Миналия месец публикувах предизвикателство за създаване на ефективен генератор на серии от числа. Отговорите бяха зашеметяващи. Имаше много брилянтни идеи и предложения, с много приложения, далеч отвъд това конкретно предизвикателство. Това ме накара да осъзная колко е страхотно да си част от общност и че невероятни неща могат да бъдат постигнати, когато група умни хора обединят усилията си. Благодаря на Алън Бърщайн, Джо Оббиш, Адам Мачаник, Кристофър Форд, Джеф Модън, Чарли, НоамГр, Камил Косно, Дейв Мейсън и Джон Номер2 за споделянето на вашите идеи и коментари.
Първоначално мислех да напиша само една статия, за да обобщя идеите, които хората изпратиха, но бяха твърде много. Така че ще разделя репортажа на няколко статии. Този месец ще се съсредоточа основно върху предложените от Чарли и Алън Бърщайн подобрения на двете оригинални решения, които публикувах миналия месец под формата на вградените TVF, наречени dbo.GetNumsItzikBatch и dbo.GetNumsItzik. Ще наименувам подобрените версии съответно dbo.GetNumsAlanCharlieItzikBatch и dbo.GetNumsAlanCharlieItzik.
Това е толкова вълнуващо!
Оригиналните решения на Itzik
Като бързо напомняне, функциите, които разгледах миналия месец, използват базов CTE, който дефинира конструктор на стойност на таблица с 16 реда. Функциите използват серия от каскадни CTE, всяка от които прилага продукт (кръстосано свързване) на два екземпляра на своя предходен CTE. По този начин, с пет CTE извън основния, можете да получите набор от до 4 294 967 296 реда. CTE, наречен Nums, използва функцията ROW_NUMBER, за да произведе серия от числа, започващи с 1. И накрая, външната заявка изчислява числата в искания диапазон между входовете @low и @high.
Функцията dbo.GetNumsItzikBatch използва фиктивно присъединяване към таблица с индекс на columnstore, за да получи пакетна обработка. Ето кода за създаване на фиктивната таблица:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
А ето и кода, дефиниращ функцията dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Използвах следния код, за да тествам функцията с активиран „Изхвърли резултати след изпълнение“ в SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за производителността, които получих за това изпълнение:
CPU time = 16985 ms, elapsed time = 18348 ms.
Функцията dbo.GetNumsItzik е подобна, само че няма фиктивно присъединяване и обикновено получава обработка в режим на ред в целия план. Ето дефиницията на функцията:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ето кода, който използвах за тестване на функцията:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за производителността, които получих за това изпълнение:
CPU time = 19969 ms, elapsed time = 21229 ms.
Подобренията на Алън Бърщайн и Чарли
Алън и Чарли предложиха няколко подобрения на моите функции, някои с умерени последици за производителността, а други с по-драматични. Ще започна с констатациите на Чарли по отношение на компилацията и постоянното сгъване. След това ще разгледам предложенията на Алън, включително базирани на 1 последователности срещу @low-based (също споделени от Чарли и Джеф Модън), избягване на ненужно сортиране и изчисляване на диапазон от числа в обратен ред.
Констатации за времето за компилиране
Както Чарли отбеляза, генератор на числови серии често се използва за генериране на серии с много малък брой редове. В тези случаи времето за компилиране на кода може да стане съществена част от общото време за обработка на заявката. Това е особено важно при използване на iTVFs, тъй като за разлика от съхранените процедури, не се оптимизира параметризираният код на заявка, а кодът на заявката след вграждането на параметър. С други думи, параметрите се заменят с входните стойности преди оптимизацията и кодът с константите се оптимизира. Този процес може да има както отрицателни, така и положителни последици. Едно от отрицателните последици е, че получавате повече компилации, тъй като функцията се извиква с различни входни стойности. Поради тази причина определено трябва да се вземе предвид времето за компилиране — особено когато функцията се използва много често с малки диапазони.
Ето времето за компилация, което Чарли намери за различните основни CTE кардинальности:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Любопитно е да видим, че сред тях 16 е оптималното и че има много драматичен скок, когато се качите на следващото ниво, което е 256. Припомнете си, че функциите dbo.GetNumsItzikBacth и dbo.GetNumsItzik използват базова CTE мощност от 16 .
Постоянно сгъване
Постоянното сгъване често е положително следствие, че при правилните условия може да бъде активирано благодарение на процеса на вграждане на параметри, който изпитва iTVF. Например, да предположим, че вашата функция има израз @x + 1, където @x е входен параметър на функцията. Извиквате функцията с @x =5 като вход. След това вграденият израз става 5 + 1 и ако отговаря на условията за постоянно сгъване (повече за това скоро), тогава става 6. Ако този израз е част от по-сложен израз, включващ колони, и се прилага към много милиони редове, това може води до непренебрежимо малки спестявания в циклите на процесора.
Трудната част е, че SQL Server е много придирчив относно това какво да се сгъва постоянно и какво да не се сгъва постоянно. Например SQL Server не постоянен фолд col1 + 5 + 1, нито ще фолдне 5 + col1 + 1. Но ще фолдне 5 + 1 + col1 до 6 + col1. Знам. Така например, ако вашата функция върне SELECT @x + col1 + 1 КАТО mycol1 ОТ dbo.T1, можете да активирате постоянното сгъване със следната малка промяна:SELECT @x + 1 + col1 КАТО mycol1 ОТ dbo.T1. Не ми вярвате? Разгледайте плановете за следните три заявки в базата данни PerformanceV5 (или подобни заявки с вашите данни) и се убедете сами:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Получих следните три израза в операторите Compute Scalar за тези три заявки, съответно:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Вижте къде отивам с това? В моите функции използвах следния израз, за да дефинирам резултантната колона n:
@low + rownum - 1 AS n
Чарли осъзна, че със следната малка промяна той може да позволи постоянно сгъване:
@low - 1 + rownum AS n
Например, планът за по-ранната заявка, който предоставих срещу dbo.GetNumsItzik, с @low =1, първоначално имаше следния израз, дефиниран от оператора Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
След прилагане на горната незначителна промяна, изразът в плана става:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Това е брилянтно!
Що се отнася до последиците за производителността, припомнете си, че статистическите данни за производителността, които получих за заявката срещу dbo.GetNumsItzikBatch преди промяната, бяха следните:
CPU time = 16985 ms, elapsed time = 18348 ms.
Ето числата, които получих след промяната:
CPU time = 16375 ms, elapsed time = 17932 ms.
Ето числата, които получих за първоначалната заявка срещу dbo.GetNumsItzik:
CPU time = 19969 ms, elapsed time = 21229 ms.
А ето и числата след промяната:
CPU time = 19266 ms, elapsed time = 20588 ms.
Производителността се подобри само с няколко процента. Но чакайте, има още! Ако трябва да обработите поръчаните данни, последиците от производителността могат да бъдат много по-драматични, както ще стигна по-късно в раздела за поръчката.
Последователност на базата на 1 спрямо @low-based и противоположни номера на редове
Алън, Чарли и Джеф отбелязаха, че в по-голямата част от случаите в реалния живот, когато имате нужда от диапазон от числа, трябва да започнете с 1 или понякога 0. Много по-рядко е да имате нужда от различна отправна точка. Така че би било по-разумно функцията винаги да връща диапазон, който започва с, да речем, 1, и когато имате нужда от различна начална точка, прилагайте всякакви изчисления външно в заявката спрямо функцията.
Алън всъщност излезе с елегантна идея вграденият TVF да връща както колона, която започва с 1 (просто директен резултат от функцията ROW_NUMBER), с псевдоним rn, така и колона, която започва с @low псевдоним като n. Тъй като функцията се вгражда, когато външната заявка взаимодейства само с колоната rn, колоната n дори не се оценява и вие получавате полза от производителността. Когато имате нужда от последователността да започне с @low, вие взаимодействате с колоната n и плащате приложимите допълнителни разходи, така че няма нужда да добавяте никакви изрични външни изчисления. Алън дори предложи да се добави колона, наречена op, която изчислява числата в обратен ред и да взаимодейства с нея само когато има нужда от такава последователност. Колоната op се базира на изчислението:@high + 1 – rownum. Тази колона има значение, когато трябва да обработите редовете в низходящ ред, както демонстрирам по-късно в раздела за подреждане.
И така, нека приложим подобренията на Чарли и Алън към моите функции.
За версията на пакетния режим се уверете, че първо сте създали фиктивната таблица с индекса на columnstore, ако все още не е налице:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
След това използвайте следната дефиниция за функцията dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ето пример за използване на функцията:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Този код генерира следния изход:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
След това тествайте производителността на функцията със 100 милиона реда, като първо върнете колоната n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за производителността, които получих за това изпълнение:
CPU time = 16375 ms, elapsed time = 17932 ms.
Както можете да видите, има малко подобрение в сравнение с dbo.GetNumsItzikBatch както в процесора, така и в изминалото време благодарение на постоянното сгъване, което се случва тук.
Тествайте функцията, като само този път връща колоната rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за производителността, които получих за това изпълнение:
CPU time = 15890 ms, elapsed time = 18561 ms.
Времето на процесора е допълнително намалено, въпреки че изглежда, че изминалото време се е увеличило малко при това изпълнение в сравнение с това при запитване на колона n.
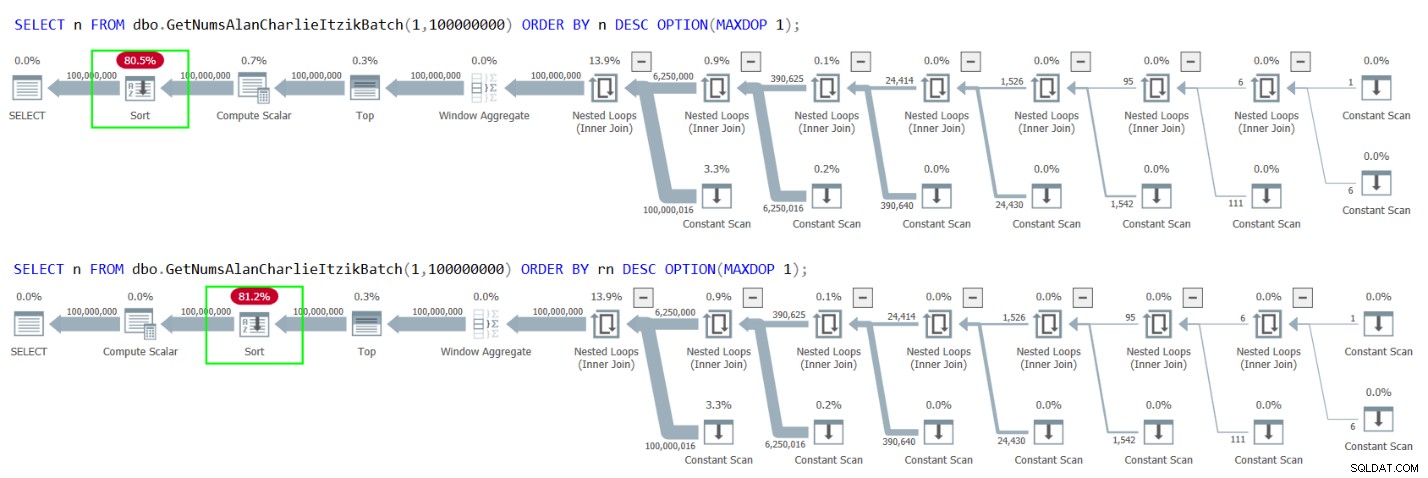
Фигура 1 показва плановете и за двете заявки.
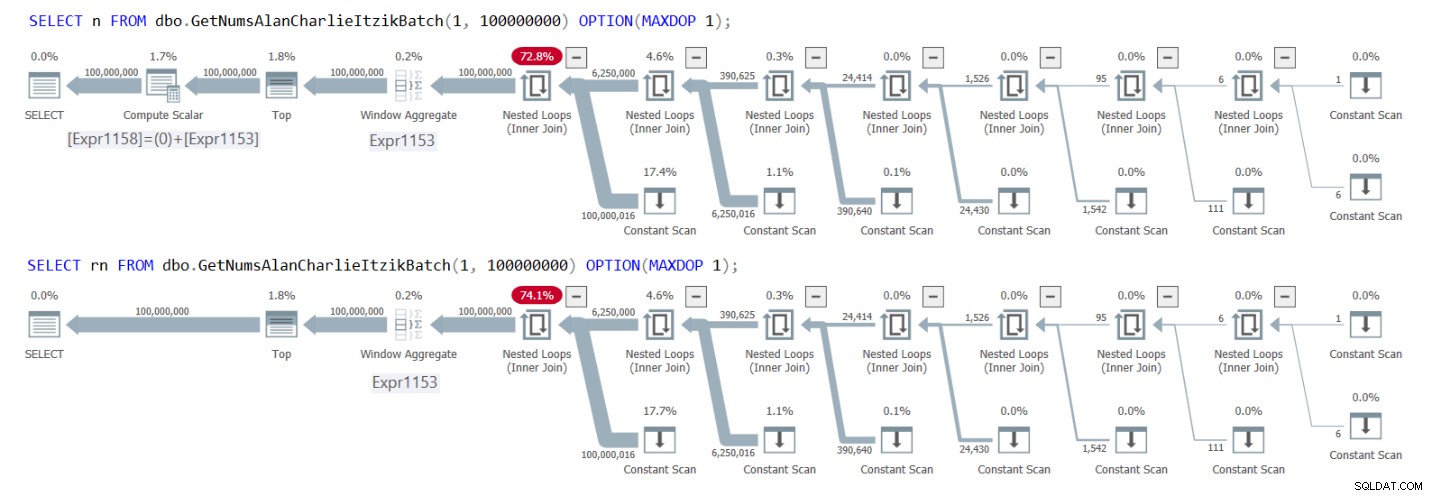 Фигура 1:Планове за GetNumsAlanCharlieItzikBatch, връщащ n срещу rn
Фигура 1:Планове за GetNumsAlanCharlieItzikBatch, връщащ n срещу rn
Можете ясно да видите в плановете, че когато взаимодействате с колоната rn, няма нужда от допълнителен оператор Compute Scalar. Също така забележете в първия план резултата от постоянната дейност по сгъване, която описах по-рано, където @low – 1 + rownum беше вграден в 1 – 1 + rownum и след това сгънат в 0 + rownum.
Ето дефиницията на версията в режим на ред на функцията, наречена dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Използвайте следния код, за да тествате функцията, като първо потърсите колона n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Ето статистическите данни за ефективността, които получих:
CPU time = 19047 ms, elapsed time = 20121 ms.
Както можете да видите, това е малко по-бързо от dbo.GetNumsItzik.
След това потърсете колоната rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Числата на производителността допълнително се подобряват както на централния процесор, така и на изминалото време:
CPU time = 17656 ms, elapsed time = 18990 ms.
Съображения за поръчка
Гореспоменатите подобрения със сигурност са интересни, а въздействието върху производителността е незначително, но не много значително. Много по-драматично и дълбоко въздействие върху производителността може да се наблюдава, когато трябва да обработите данните, подредени от колоната с числа. Това може да бъде толкова просто, колкото необходимостта от връщане на подредените редове, но е също толкова уместно за всяка нужда от обработка, базирана на поръчка, например оператор Stream Aggregate за групиране и агрегиране, алгоритъм на Merge Join за присъединяване и така нататък.
Когато отправя заявка към dbo.GetNumsItzikBatch или dbo.GetNumsItzik и подрежда по n, оптимизаторът не осъзнава, че основният израз за подреждане @low + rownum – 1 е запазващ реда по отношение на rownum. Импликацията е малко подобна на тази на израза за филтриране без SARG, само с израз за подреждане това води до изричен оператор за сортиране в плана. Допълнителното сортиране влияе на времето за отговор. Освен това засяга мащабирането, което обикновено става n log n вместо n.
За да демонстрирате това, заявете dbo.GetNumsItzikBatch, като поискате колоната n, подредена по n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Получих следните статистически данни за ефективността:
CPU time = 34125 ms, elapsed time = 39656 ms.
Времето за изпълнение се удвоява повече от два пъти в сравнение с теста без клаузата ORDER BY.
Тествайте функцията dbo.GetNumsItzik по подобен начин:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Получих следните числа за този тест:
CPU time = 52391 ms, elapsed time = 55175 ms.
Също така тук времето за изпълнение се удвоява повече от два пъти в сравнение с теста без клаузата ORDER BY.
Фигура 2 показва плановете и за двете заявки.
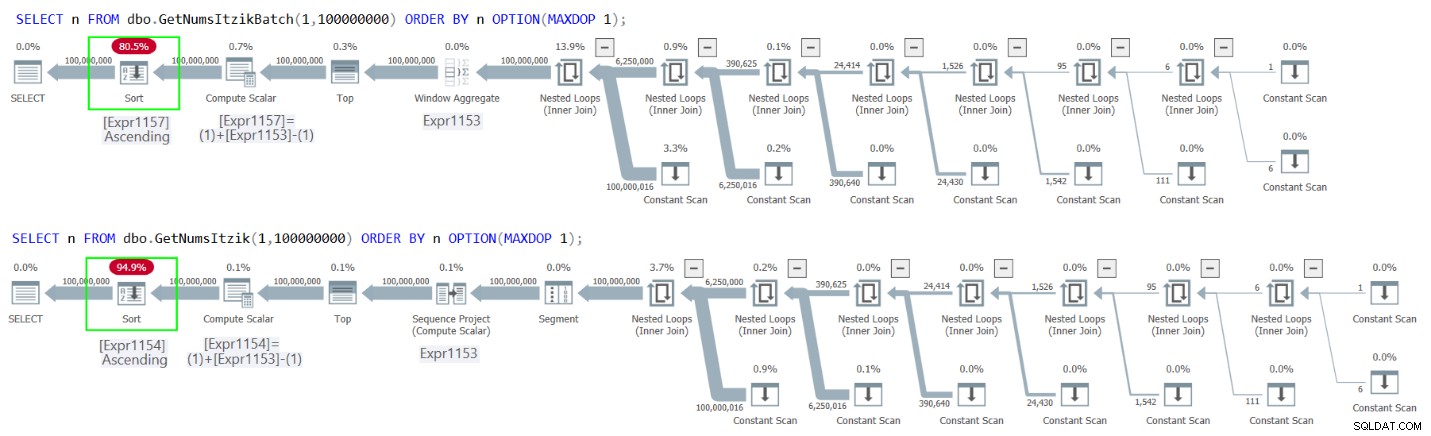 Фигура 2:Планове за GetNumsItzikBatch и GetNumsItzik подреждане по n
Фигура 2:Планове за GetNumsItzikBatch и GetNumsItzik подреждане по n
И в двата случая можете да видите изричния оператор за сортиране в плановете.
Когато отправяте заявка към dbo.GetNumsAlanCharlieItzikBatch или dbo.GetNumsAlanCharlieItzik и поръчвате по rn, оптимизаторът не трябва да добавя оператор за сортиране към плана. Така че можете да върнете n, но да подредите по rn и по този начин да избегнете сортиране. Това, което е малко шокиращо обаче — и го имам предвид в добър начин — е, че ревизираната версия на n, която изпитва постоянно сгъване, запазва реда! За оптимизатора е лесно да осъзнае, че 0 + rownum е израз, запазващ реда по отношение на rownum, и по този начин избягва сортирането.
Опитай. Заявка dbo.GetNumsAlanCharlieItzikBatch, връщане на n и подреждане по n или rn, както следва:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Получих следните показатели за ефективност:
CPU time = 16500 ms, elapsed time = 17684 ms.
Това, разбира се, благодарение на факта, че нямаше нужда от оператор за сортиране в плана.
Изпълнете подобен тест срещу dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Получих следните номера:
CPU time = 19546 ms, elapsed time = 20803 ms.
Фигура 3 показва плановете и за двете заявки:
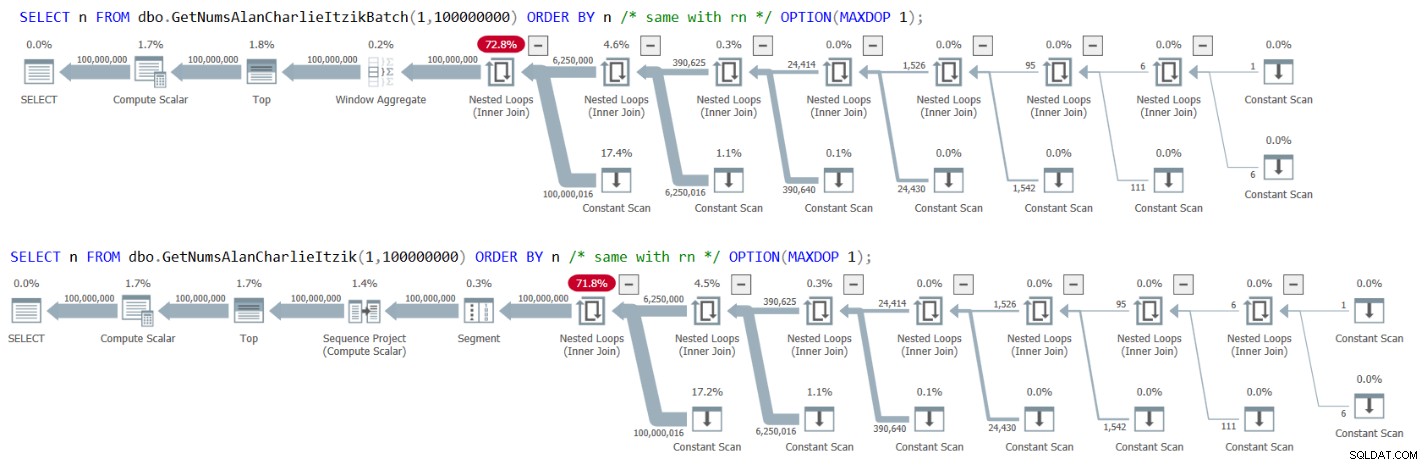
Фигура 3:Планове за GetNumsAlanCharlieItzikBatch и GetNumsAlanChar по поръчка по поръчка
Обърнете внимание, че в плановете няма оператор за сортиране.
Кара те да искаш да пееш...
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Благодаря ти Чарли!
Но какво ще стане, ако трябва да върнете или обработите числата в низходящ ред? Очевидният опит е да се използва ORDER BY n DESC или ORDER BY rn DESC, както следва:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
За съжаление обаче и двата случая водят до изрично сортиране в плановете, както е показано на фигура 4.
 Фигура 4:Планове за GetNumsAlanCharlieItzikBatch подреждане по n или rn низходящо подреждане
Фигура 4:Планове за GetNumsAlanCharlieItzikBatch подреждане по n или rn низходящо подреждане
Това е мястото, където хитрият трик на Алън с колонната операция се превръща в спасител. Върнете колоната op, докато подреждате по n или rn, така:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Планът за тази заявка е показан на Фигура 5.
 Фигура 5:План за GetNumsAlanCharlieItzikBatch връщане на операция и подреждане по n или rn ascend em>
Фигура 5:План за GetNumsAlanCharlieItzikBatch връщане на операция и подреждане по n или rn ascend em>
Получавате обратно данните, подредени по n надолу и няма нужда от сортиране в плана.
Благодаря ти, Алън!
Резюме на ефективността
И така, какво научихме от всичко това?
Времето за компилация може да бъде фактор, особено при често използване на функцията с малки диапазони. В логаритмична скала с основа 2 сладкото 16 изглежда е хубаво магическо число.
Разберете особеностите на постоянното сгъване и ги използвайте в своя полза. Когато iTVF има изрази, които включват параметри, константи и колони, поставете параметрите и константите в водещата част на израза. Това ще увеличи вероятността за сгъване, ще намали разходите на процесора и ще увеличи вероятността за запазване на поръчката.
Добре е да имате няколко колони, които се използват за различни цели в iTVF, и да заявявате съответните във всеки случай, без да се притеснявате да плащате за тези, които не са посочени.
Когато имате нужда от последователност от числа, върната в обратен ред, използвайте оригиналната колона n или rn в клаузата ORDER BY с възходящ ред и върнете колоната op, която изчислява числата в обратен ред.
Фигура 6 обобщава числата за ефективност, които получих в различните тестове.
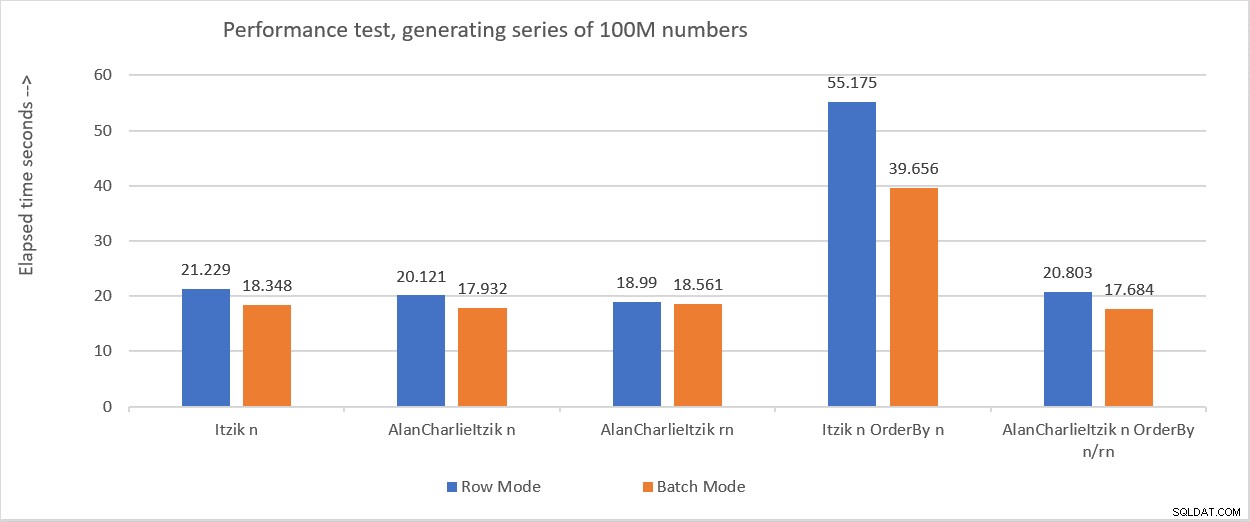 Фигура 6:Резюме на ефективността
Фигура 6:Резюме на ефективността
Следващия месец ще продължа да проучвам допълнителни идеи, прозрения и решения за предизвикателството с генератора на числа.