Често виждам хората да се борят със SQL Server, когато виждат два различни плана за изпълнение на това, което смятат, че е една и съща заявка. Обикновено това се открива след други наблюдения, като например много различни времена на изпълнение. Казвам, че вярват, че това е една и съща заявка, защото понякога е, а понякога не.
Един от най-честите случаи е, когато те тестват заявка в SSMS и получават различен план от този, който получават от приложението си. Тук има потенциално два фактора (които също могат да бъдат от значение, когато сравнението НЕ е между приложението и SSMS):
- Приложението почти винаги има различен
SETнастройки от SSMS (това са неща катоARITHABORT,ANSI_NULLSиQUOTED_IDENTIFIER). Това принуждава SQL Server да съхранява двата плана поотделно; Ерланд Сомарског е разгледал това много подробно в статията си „Бавно в приложението, бързо в SSMS?
- Параметрите, използвани от приложението, когато неговото копие на плана е било компилирано за първи път, може да са много различни и да доведат до различен план от тези, използвани при първото изпълнение на заявката от SSMS – това е известно като подслушване на параметри . Ерланд също говори за това задълбочено и аз няма да връщам препоръките му, но обобщавам, като ви напомня, че тестването на заявката на приложението в SSMS не винаги е полезно, тъй като е малко вероятно да бъде тест от ябълки към ябълки.
Има няколко други сценария, които са малко по-неясни, които споменавам в моята беседа за лоши навици и най-добри практики. Това са случаи, в които плановете не са различни, но има множество копия на един и същ план, които раздуват кеша на плана. Реших, че трябва да ги спомена тук, защото винаги хващат толкова много хора изненадващо.
cAsE и белите интервали са важни
SQL Server хешира текста на заявката в двоичен формат, което означава, че всеки един знак в текста на заявката е от решаващо значение. Нека вземем следните прости заявки:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO SELECT StoreID FROM Sales.Customer; GO -- original query GO SELECT StoreID FROM Sales.Customer; GO ----^---- extra space GO SELECT storeid FROM sales.customer; GO ---- lower case names GO select StoreID from Sales.Customer; GO ---- lower case keywords GO
Те генерират абсолютно същите резултати, очевидно, и генерират абсолютно същия план. Ако обаче погледнем какво имаме в кеша на плана:
SELECT t.[text], p.size_in_bytes, p.usecounts FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t WHERE LOWER(t.[text]) LIKE N'%sales'+'.'+'customer%';
Резултатите са жалки:
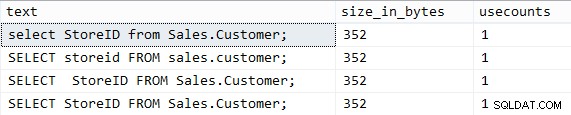
Така че в този случай е ясно, че главният и пробелът са много важни. Говорих за това много по-подробно миналия май.
Препратките към схемата са важни
Преди съм писал в блог за важността на уточняването на префикса на схемата при препращане към всеки обект, но по това време не бях напълно наясно, че това също има последици за кеша на плана.
Нека да разгледаме един много прост случай, в който имаме двама потребители с различни схеми по подразбиране и те изпълняват точно същия текст на заявката, като не успяват да препратят обекта по неговата схема:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO CREATE USER SQLPerf1 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Sales; CREATE USER SQLPerf2 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Person; GO CREATE TABLE dbo.AnErrorLog(id INT); GRANT SELECT ON dbo.AnErrorLog TO SQLPerf1, SQLPerf2; GO EXECUTE AS USER = N'SQLPerf1'; GO SELECT id FROM AnErrorLog; GO REVERT; GO EXECUTE AS USER = N'SQLPerf2'; GO SELECT id FROM AnErrorLog; GO REVERT; GO
Сега, ако погледнем кеша на плана, можем да извлечем sys.dm_exec_plan_attributes за да разберем точно защо получаваме два различни плана за идентични заявки:
SELECT t.[text], p.size_in_bytes, p.usecounts, [schema_id] = pa.value, [schema] = s.name FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS pa INNER JOIN sys.schemas AS s ON s.[schema_id] = pa.value WHERE t.[text] LIKE N'%AnError'+'Log%' AND pa.attribute = N'user_id';
Резултати:

И ако стартирате всичко отново, но добавете dbo. префикс към двете заявки, ще видите, че има само един план, който се използва два пъти. Това се превръща в много убедителен аргумент за винаги пълно препращане на обекти.
ЗАДАВАНЕ НА Настройки редукс
Като странична бележка можете да използвате подобен подход, за да определите дали SET настройките са различни за две или повече версии на една и съща заявка. В този случай ние разследваме заявките, свързани с множество планове, генерирани от различни извиквания към една и съща съхранена процедура, но можете също да ги идентифицирате по текста на заявката или хеша на заявката.
SELECT p.plan_handle, p.usecounts, p.size_in_bytes, set_options = MAX(a.value) FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS a WHERE t.objectid = OBJECT_ID(N'dbo.procedure_name') AND a.attribute = N'set_options' GROUP BY p.plan_handle, p.usecounts, p.size_in_bytes;
Ако имате няколко резултата тук, трябва да видите различни стойности за set_options (което е битова маска). Това е само началото; Ще се справя тук и ще ви кажа, че можете да определите какъв набор от опции са активирани за всеки план, като разопаковате стойността според раздела „Оценка на опциите за набор“ тук. Да, толкова съм мързелив.
Заключение
Има няколко причини, поради които може да видите различни планове за една и съща заявка (или това, което смятате, че е една и съща заявка). В повечето случаи можете да изолирате причината доста лесно; предизвикателството често е да знаеш да го търсиш на първо място. В следващата си публикация ще говоря за малко по-различна тема:защо база данни, възстановена на „идентичен“ сървър, може да доведе до различни планове за една и съща заявка.