По-рано този месец публикувах съвет за нещо, което вероятно всички бихме искали да не се налага да правим:сортиране или премахване на дубликати от ограничени низове, обикновено включващи функции, дефинирани от потребителя (UDF). Понякога трябва да сглобите отново списъка (без дубликатите) по азбучен ред, а понякога може да се наложи да поддържате оригиналния ред (това може да е списъкът с ключови колони в лош индекс, например).
За моето решение, което се отнася до двата сценария, използвах таблица с числа, заедно с чифт дефинирани от потребителя функции (UDF) – едната за разделяне на низа, другата за повторното му сглобяване. Можете да видите този съвет тук:
- Премахване на дубликати от низове в SQL Server
Разбира се, има множество начини за решаване на този проблем; Предоставих само един метод, който да опитате, ако сте останали с тези структурни данни. @Phil_Factor на Red-Gate последва бърза публикация, показваща подхода му, който избягва функциите и таблицата с числа, като вместо това избира вградена XML манипулация. Той казва, че предпочита да има заявки с един израз и да избягва както функциите, така и обработката ред по ред:
- Отстраняване на дублиране на списъци с разделители в SQL Server
Тогава читател, Стив Мангиамели, публикува решение за цикъл като коментар към съвета. Разсъжденията му бяха, че използването на таблица с числа му се струваше прекалено инженерно.
Всички тримата не успяхме да се справим с един аспект от това, който обикновено ще бъде доста важен, ако изпълнявате задачата достатъчно често или на всяко ниво от мащаб:производителност .
Тестване
Любопитен да видя колко добре ще се представят вграденият XML и подходите за цикъл в сравнение с моето решение, базирано на таблица с числа, създадох фиктивна таблица, за да извърша някои тестове; целта ми беше 5000 реда, със средна дължина на низа над 250 знака и поне 10 елемента във всеки низ. С много кратък цикъл от експерименти успях да постигна нещо много близко до това със следния код:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Това създаде таблица с примерни редове, изглеждащи така (стойностите са съкратени):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Данните като цяло имат следния профил, който трябва да е достатъчно добър, за да разкрие евентуални проблеми с производителността:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Имайте предвид, че преминах към varchar тук от nvarchar в оригиналната статия, тъй като образците, предоставени от Фил и Стив, предполагат varchar , низове, ограничаващи само 255 или 8000 знака, разделители от един символ и т.н. Научих си урока по трудния начин, че ако ще вземеш нечия функция и ще я включиш в сравненията на производителността, ще промениш толкова малко, колкото възможно - в идеалния случай нищо. В действителност винаги бих използвал nvarchar и не предполагайте нищо за най-дългия възможен низ. В този случай знаех, че не губя никакви данни, защото най-дългият низ е само 2905 знака, а в тази база данни нямам никакви таблици или колони, които използват Unicode знаци.
След това създадох моите функции (които изискват таблица с числа). Читател забеляза проблем във функцията в моя съвет, където предположих, че разделителят винаги ще бъде един знак, и коригирах това тук. Преобразувах също почти всичко в varchar(8000) за изравняване на игралното поле по отношение на видовете и дължините на низовете.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO След това създадох единична, вградена функция с таблица, която комбинира двете функции по-горе, нещо, което сега ми се иска да бях направил в оригиналната статия, за да избегна скаларната функция напълно. (Въпреки че е вярно, че не всички Скаларните функции са ужасни в мащаб, има много малко изключения.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Също така създадох отделни версии на вградения TVF, които бяха посветени на всеки от двата избора за сортиране, за да избегна нестабилността на CASE израз, но се оказа, че няма никакво драматично въздействие.
След това създадох двете функции на Стив:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
След това поставих директните заявки на Фил в моята тестова платформа (обърнете внимание, че неговите заявки кодират < като < за да ги предпази от грешки при анализа на XML, но те не кодират > или & – Добавих заместители, в случай че трябва да се предпазите от низове, които потенциално могат да съдържат тези проблемни знаци):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Тестовата платформа беше основно тези две заявки, а също и следните извиквания на функции. След като потвърдих, че всички връщат едни и същи данни, вмъкнах скрипта с DATEDIFF извежда и го записва в таблица:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above След това проведох тестове за производителност на две различни системи (една четириядрена с 8GB и една 8-ядрена VM с 32GB) и във всеки случай, както на SQL Server 2012, така и на SQL Server 2016 CTP 3.2 (13.0.900.73).
Резултати
Резултатите, които наблюдавах, са обобщени в следващата диаграма, която показва продължителност в милисекунди на всеки тип заявка, осреднена по азбучен и оригинален ред, четирите комбинации сървър/версия и серия от 15 изпълнения за всяка пермутация. Кликнете, за да увеличите:
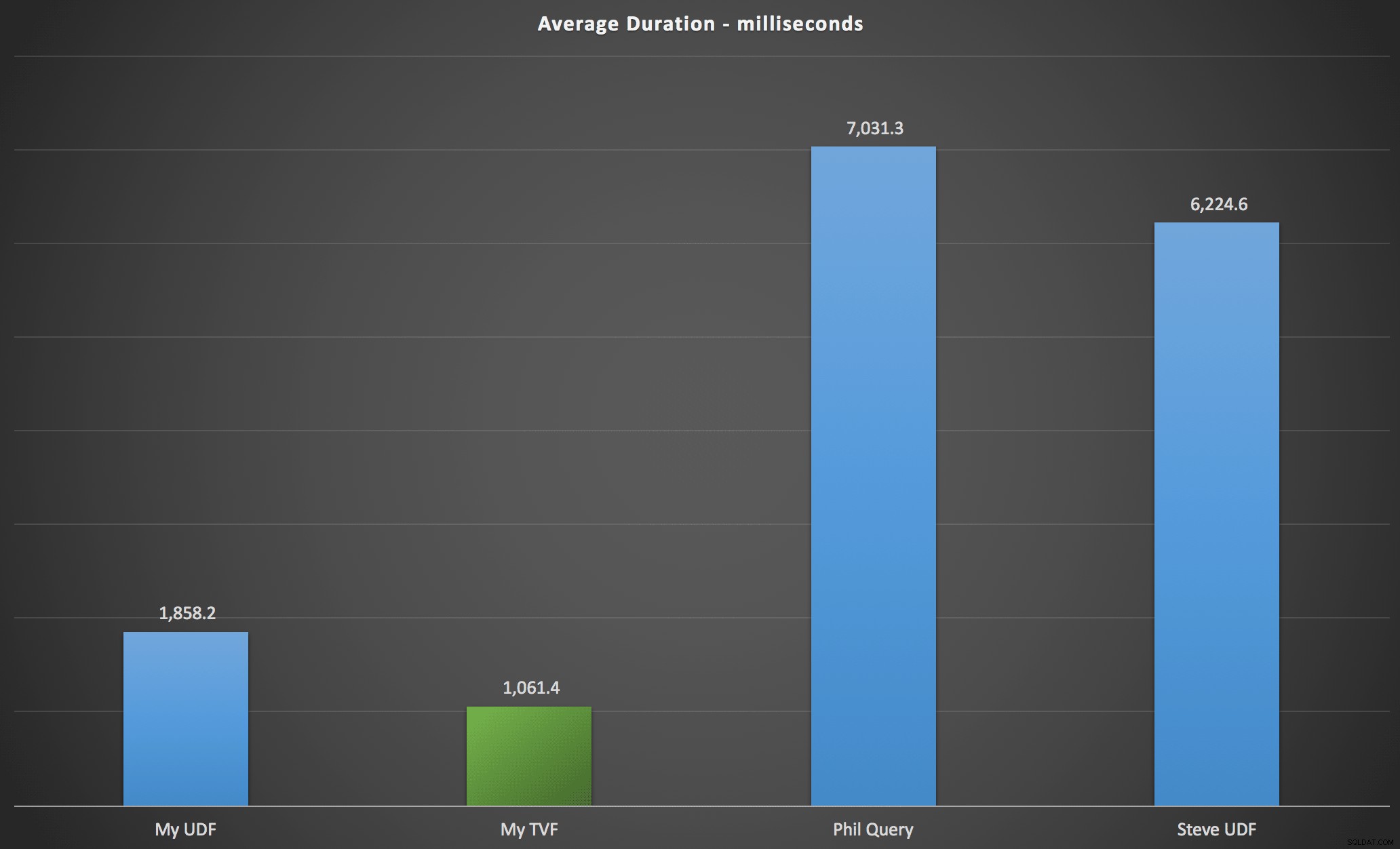
Това показва, че таблицата с числата, макар и да се смята за прекалено проектирана, всъщност дава най-ефективното решение (поне по отношение на продължителността). Това беше по-добре, разбира се, с единичния TVF, който внедрих наскоро, отколкото с вложените функции от оригиналната статия, но и двете решения се въртят около двете алтернативи.
За да влезете в повече подробности, ето разбивките за всяка машина, версия и тип заявка, за поддържане на оригиналната поръчка:
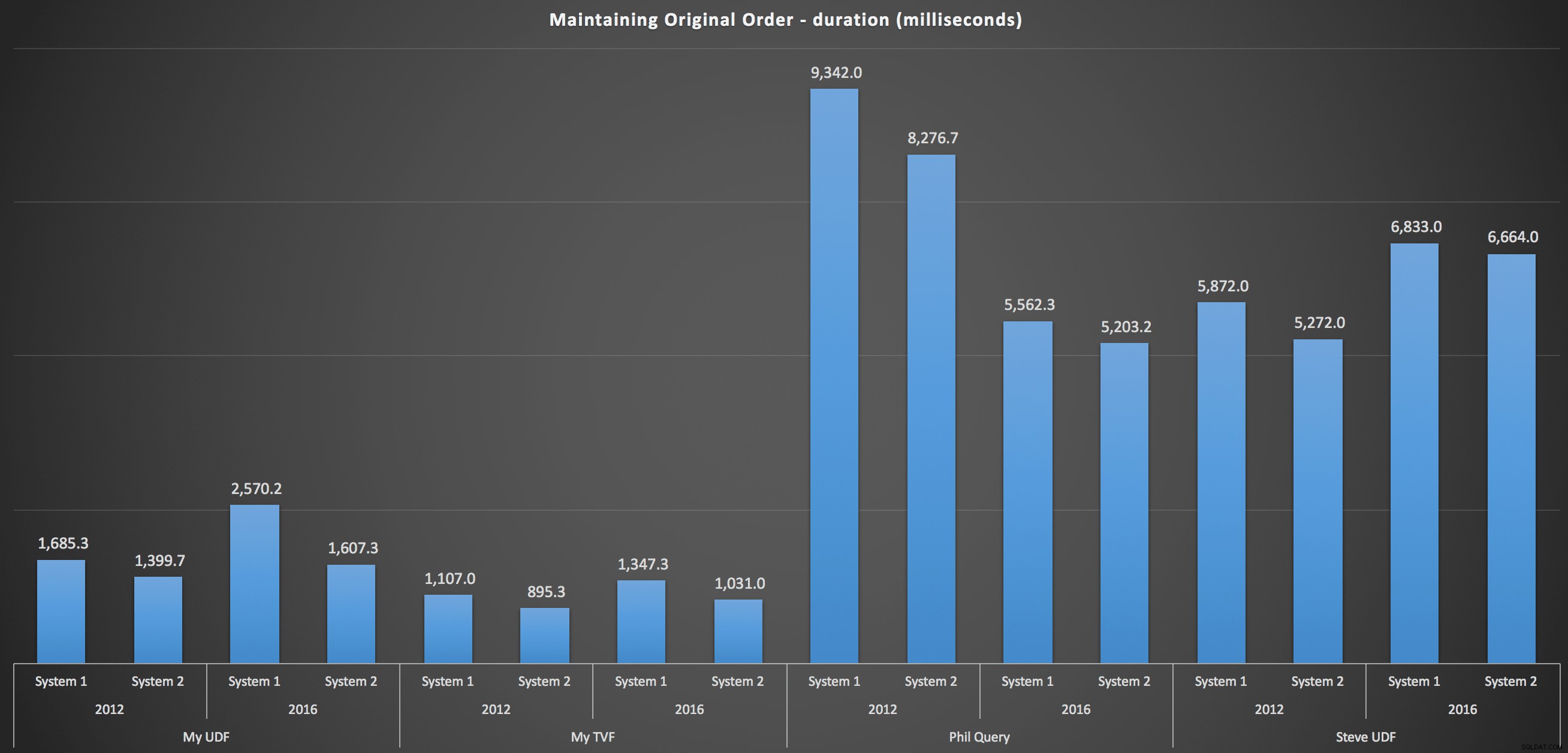
…и за повторно сглобяване на списъка по азбучен ред:
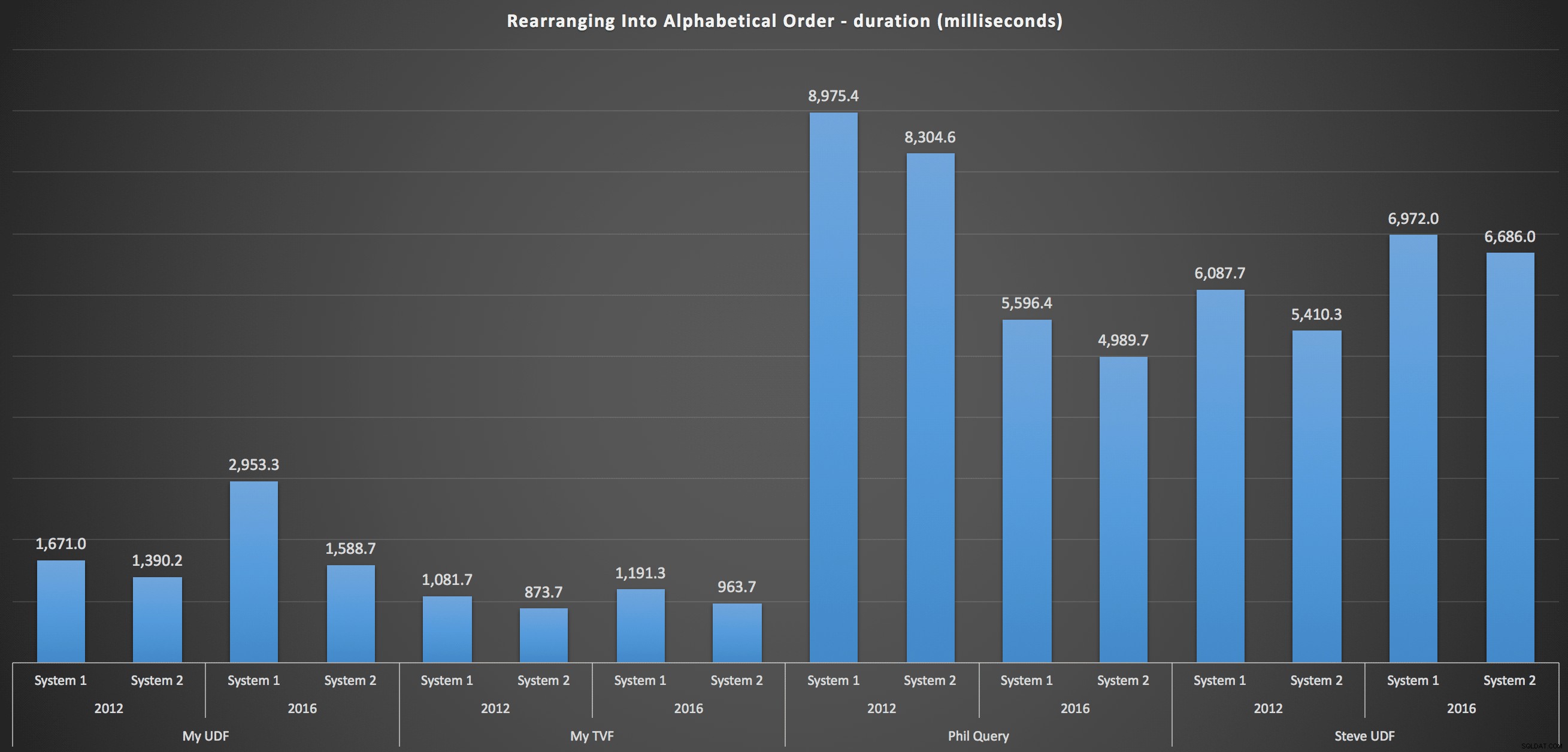
Те показват, че изборът за сортиране е имал малко влияние върху резултата – и двете диаграми са практически идентични. И това има смисъл, защото предвид формата на входните данни няма индекс, който мога да си представя, който да направи сортирането по-ефективно – това е итеративен подход, независимо как го разделяте или как връщате данните. Но е ясно, че някои итеративни подходи като цяло могат да бъдат по-лоши от други и не е задължително използването на UDF (или таблица с числа), което ги прави такива.
Заключение
Докато нямаме собствена функционалност за разделяне и конкатенация в SQL Server, ще използваме всякакви неинтуитивни методи, за да свършим работата, включително дефинирани от потребителя функции. Ако работите с един низ наведнъж, няма да видите голяма разлика. Но тъй като вашите данни се увеличават, ще си струва вашето време да тествате различни подходи (и в никакъв случай не предполагам, че методите по-горе са най-добрите, които ще намерите – дори не погледнах CLR, например, или други T-SQL подходи от тази серия).