Забележка:Тази публикация първоначално е публикувана само в нашата електронна книга, Високопроизводителни техники за SQL Server, том 4. Можете да научите за нашите електронни книги тук.
Редовно ми задават въпроса „Откъде да започна, когато става въпрос за опит за настройка на екземпляр на SQL Server?“ Първият ми отговор е да ги попитам за конфигурацията на техния екземпляр. Ако някои неща не са конфигурирани правилно, тогава започването да разглеждате дълготрайни или скъпи заявки веднага може да бъде напразно усилие.
Водил съм блог за често срещани неща, които администраторите пропускат, където споделям много от настройките, които администраторите трябва да променят от инсталация по подразбиране на SQL Server. За елементи, свързани с производителността, им казвам, че трябва да проверят следното:
- Настройки на паметта
- Актуализиране на статистическите данни
- Поддръжка на индекса
- MAXDOP и праг на разходите за паралелизъм
- най-добри практики за tempdb
- Оптимизиране за ad hoc работни натоварвания
След като премина през конфигурационните елементи, питам дали са прегледали статистики за файлове и чакане, както и скъпи заявки. През повечето време отговорът е „не“ – с обяснение, че не са сигурни как да намерят тази информация.
Обикновено често срещаното съответствие, когато някой заявява, че трябва да настрои SQL Server, е, че той работи бавно. Какво означава бавно? Дали това е определен доклад, конкретно приложение или всичко? Току-що започна ли да се случва или се влошава с времето? Започвам със задаването на обичайните триажни въпроси за това какво е използването на паметта, процесора и диска в сравнение с това, когато нещата са нормални, започна ли да се случва проблемът и какво се промени наскоро. Освен ако клиентът не улавя базова линия, те нямат показатели, с които да се сравняват, за да знаят дали текущите статистически данни са ненормални.
Почти всеки SQL Server, на който работя, е домакин на повече от една потребителска база данни. Когато клиент съобщи, че SQL Server работи бавно, през повечето време той е загрижен за конкретно приложение, което причинява проблеми на клиентите им. Реакцията на коляно е незабавно да се съсредоточи върху тази конкретна база данни, но често пъти друг процес може да изразходва ценни ресурси и базата данни на приложението е засегната. Например, ако имате голяма база данни за отчети и някой стартира масивен отчет, който насища диска, увеличава процесора и промива кеша на плана, можете да се обзаложите, че другите потребителски бази данни ще се забавят, докато този отчет се генерира.
Винаги обичам да започвам с разглеждане на статистиката на файла. За SQL Server 2005 и по-нова версия, можете да потърсите DMV sys.dm_io_virtual_file_stats, за да получите статистически данни за I/O за всеки файл с данни и журнал. Този DMV замени функцията fn_virtualfilestats. За да заснема статистическите данни на файла, обичам да използвам скрипт, който Пол Рандъл събра:улавяне на IO латентности за определен период от време. Този скрипт ще улови базова линия и 30 минути по-късно (освен ако не промените продължителността в секцията WAITFOR DELAY) ще улови статистиката и ще изчисли делтите между тях. Сценарият на Пол също прави малко математика, за да определи латентностите за четене и запис, което ни прави много по-лесно за четене и разбиране.
На моя лаптоп възстанових копие на базата данни AdventureWorks2014 на USB устройство, така че да имам по-ниска скорост на диска; След това стартирах процес за генериране на натоварване срещу него. Можете да видите резултатите по-долу, където забавянето ми на запис за моя файл с данни е 240 мс, а забавянето на запис за моя регистрационен файл е 46 мс. Това високи закъснения са обезпокоителни.
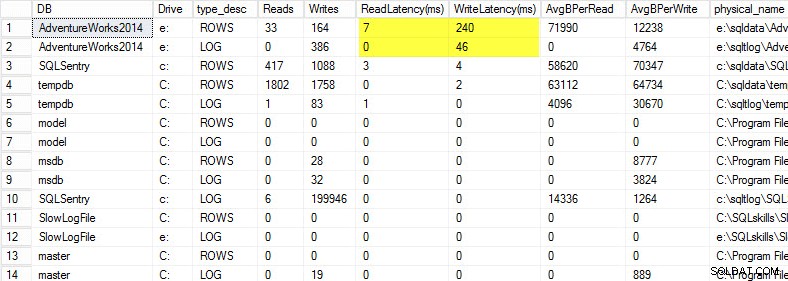
Всичко над 20 мс трябва да се счита за лошо, както споделих в предишна публикация:наблюдение на латентността при четене/запис. Закъснението ми при четене е прилично, но базата данни AdventureWorks2014 страда от бавно записване. В този случай бих проучил какво генерира записите, както и производителността на моята I/O подсистема. Ако това беше прекалено голямо забавяне на четене, щях да започна да изследвам производителността на заявката (защо прави толкова много четения, например от липсващи индекси), както и цялостната производителност на I/O подсистемата.
Важно е да знаете цялостната производителност на вашата I/O подсистема и най-добрият начин да разберете на какво е способна е като я сравните. Глен Бери говори за това в статията си, анализираща I/O производителността за SQL Server. Глен обяснява латентността, IOPS и пропускателната способност и показва CrystalDiskMark, който е безплатен инструмент, който можете да използвате, за да изравните своето хранилище.
След като разбера как се представят статистическите данни на файла, обичам да разглеждам статистиката за чакане, като използвам DMV sys.dm_os_wait_stats, който връща информация за всички изчаквания, които са се случили. За това се обръщам към друг скрипт, който Пол Рандал предоставя в своята публикация в блога за заснемане на статистика за чакане за определен период от време. Сценарият на Пол отново прави малко математика за нас, но по-важното е, че изключва много от безобидните изчаквания, за които обикновено не ни пука. Този скрипт също има ЗАКАЗАНЕ НА ИЗЧАКВАНЕ и е настроен на 30 минути. Четенето на статистически данни за изчакване може да бъде малко по-трудно:може да имате изчаквания, които изглеждат високи въз основа на процент, но средното изчакване е толкова ниско, че няма за какво да се притеснявате.
Започнах същия процес на зареждане и заснех статистиката си за чакане, която показах по-долу. За обяснения за много от тези видове чакане можете да прочетете друга от публикациите в блога на Пол, статистиката за чакане или, моля, кажете ми къде боли, както и някои от публикациите му в този блог.
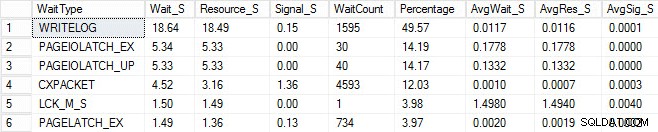
В този измислен изход PAGEIOLATCH изчакването може да показва затруднено място с моята входно/изходна подсистема, но може също да е проблем с паметта, сканиране на таблицата вместо търсене или множество други проблеми. В моя случай знаем, че е проблем с диска, тъй като съхранявам базата данни на USB флаш. Времето за изчакване LCK_M_S е много голямо, но има само един екземпляр на изчакване. Моят WRITELOG също е по-висок, отколкото бих искал да видя, но е разбираемо, като се знаят проблемите с латентността с USB паметта. Това също показва, че CXPACKET чака и би било лесно да получите реакция на коляно и да си помислите, че имате проблем с паралелизъм/MAXDOP, но броячът AvgWait_S е много нисък. Бъдете внимателни, когато използвате изчакване за отстраняване на неизправности. Нека бъде ръководство, което да ви каже неща, които не са проблем, както и да ви даде насока къде да отидете да търсите проблеми. Правилното отстраняване на неизправности е съпоставяне на поведението от множество области, за да се стесни проблема.
След като разгледах файла и изчаках статистиката, започвам да ровя в заявките с висока цена въз основа на проблемите, които открих. За това се обръщам към Запитвания за диагностична информация на Glenn Berry. Тези набори от заявки са скриптовете, които използват много консултанти. Глен и общността непрекъснато предоставят актуализации, за да ги направят възможно най-информативни и стабилни. Една от любимите ми заявки е най-често кешираните заявки по брой изпълнения. Обичам да намирам заявки или съхранени процедури, които имат висок брой execution_count, съчетан с високи total_logical_reads. Ако тези заявки имат възможности за настройка, тогава можете бързо да направите голяма разлика в сървъра. Също така в скриптовете са включени най-кеширани SP по общо логически четения и най-кеширани SP по общи физически четения. И двете са добри за търсене на високо четене с голям брой изпълнения, така че можете да намалите броя на I/O.
В допълнение към скриптовете на Glenn, аз обичам да използвам sp_whoisactive на Adam Machanic, за да видя какво се изпълнява в момента.
Има много повече за настройката на производителността от просто гледане на статистики за файлове и чакане и скъпи заявки, но аз обичам да започна оттам. Това е начин за бързо сортиране на среда, за да започнете да определяте какво причинява проблема. Няма напълно безупречен начин за настройка:това, от което се нуждае всеки производствен DBA, е контролен списък с неща, през които трябва да премине, за да се елиминира и наистина добра колекция от скриптове, през които да се изпълни, за да се анализира здравето на системата. Наличието на изходно ниво е от ключово значение за бързото изключване на нормалното спрямо ненормалното поведение. Моят добър приятел Ерин Стелато има цял курс по Pluralsight, наречен SQL Server:Сравнителен анализ и базово определяне, ако имате нужда от помощ при настройката и улавянето на вашата базова линия.
Още по-добре, вземете най-съвременен инструмент като SQL Sentry Performance Advisor, който не само ще събира и съхранява историческа информация за профилиране и тенденции, и ще дава лесен достъп до всички подробности, споменати по-горе и още, но също така дава способността за сравняване на активността с вградени или дефинирани от потребителя базови линии, ефективно поддържане на индекси, без да си мръдне пръста, и предупреждаване или автоматизиране на отговорите въз основа на много стабилна архитектура за персонализирани условия. Следната екранна снимка изобразява историческия изглед на таблото за управление на Performance Advisor, с изчакване на диска в оранжево, I/O база данни в долния десен ъгъл и базови линии, сравняващи текущия и предишния период на всяка графика (щракнете, за да увеличите):
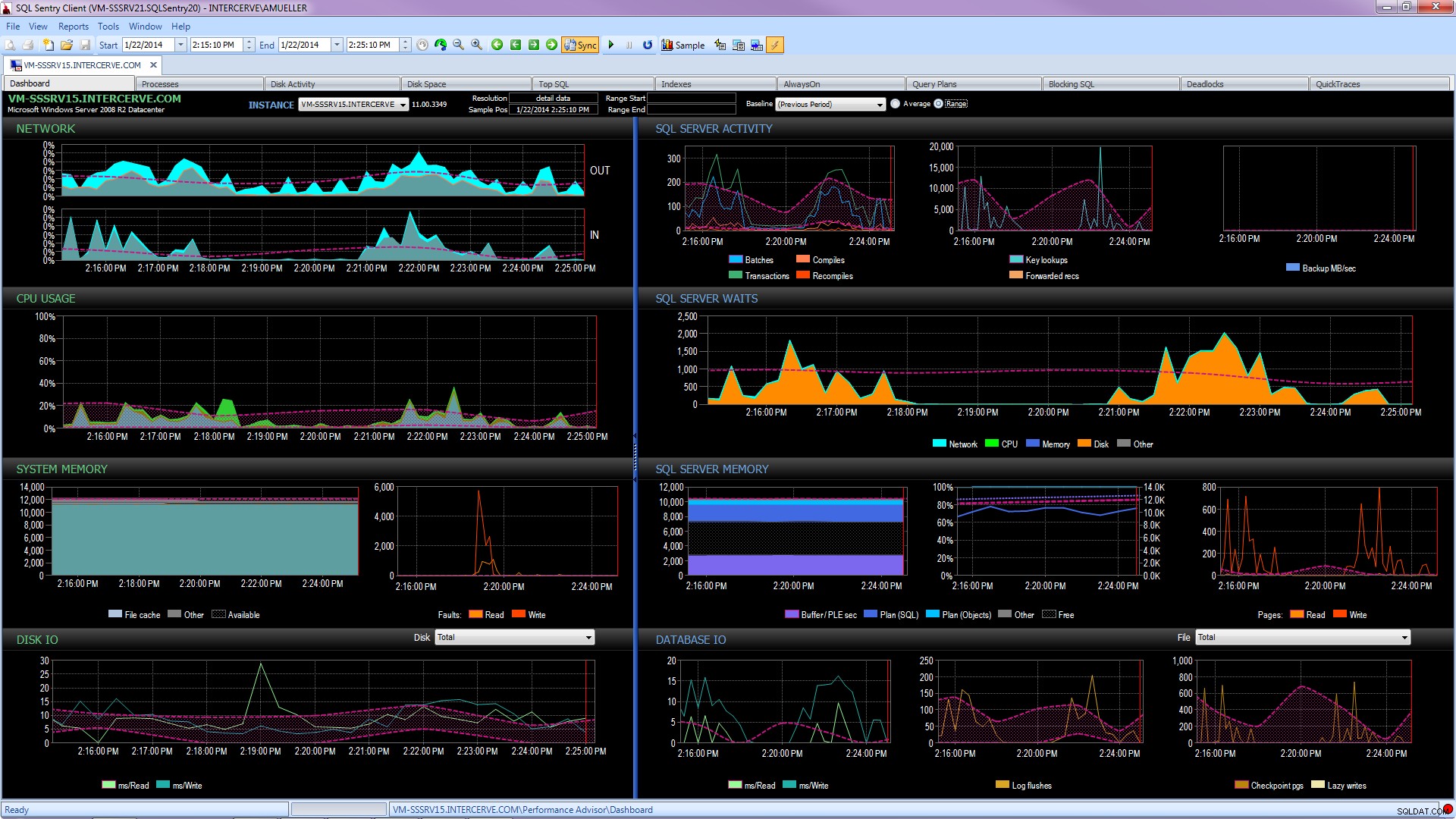
Инструментите за наблюдение на качеството не са безплатни, но предоставят много функции и поддръжка, които ви позволяват да се съсредоточите върху проблемите с производителността на вашите сървъри, вместо да се фокусирате върху заявки, работни места и сигнали, които може ви позволяват да се съсредоточите върху проблемите си с производителността – но само след като ги разберете правилно. Често има голяма стойност да не се изобретява колелото.