:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; Клаузата where е абсолютно същата като преди. Единствената разлика е, че сега (умишлено) задаваме колоната за разделяне равна на самата себе си. Това няма да промени стойността, съхранена в тази колона, но ще се отрази на резултата. Актуализацията сега успешна (макар и с по-сложен план за изпълнение):

Оптимизаторът въведе нови оператори Split, Sort и Collapse и добави машината, необходима за поддържане на всеки потенциално засегнат неклъстериран индекс поотделно (използвайки широка стратегия или стратегия за индекс).
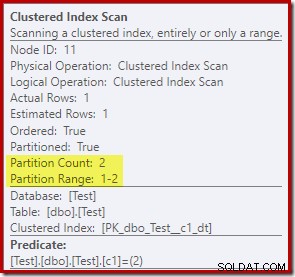
Свойствата на Clustered Index Scan показват, че и двата дяла от таблицата бяха достъпни при четене:
За разлика от това, актуализацията на клъстерирания индекс показва, че само дялът за четене-запис е бил достъпен за запис:
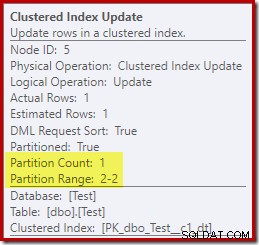
Всеки от операторите за актуализиране на неклъстерирания индекс показва подобна информация:само дялът за запис (#2) е променен по време на изпълнение, така че не е възникнала грешка.
Разкритата причина
Новият план е успешенне тъй като неклъстерираните индекси се поддържат отделно; нито това (директно) се дължи на комбинацията Split-Sort-Collapse, необходима за избягване на преходни грешки при дублиране на ключове в уникалния индекс.
Истинската причина е нещо, което споменах накратко в предишната си статия „Оптимизиране на заявки за актуализиране“ – вътрешна оптимизация, известна като Споделяне на набор от редове . Когато това се използва, актуализацията на клъстериран индекс споделя същия набор от редове в основата на механизма за съхранение като сканиране на клъстериран индекс, търсене или търсене на ключ от страната за четене на плана.
С оптимизацията за споделяне на набор от редове SQL Server проверява за офлайн или файлови групи само за четене при четене. В планове, при които актуализацията на клъстериран индекс използва отделен набор от редове, проверката офлайн/само за четене се извършва само за всеки ред в итератора за актуализиране (или изтриване).
Недокументирани решения
Нека първо премахнем забавните, странни, но непрактични неща.
Оптимизацията на споделения набор от редове може да се приложи само когато маршрутът от клъстерното търсене, сканиране или ключово търсене е тръбопровод . Не са разрешени блокиращи или полублокиращи оператори. Казано по друг начин, всеки ред трябва да може да стигне от източника за четене до местоназначението за запис, преди да бъде прочетен следващият ред.
Като напомняне, ето примерните данни, изявление и план за изпълнение за неуспешното актуализирайте отново:
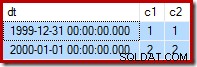
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Защита за Хелоуин
Един от начините за въвеждане на блокиращ оператор в плана е да се изисква изрична защита за Хелоуин (HP) за тази актуализация. Разделянето на четенето от записа с блокиращ оператор ще предотврати използването на оптимизацията за споделяне на набор от редове (без конвейер). Недокументиран и неподдържан (само за тестовата система!) флаг за проследяване 8692 добавя Eager Table Spool за изрично HP:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Действителният план за изпълнение (наличен, защото грешката вече не се извежда) е:

Сортирането в комбинацията Split-Sort-Collapse, видяна в по-ранната успешна актуализация, осигурява блокирането, необходимо за деактивиране на споделянето на набор от редове в този случай.
Флагът за проследяване на споделяне на набор от редове
Има още един недокументиран флаг за проследяване, който деактивира оптимизацията за споделяне на набор от редове. Това има предимството, че не се въвежда потенциално скъп блокиращ оператор. Разбира се, не може да се използва на практика (освен ако не се свържете с поддръжката на Microsoft и не получите писмено нещо, което препоръчва да го активирате, предполагам). Въпреки това, за развлекателни цели, ето флаг за проследяване 8746 в действие:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Действителният план за изпълнение на това изявление е:

Чувствайте се свободни да експериментирате с различни стойности (такива, които всъщност променят съхранените стойности, ако желаете), за да се убедите в разликата тук. Както споменах в предишната ми публикация, можете също да използвате недокументиран флаг за проследяване 8666, за да разкриете свойството за споделяне на набор от редове в плана за изпълнение.
Ако искате да видите грешката при споделяне на набор от редове с израз за изтриване, просто заменете клаузите за актуализиране и задаване с изтриване, като използвате същата клауза where.
Поддържани решения
Има голям брой потенциални начини да се гарантира, че споделянето на набор от редове не се прилага в заявки в реалния свят, без да се използват флагове за проследяване. Сега, когато знаете, че основният проблем изисква споделен и конвейерен клъстерен план за четене и запис на индекс, вероятно можете да измислите свой собствен. Въпреки това има няколко примера, които си заслужава да бъдат разгледани тук.
Принудителен индекс / Покриващ индекс
Една естествена идея е да се принуди страната за четене на плана да използва неклъстериран индекс вместо клъстериран индекс. Не можем да добавим подсказка за индекс директно към тестовата заявка, както е написана, но псевдонимът на таблицата позволява това:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Това може да изглежда като решението, което оптимизаторът на заявки трябваше да избере на първо място, тъй като имаме неклъстериран индекс в колоната с предикат на клаузата where c1. Планът за изпълнение показва защо оптимизаторът е избрал така:
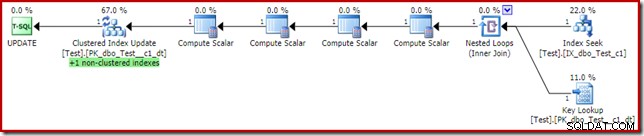
Цената на Key Lookup е достатъчна, за да убеди оптимизатора да използва клъстерирания индекс за четене. Търсенето е необходимо за извличане на текущата стойност на колона c2, така че изчислителните скалари могат да решат дали неклъстерираният индекс трябва да се поддържа.
Добавянето на колона c2 към неклъстерирания индекс (ключ или включване) ще избегне проблема. Оптимизаторът ще избере сега покриващия индекс вместо клъстерирания индекс.
Въпреки това не винаги е възможно да се предвидят кои колони ще са необходими или да се включат всички, дори ако наборът е известен. Не забравяйте, че колоната е необходима, защото c2 е в клаузата set на декларацията за актуализиране. Ако заявките са ad hoc (например изпратени от потребители или генерирани от инструмент), всеки неклъстериран индекс ще трябва да включва всички колони, за да направи това надеждна опция.
Едно интересно нещо за плана с Key Lookup по-горе е, че той не генерира грешка. Това е въпреки търсенето на ключове и актуализацията на клъстерирания индекс с помощта на споделен набор от редове. Причината е, че неклъстерираното търсене на индекси намира реда с c1 =2 преди ключовото търсене докосва клъстерирания индекс. Споделената проверка на набор от редове за файлови групи офлайн/само за четене все още се извършва при търсене, но не докосва дяла само за четене, така че не се извежда грешка. Като последна (свързана) точка на интерес, имайте предвид, че търсенето в индекс докосва и двата дяла, но търсенето на ключове удря само единия.
С изключение на дяла само за четене
Тривиално решение е да се разчита на елиминиране на дял, така че страната за четене на плана никога да не докосва дяла само за четене. Това може да стане с изричен предикат, например едно от следните:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Когато е невъзможно или неудобно да промените всяка заявка, за да добавите предикат за елиминиране на дял, могат да бъдат подходящи други решения като актуализиране чрез изглед. Например:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; Един недостатък на използването на изглед е, че актуализацията или изтриването, което е насочено към частта само за четене на основната таблица, ще успее без засегнати редове, вместо да се провали с грешка. Вместо задействане на таблицата или изгледа може да бъде заобиколно решение за това в някои ситуации, но може да доведе и до повече проблеми...но се отклоних.
Както бе споменато по-горе, има много потенциални поддържани решения. Целта на тази статия е да покаже как споделянето на набор от редове е причинило неочакваната грешка при актуализиране.



