
Това също не е добра фрагментация
Миналия месец писах за неочаквано групирана фрагментация на индекси, така че този път бих искал да обсъдя някои от нещата, които можете да направите, за да избегнете фрагментирането на индекса. Предполагам, че сте прочели предишната публикация и сте запознати с термините, които дефинирах там, и в останалата част от тази статия, когато казвам „фрагментация“, имам предвид проблемите както с логическата фрагментация, така и с ниската плътност на страниците.
Изберете добър ключ за клъстер
Най-скъпата структура от данни, с която да се работи за премахване на фрагментацията, е клъстерираният индекс на таблица, защото това е най-голямата структура, тъй като съдържа всички данни от таблицата. От гледна точка на фрагментацията има смисъл да изберете ключ на клъстер, който съответства на шаблона за вмъкване на таблица, така че няма възможност вмъкване да се случи на страница, където няма място и следователно да причини разделяне на страницата и да въведе фрагментация.
Какво представлява най-добрият ключ на клъстера за дадена таблица е въпрос на много дебати, но като цяло няма да сбъркате, ако вашият клъстер ключ има следните прости свойства:
- Тесен (т.е. възможно най-малко колони)
- Статично (т.е. никога не го актуализирате)
- Уникален
- Непрекъснато нарастващо
Това е постоянно нарастващото свойство, което е най-важно за предотвратяване на фрагментация, тъй като избягва случайни вмъквания, които могат да причинят разделяне на страници на вече пълни страници. Примери за такъв ключов избор са колони с int identity и bigint identity или дори последователен GUID от функцията NEWSEQUENTIALID().
С тези типове ключове новите редове ще имат ключова стойност, която гарантирано е по-висока от всички останали в таблицата и така точката на вмъкване на новия ред ще бъде в края на най-дясната страница в структурата на клъстерирания индекс. В крайна сметка новите редове ще запълнят тази страница и друга страница ще бъде добавена от дясната страна на индекса, но без да се случи разцепване на страницата.
Сега, ако имате клъстериран индексен ключ, който не се увеличава непрекъснато, може да е много сложна и неприятна процедура да го промените на постоянно нарастващ, така че не се притеснявайте – вместо това можете да използвате фактор за запълване, както обсъждам по-долу.
Между другото, за много по-задълбочено вникване в избора на клъстерен ключ и всички последствия от него, вижте категорията на блога на Кимбърли Clustering Key (четете отдолу нагоре).
Не актуализирайте индексните ключови колони
Всеки път, когато се актуализира ключова колона, това не е просто актуализация на място, въпреки че много места онлайн и в книги казват, че е (грешат). Ключовата колона не може да бъде актуализирана на място, тъй като новата стойност на ключа тогава би означавала, че редът е в грешен ключов ред за индекса. Вместо това актуализация на ключова колона се превежда в пълно изтриване на ред плюс вмъкване на пълен ред с новата стойност на ключа. Ако страницата, където ще бъде вмъкнат новият ред, няма достатъчно място на нея, ще се случи разделяне на страницата, което ще причини фрагментация.
Избягването на актуализации на ключови колони трябва да бъде лесно да се направи за клъстерирания индекс, тъй като това е лош дизайн, който изисква актуализиране на ключа на клъстера на ред от таблица. За неклъстерирани индекси обаче е неизбежно, ако актуализациите на таблицата включват колони, върху които има неклъстериран индекс. За тези случаи ще трябва да използвате коефициент на запълване.
Не актуализирайте колоните с променлива дължина
Това е по-лесно да се каже, отколкото да се направи. Ако трябва да използвате колони с променлива дължина и е възможно те да бъдат актуализирани, тогава е възможно те да нараснат и така да изискват повече място за актуализирания ред, което води до разделяне на страницата, ако страницата вече е пълна.
Има няколко неща, които можете да направите, за да избегнете фрагментирането в този случай:
- Използвайте коефициент на запълване
- Вместо това използвайте колона с фиксирана дължина, ако режийните разходи за всички допълнителни байтове за допълване са по-малко проблем от фрагментацията или използването на фактор за запълване
- Използвайте стойност за място, за да „резервирате“ място за колоната – това е трик, който можете да използвате, ако приложението влезе в нов ред и след това се върне, за да попълни някои от детайлите, причинявайки разширяване на колона с променлива дължина
- Извършете изтриване плюс вмъкване вместо актуализация
Използвайте коефициент на запълване
Както можете да видите, много от начините за избягване на фрагментацията са неприятни, тъй като включват промени в приложението или схемата и така използването на фактор за запълване е лесен начин за смекчаване на фрагментацията.
Коефициентът на запълване на индекса е настройка за индекса, която определя колко празно място да се остави на всяка страница на ниво лист, когато индексът е създаден, преизграден или реорганизиран. Идеята е, че има достатъчно свободно място на страницата, за да позволи произволни вмъквания или израствания на редове (от добавяне на етикет за версия или актуализирани колони с променлива дължина), без страницата да се запълва и да изисква разделяне на страницата. Въпреки това, в крайна сметка страницата ще се запълни и така периодично свободното пространство трябва да се опреснява чрез повторно изграждане или реорганизиране на индекса (обикновено се нарича извършване на поддръжка на индекса). Номерът е в намирането на подходящия коефициент на запълване, който да използвате, заедно с правилната периодичност на поддръжка на индекса.
Можете да прочетете повече за задаването на фактор за запълване в MSDN тук. Не попадайте в капана да зададете коефициента на запълване за целия екземпляр (използвайки sp_configure), тъй като това означава, че всички индекси ще бъдат преизградени или реорганизирани с помощта на тази стойност на фактора на запълване, дори тези индекси, които нямат проблеми с фрагментацията. Не искате вашите големи клъстерирани индекси, с хубави постоянно нарастващи ключове, всички да имат 30% от тяхното пространство на ниво лист, за да се подготвят за произволни вмъквания, които никога няма да се случат. Много по-добре е да разберете кои индекси всъщност са засегнати от фрагментацията и да зададете само коефициент на запълване за тях.
Няма правилен отговор или магическа формула, която мога да ви дам за това. Общоприетата практика е да се постави коефициент на запълване от 70 (което означава да се остави 30% свободно пространство) за онези индекси, където фрагментацията е проблем, да се следи колко бързо се случва фрагментацията и след това да се променя или коефициентът на запълване, или честотата на поддръжка на индекса (или и двете).
Да, това означава, че умишлено губите място в индексите, за да избегнете фрагментацията, но това е добър компромис, като се има предвид колко скъпи са разделянето на страници и колко вредно може да бъде фрагментирането за производителността. И да, въпреки това, което някои биха казали, това все още е важно, дори ако използвате SSD.
Резюме
Има някои прости неща, които можете да направите, за да избегнете фрагментирането, но веднага щом влезете в неклъстерирани индекси или използвате изолация на моментни снимки или четими вторични елементи, фрагментацията издига грозната си глава и трябва да се опитате да я предотвратите.
Сега не се колебайте и не мислете, че трябва да зададете коефициент на запълване от 70 за всичките си екземпляри – трябва да ги изберете и настроите внимателно, както описах по-горе.
И не забравяйте за SQL Sentry Fragmentation Manager, който можете да използвате (като добавка към Performance Advisor), за да ви помогне да разберете къде са проблемите с фрагментацията и след това да ги разрешите. Например, в раздела Индекси можете лесно да сортирате индексите си първо по най-висока фрагментация (и, ако желаете, да приложите филтър към колоната за броя на редовете, за да игнорирате по-малките си таблици):
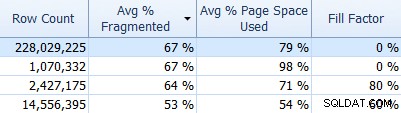
И след това вижте дали тези индекси използват коефициента на запълване по подразбиране (0%) или може би коефициент на запълване, който не е по подразбиране, което може да не е подходящо за вашите данни и DML модели. Ще ви позволя да познаете кои от горната екранна снимка ще ми е най-интересно да проуча. Внедряването на по-подходящи фактори за запълване на индекса е най-лесният начин за справяне с всички проблеми, които забележите.



