Преди почти година до този ден публикувах моето решение за пагинация в SQL Server, което включваше използване на CTE за намиране само на ключовите стойности за въпросния набор от редове и след това присъединяване обратно от CTE към таблицата източник за извличане другите колони само за тази "страница" от редове. Това се оказа най-полезно, когато имаше тесен индекс, който поддържаше подреждането, поискано от потребителя, или когато подреждането се основаваше на ключа за клъстериране, но дори се представяше малко по-добре без индекс, който да поддържа необходимото сортиране.
Оттогава се чудех дали индексите на ColumnStore (както клъстерни, така и неклъстерни) могат да помогнат на някой от тези сценарии. TL;DR :Въз основа на този експеримент в изолация, отговорът на заглавието на тази публикация е категорично НЕ . Ако не искате да видите настройката на теста, кода, плановете за изпълнение или графиките, не се колебайте да прескочите към моето резюме, като имате предвид, че анализът ми се основава на много специфичен случай на употреба.
Настройка
На нова виртуална машина с инсталиран SQL Server 2016 CTP 3.2 (13.0.900.73), преминах през приблизително същата настройка както преди, само че този път с три таблици. Първо, традиционна таблица с тесен ключ за клъстериране и множество поддържащи индекси:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
След това таблица с клъстериран индекс на ColumnStore:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
И накрая, таблица с неклъстериран индекс на ColumnStore, покриващ всички колони:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Забележете, че и за двете таблици с индекси на ColumnStore пропуснах индекса, който би поддържал по-бързо търсене при сортиране „Телефонна книга“ (фамилия, собствено име).
Тестови данни
След това попълних първата таблица с 1 000 000 произволни реда, въз основа на скрипт, който използвах повторно от предишни публикации:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; След това използвах тази таблица, за да попълня другите две с точно същите данни и възстанових всички индекси:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Общият размер на всяка таблица:
| Таблица | Запазено | Данни | Индекс |
|---|---|---|---|
| Клиенти | 463 200 KB | 154 344 KB | 308 576 KB |
| Клиенти_CCI | 117 280 KB | 30 288 KB | 86 536 KB |
| Клиенти_NCCI | 349 480 KB | 154 344 KB | 194 976 KB |
И броят на редовете/броят на страниците на съответните индекси (уникалният индекс на електронната поща беше повече за мен, за да гледам собствения си скрипт за генериране на данни, отколкото всичко друго):
| Таблица | Индекс | Редове | Страници |
|---|---|---|---|
| Клиенти | PK_Customers | 1 000 000 | 19 377 |
| Клиенти | Клиенти на телефонния указател | 1 000 000 | 17 209 |
| Клиенти | Активни_клиенти | 808 012 | 13 977 |
| Клиенти_CCI | PK_CustomersCCI | 1 000 000 | 2737 |
| Клиенти_CCI | Клиенти_CCI | 1 000 000 | 3826 |
| Клиенти_NCCI | PK_CustomersNCCI | 1 000 000 | 19 377 |
| Клиенти_NCCI | Клиенти_NCCI | 1 000 000 | 16 971 |
Процедури
След това, за да видя дали индексите на ColumnStore ще нахлуят и ще направят някой от сценариите по-добър, изпълних същия набор от заявки, както преди, но сега срещу всичките три таблици. Станах поне малко по-умен и направих две съхранени процедури с динамичен SQL, за да приема източника на таблицата и реда на сортиране. (Добре съм наясно с SQL инжектирането; това не бих направил в производството, ако тези низове идват от краен потребител, така че, моля, не го приемайте като препоръка да го правите. Доверявам се достатъчно в моя затворена среда, че това не е проблем за тези тестове.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
След това приготвих малко по-динамичен SQL, за да генерирам всички комбинации от повиквания, които ще трябва да направя, за да извикам както старите, така и новите съхранени процедури, в трите желани реда за сортиране и при различни номера на страници (за да симулирам нужда от страница близо до началото, средата и края на реда за сортиране). За да мога да копирам PRINT изведете и го поставете в SQL Sentry Plan Explorer, за да получите показатели по време на изпълнение, изпълних тази партида два пъти, веднъж с procedures CTE с помощта на P_Old , а след това отново с помощта на P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Това доведе до изход като този (36 извиквания общо за стария метод (P_Old ) и 36 извиквания за новия метод (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Знам, всичко това е много тромаво; скоро ще стигнем до финала, обещавам.
Резултати
Взех тези два комплекта от 36 изявления и започнах две нови сесии в Plan Explorer, като стартирах всеки набор няколко пъти, за да гарантирам, че получаваме данни от топъл кеш и вземаме средни стойности (мога да сравня и студен и топъл кеш, но мисля, че има достатъчно променливи тук).
Мога да ви кажа веднага няколко прости факта, без дори да ви показвам подкрепящи графики или планове:
- В никакъв сценарий „старият“ метод не надмина новия метод на CTE Повиших в предишната си публикация, без значение какъв тип индекси присъстваха. Така че това улеснява практически игнорирането на половината от резултатите, поне по отношение на продължителността (което е единственият показател, за който крайните потребители се интересуват най-много).
- Нито един индекс на ColumnStore не се представи добре при прелистване към края на резултата – дадоха ползи само в началото и то само в няколко случая.
- При сортиране по първичен ключ (клъстерирани или не), наличието на индекси на ColumnStore не помогна – отново по отношение на продължителност.
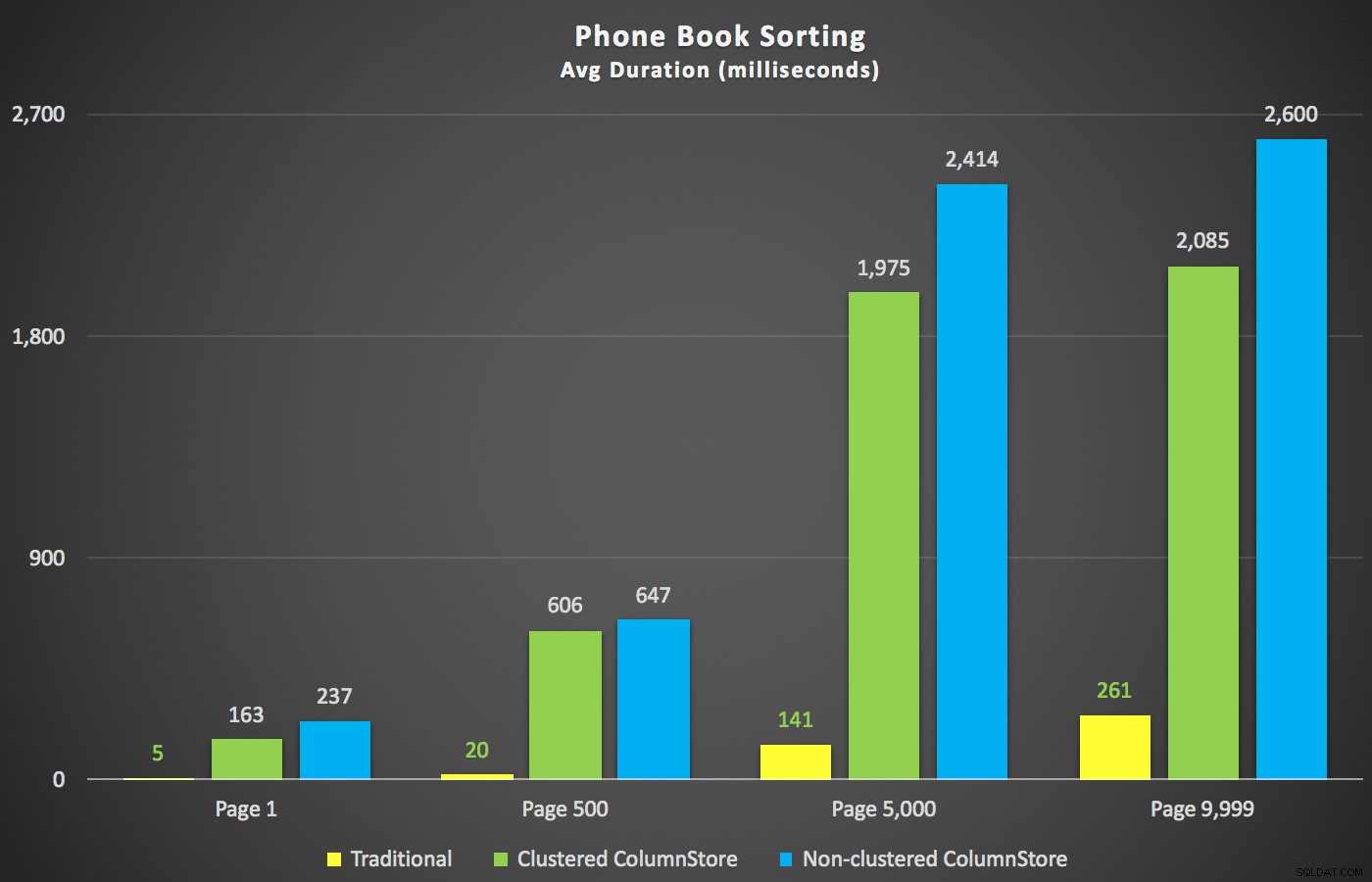
Като изключим тези обобщения, нека да разгледаме няколко напречни сечения на данните за продължителността. Първо, резултатите от заявката, подредени по низходящо име, след това по имейл, без надежда за използване на съществуващ индекс за сортиране. Както можете да видите в диаграмата, производителността беше непостоянна – при по-ниски номера на страници, неклъстерираният ColumnStore се справи най-добре; при по-голям брой страници традиционният индекс винаги печелеше:
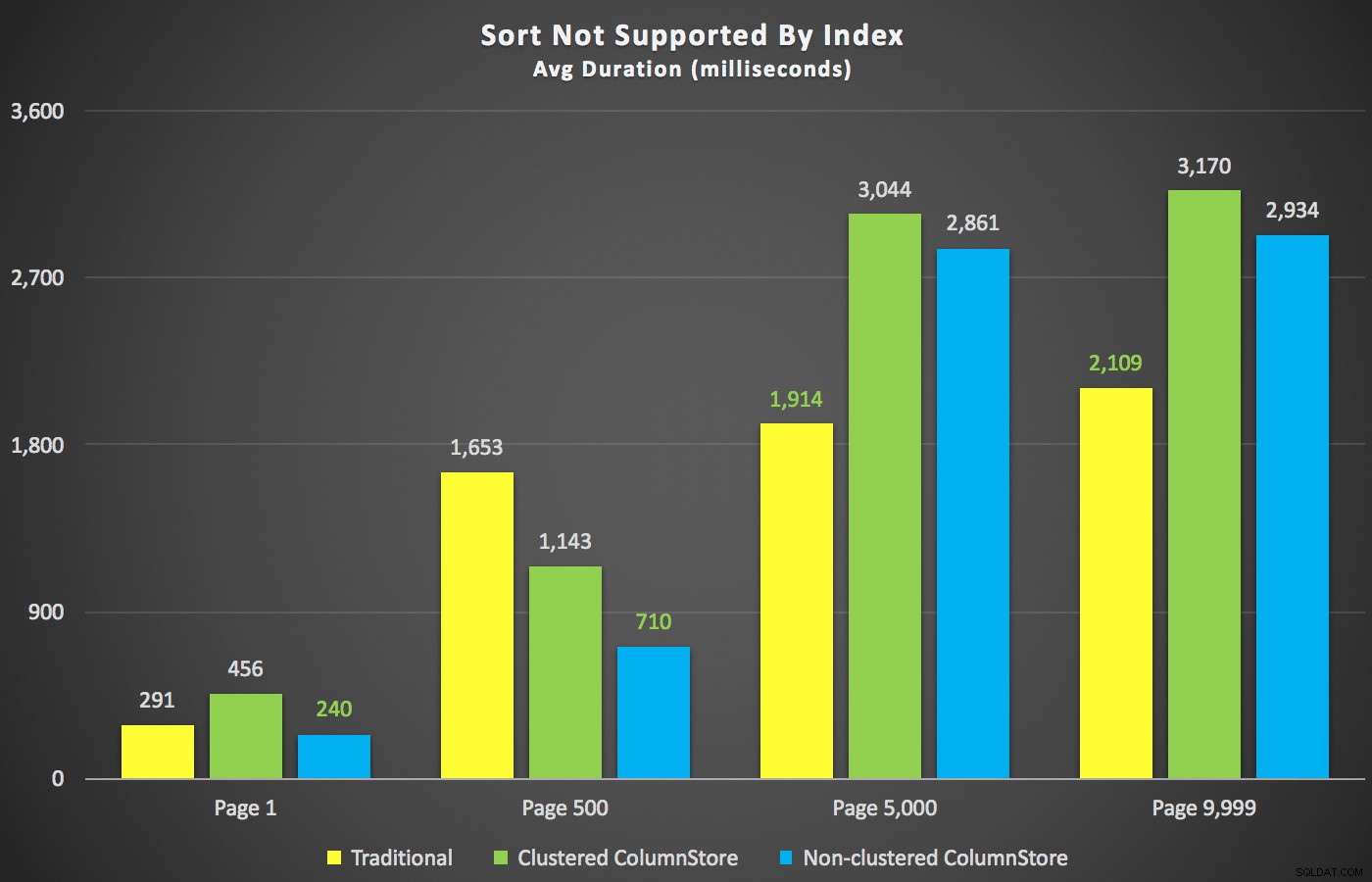 Продължителност (милисекунди) за различни номера на страници и различни типове индекси
Продължителност (милисекунди) за различни номера на страници и различни типове индекси
И след това трите плана, представляващи трите различни типа индекси (с добавена скала на сивото от Photoshop, за да се подчертаят основните разлики между плановете):
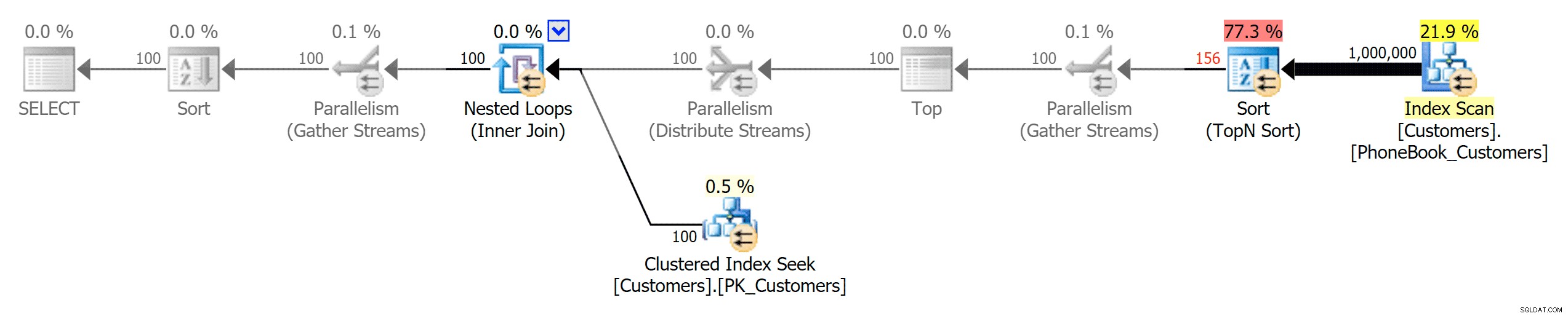 План за традиционен индекс
План за традиционен индекс
 Планирайте за клъстериран индекс на ColumnStore
Планирайте за клъстериран индекс на ColumnStore
 План за неклъстериран индекс на ColumnStore
План за неклъстериран индекс на ColumnStore
Сценарий, който ме интересуваше повече, дори преди да започна да тествам, беше подходът за сортиране на телефонния указател (фамилия, собствено име). В този случай индексите на ColumnStore всъщност бяха доста пагубни за производителността на резултата:
Плановете на ColumnStore тук са близо до огледални изображения на двата плана ColumnStore, показани по-горе за неподдържаното сортиране. Причината е една и съща и в двата случая:скъпи сканирания или сортиране поради липса на поддържащ сортиране индекс.
След това създадох поддържащи индекси „PhoneBook“ на таблиците с индексите на ColumnStore, за да видя дали мога да уговоря различен план и/или по-бързо време за изпълнение в някой от тези сценарии. Създадох тези два индекса, след което възстанових отново:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Ето новите продължителности:
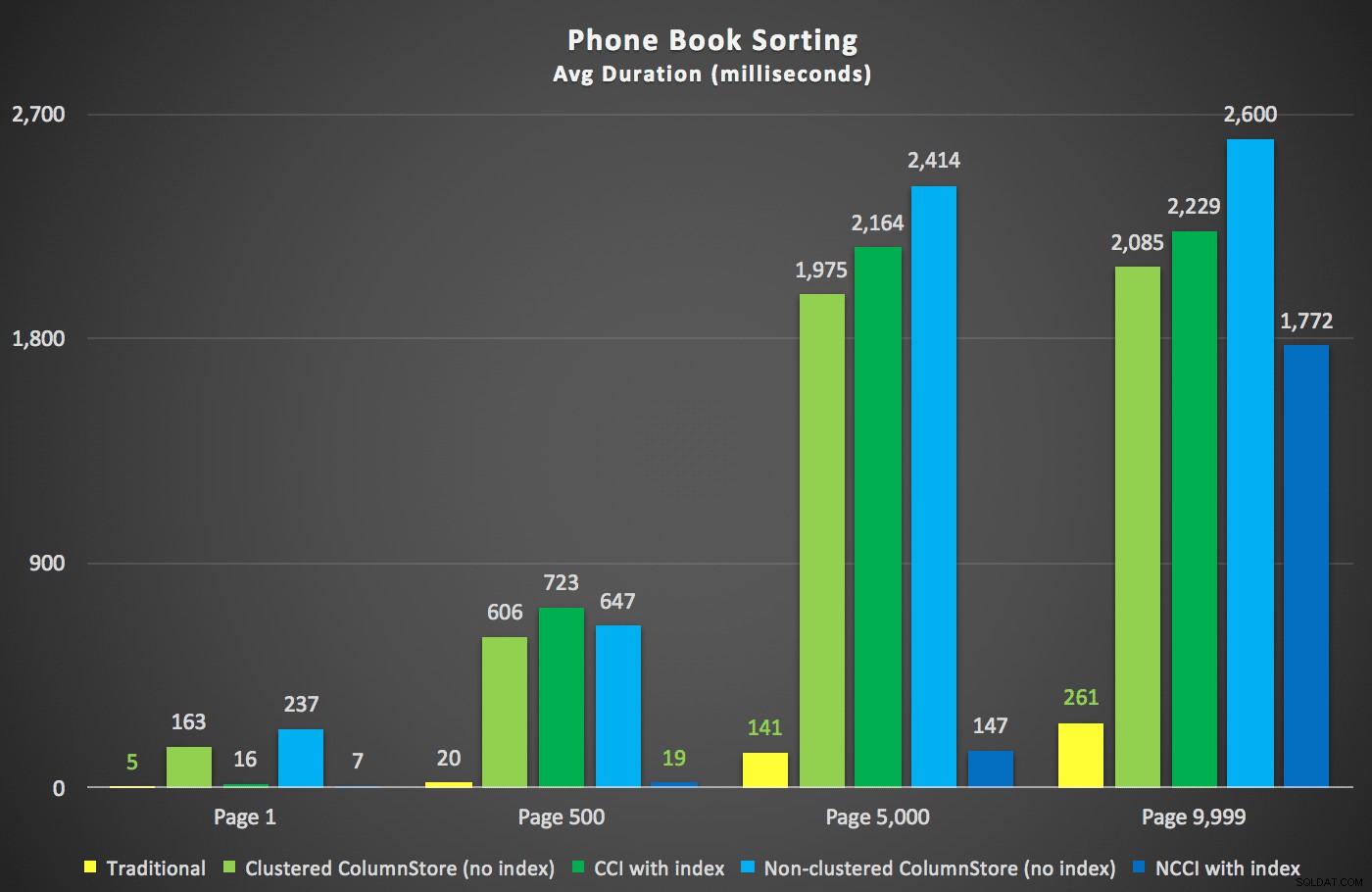
Най-интересното тук е, че сега заявката за пейджинг към таблицата с неклъстерирания индекс на ColumnStore изглежда върви в крак с традиционния индекс, докато не излезем отвъд средата на таблицата. Разглеждайки плановете, можем да видим, че на страница 5000 се използва традиционно сканиране на индекса, а индексът ColumnStore е напълно игнориран:
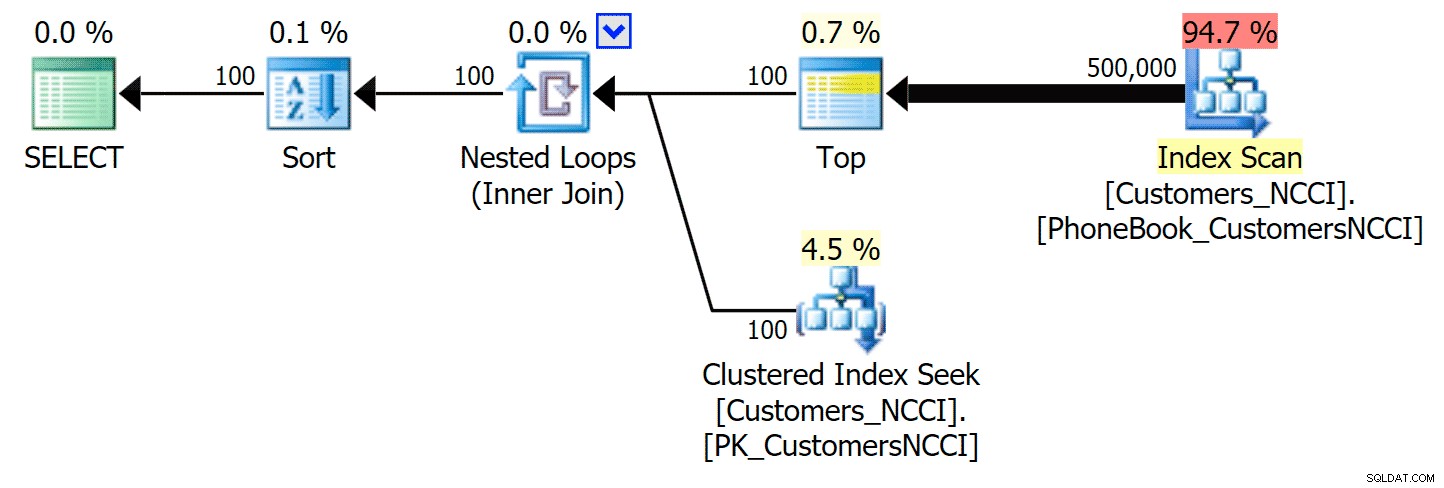 Планът за телефонен указател пренебрегвайки неклъстерирания индекс на ColumnStore
Планът за телефонен указател пренебрегвайки неклъстерирания индекс на ColumnStore
Но някъде между средата от 5000 страници и „края“ на таблицата при 9999 страници, оптимизаторът е достигнал един вид преломна точка и – за точно същата заявка – сега избира да сканира неклъстерирания индекс на ColumnStore :
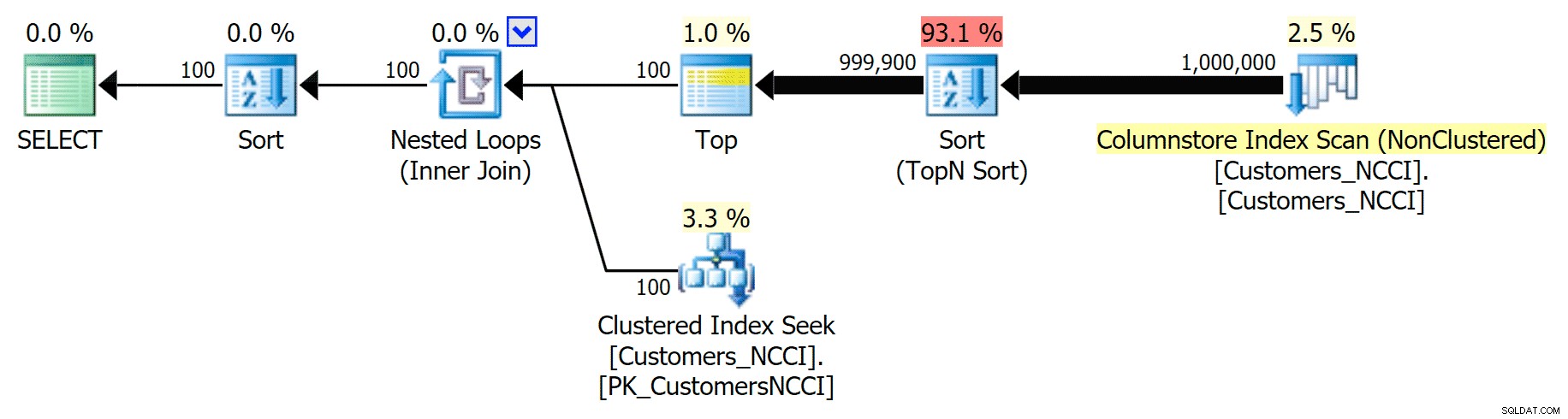 Съвети за планиране на телефонния указател и използва индекса на ColumnStore
Съвети за планиране на телефонния указател и използва индекса на ColumnStore
Това се оказва не толкова добро решение от оптимизатора, главно поради цената на операцията по сортиране. Можете да видите колко по-добра става продължителността, ако намекнете за обикновения индекс:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Това дава следния план, почти идентичен с първия план по-горе (обаче малко по-висока цена за сканирането, просто защото има повече изход):
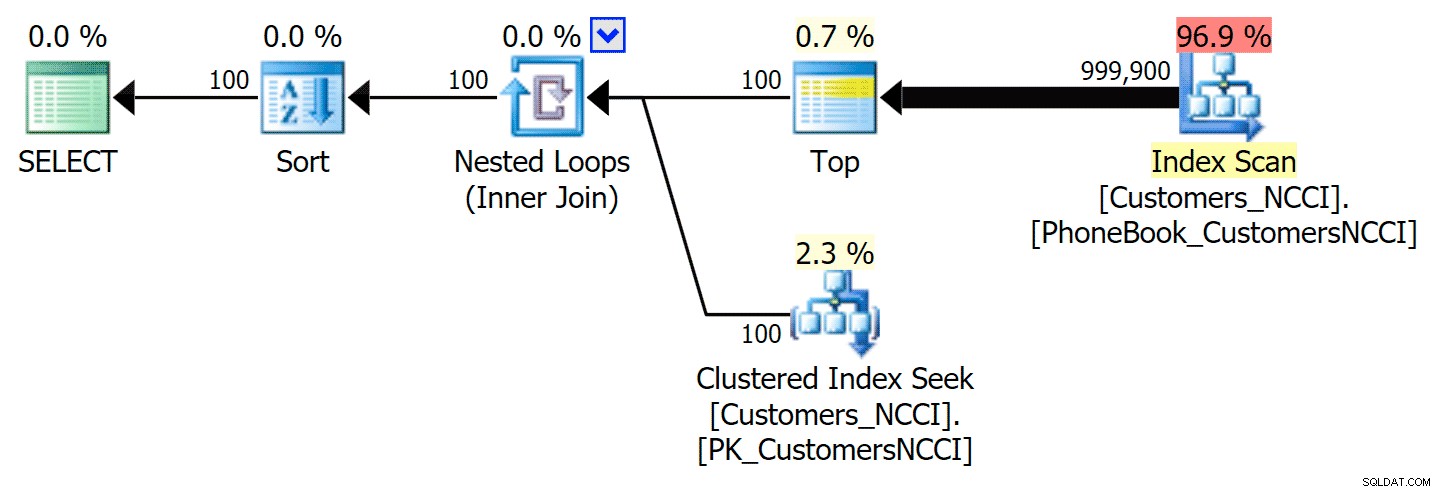 План за телефонен указател с намекнат индекс
План за телефонен указател с намекнат индекс
Можете да постигнете същото, като използвате OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) вместо изричния намек за индекс. Само имайте предвид, че това е същото като да нямате индекса ColumnStore там на първо място.
Заключение
Въпреки че има няколко крайни случая по-горе, при които индексът на ColumnStore може (едва) да се изплати, не ми се струва, че те са подходящи за този специфичен сценарий за пагинация. Мисля, че най-важното е, че докато ColumnStore демонстрира значителни спестявания на място поради компресията, производителността по време на изпълнение не е фантастична поради изискванията за сортиране (въпреки че тези сортове се оценяват да работят в пакетен режим, нова оптимизация за SQL Server 2016).
Като цяло, това може да стане с много повече време, прекарано в изследвания и тестване; като заменя предишни статии, исках да променя възможно най-малко. Бих искал да намеря тази повратна точка, например, и също така бих искал да призная, че това не са точно мащабни тестове (поради размера на VM и ограниченията на паметта) и че ви оставих да гадаете за много показателите по време на изпълнение (най-вече за краткост, но не знам, че диаграма на четения, които не винаги са пропорционални на продължителността, наистина ще ви каже). Тези тестове също така предполагат лукса на SSD дисковете, достатъчно памет, винаги топъл кеш и среда за един потребител. Наистина бих искал да извърша по-голяма батерия от тестове срещу повече данни, на по-големи сървъри с по-бавни дискове и екземпляри с по-малко памет, през цялото време със симулиран паралелизъм.
Въпреки това, това може да бъде и просто сценарий, който ColumnStore не е предназначен да помогне за решаването на първо място, тъй като основното решение с традиционните индекси вече е доста ефективно при изтеглянето на тесен набор от редове – не точно рулевата рубка на ColumnStore. Може би друга променлива, която трябва да се добави към матрицата, е размерът на страницата – всички тестове по-горе изтеглят по 100 реда наведнъж, но какво ще стане, ако сме след 10 000 или 100 000 реда наведнъж, независимо колко голяма е основната таблица?
Имате ли ситуация, при която вашето OLTP натоварване е било подобрено просто чрез добавяне на индекси на ColumnStore? Знам, че те са предназначени за работни натоварвания в стил хранилище за данни, но ако сте виждали предимства на друго място, бих искал да чуя за вашия сценарий и да видя дали мога да включа някакви отличителни черти в моята тестова платформа.