В предишната си публикация от тази серия демонстрирах, че не всички сценарии на заявки могат да се възползват от OLTP технологиите в паметта. Всъщност използването на Hekaton в определени случаи на употреба може действително да има пагубен ефект върху производителността (щракнете, за да увеличите):

Профил за наблюдение на производителността по време на изпълнение на съхранената процедура
Въпреки това бих могъл да подредя тестето срещу Hekaton в този сценарий по два начина:
- Типът на оптимизираната за паметта таблица, който създадох, имаше 256 сегменти, но предавах до 2000 стойности за сравнение. В по-скорошна публикация в блог от екипа на SQL Server те обясниха, че преоразмеряването на броя на кофите е по-добре, отколкото намаляването му – нещо, което знаех като цяло, но не осъзнавах, че също има значителни ефекти върху променливите в таблицата:Keep имайте предвид, че за хеш индекс bucket_count трябва да бъде около 1-2X броя на очакваните уникални индексни ключове. Превишаването на размера обикновено е по-добро от оразмеряването:ако понякога вмъквате само 2 стойности в променливите, но понякога вмъквате до 1000 стойности, обикновено е по-добре да посочите
BUCKET_COUNT=1000.Те не обсъждат изрично действителната причина за това и съм сигурен, че има много технически подробности, в които бихме могли да се задълбочим, но предписателните указания изглежда са прекалено големи.
- Първичният ключ беше хеш-индекс на две колони, докато параметърът с таблична стойност се опитваше да съпостави стойности само в една от тези колони. Много просто, това означаваше, че хеш индексът не може да се използва. Тони Роджърсън обяснява това малко по-подробно в скорошна публикация в блога:Хешът се генерира във всички колони, съдържащи се в индекса, трябва също да посочите всички колони в хеш индекса във вашия израз за проверка на равенството, в противен случай индексът не може да се използва .
Не го показвах преди, но забележете, че планът срещу оптимизираната за памет таблица с хеш индекс с две колони всъщност прави сканиране на таблица, а не търсенето на индекс, което може да очаквате спрямо неклъстерирания хеш индекс (тъй като водещият колоната беше
SalesOrderID):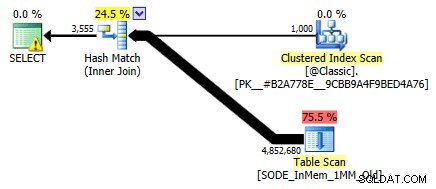
План на заявката, включващ таблица в паметта с две колони хеш индексЗа да бъдем по-конкретни, в хеш индекс, водещата колона не означава хълм от боб сама по себе си; хешът все още се съпоставя във всички колони, така че изобщо не работи като традиционен индекс на B-дърво (с традиционен индекс предикат, включващ само водещата колона, все още може да бъде много полезен при елиминирането на редове).
Какво да правя?
Е, първо, създадох вторичен хеш индекс само за SalesOrderID колона. Пример за една такава таблица с милион кофи:
СЪЗДАВАНЕ НА ТАБЛИЦА [dbo].[SODE_InMem_1MM]( [SalesOrderID] [int] НЕ НУЛЕВО, [SalesOrderDetailID] [int] НЕ НУЛВО, [CarrierTrackingNumber] [nvarchar](25) СЪБОРЯВАНЕ SQL_Latin1_General_CP1_CI] [OASSQLLTY] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [числова](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL ПЪРВИЧЕН КЛЮЧ НЕКЛУСТРИРАН ХЕШ ( [SalesOrderID], [SalesOrderDetailID] ) WITH (BUCKET_COUNT =10488576), който не е добавен към този втори индекс:*/ INDEX x NONCLUSTERED HASH ( [SalesOrderID] ) WITH (BUCKET_COUNT =1048576) /* Използвах същия брой сегменти, за да минимизирам тестовите пермутации */ ) WITH (MEMORY_OPTIMIZED =ON, SCHEDABILITY =DURABILITY);Не забравяйте, че нашите типове таблици са настроени по следния начин:
СЪЗДАВАЙТЕ ТИП dbo.ClassicTVP КАТО ТАБЛИЦА( Item INT PRIMARY KEY); CREATE TYPE dbo.InMemoryTVP КАТО ТАБЛИЦА( Елемент INT NOT NULL ПЪРВЕН КЛЮЧ НЕКЛУСТРИРАН ХЕШ С (BUCKET_COUNT =256)) WITH (MEMORY_OPTIMIZED =ON);След като попълних новите таблици с данни и създадох нова съхранена процедура за справка с новите таблици, планът, който получаваме, показва правилно търсене на индекс спрямо хеш индекса с една колона:
Подобрен план с помощта на хеш индекса с една колонаНо какво наистина би означавало това за производителността? Проведох отново същия набор от тестове – заявки към тази таблица с броеве от 16K, 131K и 1MM; използване както на класически, така и на TVP в паметта със 100, 1000 и 2000 стойности; и в случая с TVP в паметта, като се използва както традиционна съхранена процедура, така и нативно компилирана съхранена процедура. Ето как се развива производителността при 10 000 повторения на комбинация:
Профил на производителност за 10 000 повторения срещу хеш индекс с една колона, използвайки TVP с 256 кофиМоже да си помислите, хей, този профил на производителност не изглежда толкова страхотно; напротив, много е по-добър от предишния ми тест миналия месец. Това просто демонстрира, че броят на кофите за таблицата може да има огромно влияние върху способността на SQL Server да използва ефективно хеш индекса. В този случай използването на кофа от 16K очевидно не е оптимално за нито един от тези случаи и става експоненциално по-лошо с увеличаване на броя на стойностите в TVP.
Сега, не забравяйте, че броят на кофата на TVP беше 256. И така, какво ще се случи, ако го увелича, съгласно насоките на Microsoft? Създадох втори тип таблица с по-подходящ размер на кофата. Тъй като тествах 100, 1000 и 2000 стойности, използвах следващата степен на 2 за броя на кофата (2048):
СЪЗДАДЕТЕ ТИП dbo.InMemoryTVP КАТО ТАБЛИЦА( Елемент INT NOT NULL ПЪРВИЧЕН КЛЮЧ НЕКЛУСТРИРАН ХЕШ С (BUCKET_COUNT =2048)) WITH (MEMORY_OPTIMIZED =ON);Създадох поддържащи процедури за това и пуснах отново същата батерия от тестове. Ето профилите на производителност един до друг:
Сравнение на профил на производителност с 256- и 2048-кофи TVPsПромяната в броя на кофите за типа таблица не оказа въздействието, което бих очаквал, като се има предвид изявлението на Microsoft за оразмеряването. Наистина нямаше много положителен ефект; всъщност за някои сценарии беше малко по-зле. Но като цяло профилите на производителност са, за всички намерения и цели, едни и същи.
Това, което имаше огромен ефект обаче, беше създаването на *десния* хеш индекс, който да поддържа модела на заявката. Бях благодарен, че успях да демонстрирам, че – въпреки предишните ми тестове, които показаха друго – таблицата в паметта и TVP в паметта могат да победят стария начин за постигане на същото нещо. Нека просто вземем най-екстремния случай от предишния ми пример, когато таблицата имаше само хеш индекс от две колони:
Профил на производителност за 10 повторения срещу хеш индекс с две колониНай-дясната лента показва продължителността на само 10 итерации на съхранената процедура, съвпадаща с неподходящ хеш индекс – времена на заявка варират от 735 до 1601 милисекунди. Сега обаче, с правилния хеш индекс на място, същите заявки се изпълняват в много по-малък диапазон – от 0,076 милисекунди до 51,55 милисекунди. Ако пропуснем най-лошия случай (16K броя кофи), несъответствието е още по-изразено. Във всички случаи това е поне два пъти по-ефективно (поне по отношение на продължителността) от всеки метод, без наивно компилирана съхранена процедура, спрямо същата оптимизирана за памет таблица; и стотици пъти по-добър от който и да е от подходите срещу нашата стара оптимизирана за памет таблица с единствения хеш индекс с две колони.
Заключение
Надявам се, че съм демонстрирал, че трябва да се внимава при внедряване на оптимизирани за памет таблици от всякакъв тип и че в много случаи използването на оптимизиран за паметта TVP самостоятелно може да не доведе до най-голямо увеличение на производителността. Ще искате да обмислите използването на компилираните в собствената си съхранени процедури, за да получите най-добрия резултат от парите си, и за най-добър мащаб, наистина ще искате да обърнете внимание на броя на кофите за хеш индексите във вашите оптимизирани за памет таблици (но може би не толкова много внимание към типовете ви оптимизирани за паметта таблици).
За допълнително четене относно технологията In-Memory OLTP като цяло, може да искате да разгледате тези ресурси:




- Блогът на екипа на SQL Server (Етикет:Hekaton и Tag:In-Memory OLTP – кодовите имена не са ли забавни?)
- Блогът на Боб Бошемин
- Блогът на Клаус Ашенбренер