По-рано писах за ползите от използването на NOEXPAND съвети, дори в Enterprise Edition. Всички подробности са в свързаната статия, но за да обобщим накратко:
- SQL сървърът само автоматично създава статистика за индексиран изглед, когато
NOEXPANDизползва се подсказка за таблица. Пропускането на този намек може да доведе до предупреждения на план за изпълнение за липсващи статистически данни, които не могат да бъдат разрешени чрез ръчно създаване на статистика. - SQL Server ще използва само автоматично или ръчно създадени статистически данни за изгледа в изчисленията за оценка на мощността, когато заявката препраща директно към изгледа и
NOEXPANDсе използва подсказка. За всички дефиниции на изглед, с изключение на най-тривиалните, това означава, че качеството на оценките за мощността вероятно ще бъде по-ниско, когато този намек не се използва, което често води до по-малко оптимални планове за изпълнение. - Липсата или невъзможността за използване на статистически данни за изгледи може да накара оптимизатора да отгатне оценките за мощност, дори когато са налични статистически данни от базовата таблица. Това може да се случи, когато част от плана на заявката се заменя с индексиран препратка за изглед от функцията за автоматично съвпадение на изглед, но статистическите данни за изгледите не са налични, както е описано по-горе.
Има и друга последица от неизползването на NOEXPAND намек, който споменах мимоходом преди няколко години в моята статия, Ограничения на оптимизатора с филтрирани индекси:
NOEXPANDсъвети са необходими дори в Enterprise Edition, за да се гарантира, че гаранцията за уникалност, предоставена от индексите на изгледа, се използва от оптимизатора.
Тази статия разглежда това твърдение и неговите последици по-подробно.
Настройка на демонстрация
Следният скрипт създава проста таблица и индексиран изглед:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Това създава една таблица с колона и неограничен изглед на същата таблица с уникален клъстериран индекс. Това не е предназначено да бъде реалистичен случай на използване на индексиран изглед; но това ще помогне да се илюстрират ключовите моменти с минимум разсейващи фактори. Важният момент е, че основната таблица тук изобщо няма индекси (дори и клъстериран индекс), но изгледът го има и този индекс е уникален.
Примерната заявка
Помислете за следната проста заявка към основната таблица:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Планът за изпълнение, който ще видите за тази заявка, зависи от използваното издание на SQL Server. Ако не е Enterprise Edition (или еквивалент), ще видите план като този:

Оптимизаторът на заявки на SQL Server е избрал да сканира основната таблица и да приложи посочената отличителност с помощта на оператор Distinct Sort. Тази форма на план е напълно очаквана, тъй като автоматичното съвпадение на индексирани изгледи не е налично извън Enterprise Edition. Ще спра да казвам „Enterprise Edition или еквивалент“ от този момент нататък, но моля, продължете да заключите, че имам предвид всяко издание, което поддържа автоматично съвпадение на изгледи, когато казвам „Enterprise Edition“ отсега нататък.
Съветът за РАЗГРАЖДАНЕ НА ИЗГЛЕДИ
Това е малко настрана, но за да получим същия план в Enterprise Edition, трябва да използваме EXPAND VIEWS съвет за заявка:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Може да изглежда малко странно да използвате този намек, когато няма препратки към изглед в заявката, но така работи. EXPAND VIEWS hint ефективно указва, че съвпадението на индексиран изглед трябва да бъде деактивирано, докато компилирате и оптимизирате заявката. За да бъде ясно:без този намек, Enterprise Edition може иначе да съпостави (части от) заявката с един или повече индексирани изгледи.
С активирано автоматично съвпадение на изглед
Без EXPAND VIEWS намек, компилирането на същата заявка в изданието за разработчици (например) произвежда различен план:
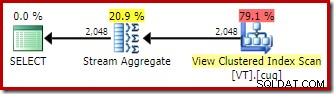
Прилагането на индексирано съвпадение на изглед означава, че планът за изпълнение включва сканиране на клъстерния индекс на изглед вместо сканиране на основна таблица.
Същият план се създава в този случай, ако заявката препраща директно към изгледа (вместо към основната таблица):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; Във всички издания справочникът за изглед се разширява, преди да започне оптимизацията на заявката. В издания, еквивалентни на Enterprise, разширеният формуляр може да бъде съпоставен обратно с изгледа по-късно. Това е ключова концепция, която трябва да разберете, когато мислите как компилаторът на заявки и оптимизаторът използват индексирани изгледи в SQL Server.
Агрегатът на потока
Най-интересната разлика между двата плана, които видяхме досега, е Stream Aggregate в плана за съвпадение на изглед. Ако погледнете прогнозните разходи на операторите Table Scan и View Scan, ще видите, че те са абсолютно еднакви. Оптимизаторът не реши да използва индексирания изглед, защото направи достъпа до данните по-евтин. По-скоро сканирането на индекса на изглед позволява DISTINCT изискване да бъде приложено като Stream Aggregate, а не като Hash Aggregate или Distinct Sort (както в първия план).
Агрегатът на потока изисква въвеждане, подредено по колоната(ите) за групиране. В този случай различието е еквивалентно на групиране по една колона, а уникалният клъстериран индекс на изгледа осигурява необходимата гаранция за подреждане. Моделът на разходите на оптимизатора идентифицира Stream Aggregate като по-евтина опция от Distinct Sort или Hash Aggregate за тази заявка. Това е основата за избора на оптимизатора за достъп до индексирания изглед, когато е налично автоматично съвпадение на изглед.
С всичко казано и разбрано, Stream Aggregate все още е неочакван:като се има предвид гаранцията за уникалност, предоставена от индекса на изглед, изобщо не е необходимо да се извършва тази операция за групиране. Уникалното клъстерираният индекс вече гарантира, че колоната не съдържа дубликати.
Това, накратко, е проблемът. Когато се използва автоматично съвпадение на изгледи, оптимизаторът разпознава гаранцията за подреждане, предоставена от индекса на изгледа, но не и гаранцията за уникалност.
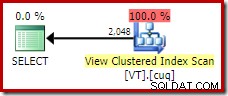
Използване на подсказка NOEXPAND
За да получим идеалния план за изпълнение на тази заявка, трябва да се свържем директно с изгледа и да използваме NOEXPAND съвет за таблица:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Това ни дава плана, който опитен човек в базата данни би очаквал; такъв, който правилно разпознава, че отделната операция е излишна и може да бъде премахната:
Втори пример
Ако не се възползвате от гаранцията за уникалност, предоставена от индекса на преглед, може да има други ефекти върху крайния план за изпълнение. Помислете сега за самостоятелно присъединяване на индексирания изглед (отново, само за да илюстрирате концепция – това не е предназначено да бъде реалистична заявка):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Използвайки изданието за програмисти, избраният план за изпълнение изобщо няма достъп до индексирания изглед и включва хеш присъединяване (понякога индикация, че липсва полезен индекс):
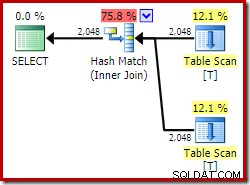
Сега нека опитаме точно същата заявка, но с NOEXPAND намек за всяка препратка към изглед:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Планът за изпълнение вече включва два индексирани достъпа за изглед и обединяване за сливане:
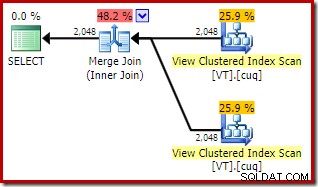
Този нов план има много по-ниска прогнозна цена от плана за хеш присъединяване, така че защо оптимизаторът не е избрал тази опция преди? Можем да разберем защо, като добавим намек за присъединяване за сливане към оригиналната заявка:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Това придава подобен вид план, който избира достъп до изгледа, въпреки че NOEXPAND не е посочено:
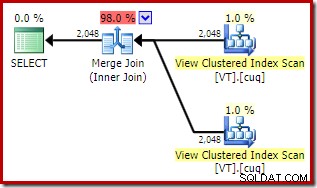
Общата прогнозна цена на този план е по-висока от двата предишни примера. Присъединяването към сливане в този план също представлява по-висок дял от общите прогнозни разходи, отколкото преди (98% срещу 48,2%).
Причината за това може да се види, като се разгледат свойствата на обединението за сливане. В NOEXPAND план, това беше присъединяване един към много. В плана непосредствено по-горе това е свързване много към много. Моделът на разходите на оптимизатора присвоява по-висока цена на много към много обединявания, тъй като е необходима работна таблица tempdb за обработка на всякакви дубликати.
Заключения
Гаранциите, предоставени от уникален индекс, могат да бъдат мощен инструмент за оптимизиране, така че е жалко, че автоматичното съвпадение на индекси в момента не може да се възползва от него. Потенциалните ползи надхвърлят елиминирането на ненужни агрегации или разрешаването на обединяване един към много, както се вижда в предходните прости примери. Като цяло може да е трудно да се забележи, че планът за изпълнение не е оптимален, защото оптимизаторът е пропуснал да се възползва от гаранцията за уникалност.
Това ограничение на оптимизатора не се прилага само за уникалния клъстериран индекс, който изгледът трябва да има, за да бъде материализиран. В по-сложни сценарии в изгледа могат да присъстват и допълнителни неклъстерирани индекси; може би за отразяване на връзки между таблици, които са трудни за налагане или представяне по друг начин. Ако тези неклъстерирани индекси са дефинирани като уникални, оптимизаторът ще пренебрегне и тези гаранции, ако се използва автоматично съвпадение на индекси.
Като добавим това към ограниченията около създаването и използването на статистическа информация, изглежда, че разчитането на автоматично съвпадение на изглед може да доведе до по-лоши планове за изпълнение. Най-сигурната опция вероятно е да се препратят изрично индексирани изгледи и да се използва NOEXPAND подсказвайте всеки път – поне докато тези проблеми не бъдат отстранени в продукта.
Смекчаващи фактори
Трябва да подчертая, че проблемът, описан в тази статия, се отнася само за гаранцията за уникалност, предоставена от уникален индекс на изглед. Ако оптимизаторът може да получи необходимата информация за уникалност по друг начин , шансовете са добри проблеми с оптимизацията да бъдат избегнати.
Например, може да има подходящ уникален индекс на базова таблица, посочена от изгледа. Или, в случай на изглед, който съдържа агрегиране, оптимизаторът вече може да изведе полезна гаранция за уникалност от GROUP BY на изгледа клауза. Обичайната практика за добавяне на клъстериран индекс на изглед към ключовете за групиране не добавя допълнителна информация за уникалност в този случай.
Независимо от това, има моменти, когато този „надзор върху уникалността“ може да означава, че ще получите по-качествени планове за изпълнение, като използвате изрична препратка към изглед и NOEXPAND съвети, дори в Enterprise Edition.