@rob_farley вашето скорошно решение за stackoverflow за подреждане първо по стойност, след което поле е гений! Искам да ви благодаря лично.
— Джоел Сако (@Jsac90) 11 август 2016 г.
Видях, че този туит излиза...
И ме накара да погледна за какво се отнася, защото не бях написал нищо „наскоро“ в StackOverflow относно подреждането на данни. Оказа се, че това е този отговор, който съм написал , който въпреки че не беше приет отговор, събра над сто гласа.
Човекът, който задава въпроса, имаше много прост проблем – искаше да накара определени редове да се появят първи. И моето решение беше просто:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Изглежда, че е бил популярен отговор, включително за Джоел Сако (според този туит по-горе).
Идеята е да се формира израз и да се подреди по този начин. ORDER BY не се интересува дали е действителна колона или не. Бихте могли да направите същото с APPLY, ако наистина предпочитате да използвате „колона“ във вашата клауза ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Ако използвам някои заявки срещу WideWorldImporters, мога да ви покажа защо тези две заявки наистина са абсолютно еднакви. Ще направя заявка в таблицата Sales.Orders, като поискам Поръчките за Salesperson 7 да се появят първи. Също така ще създам подходящ индекс за покриване:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Плановете за тези две заявки изглеждат идентични. Те работят идентично – същите четения, същите изрази, те наистина са една и съща заявка. Ако има малка разлика в действителния процесор или продължителност, това е случайност поради други фактори.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
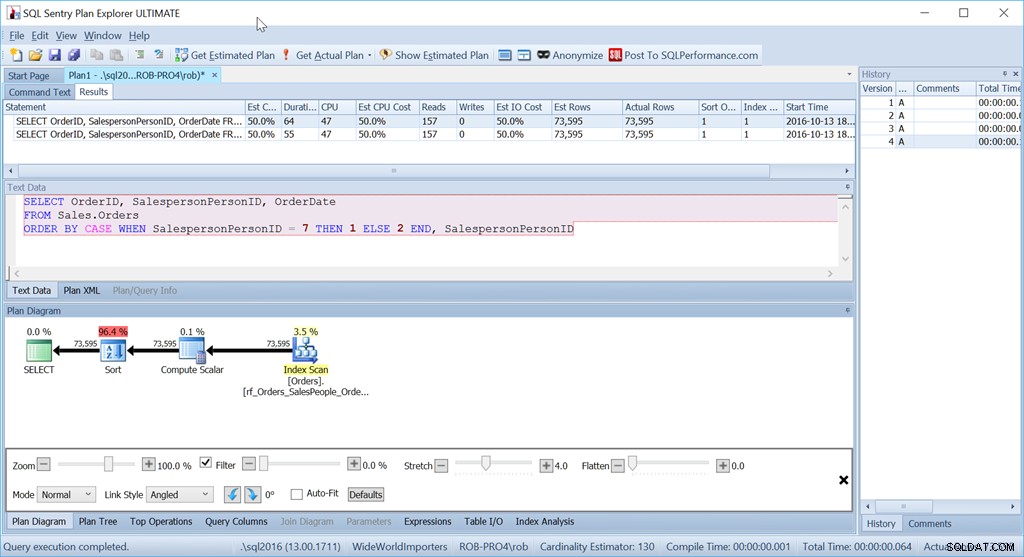
И все пак това не е заявката, която всъщност бих използвал в тази ситуация. Не и ако изпълнението беше важно за мен. (Обикновено е така, но не винаги си струва да пишете заявка на дълъг път, ако количеството данни е малко.)
Това, което ме притеснява е операторът Sort. Това е 96,4% от цената!
Помислете дали просто искаме да поръчаме от SalespersonPersonID:
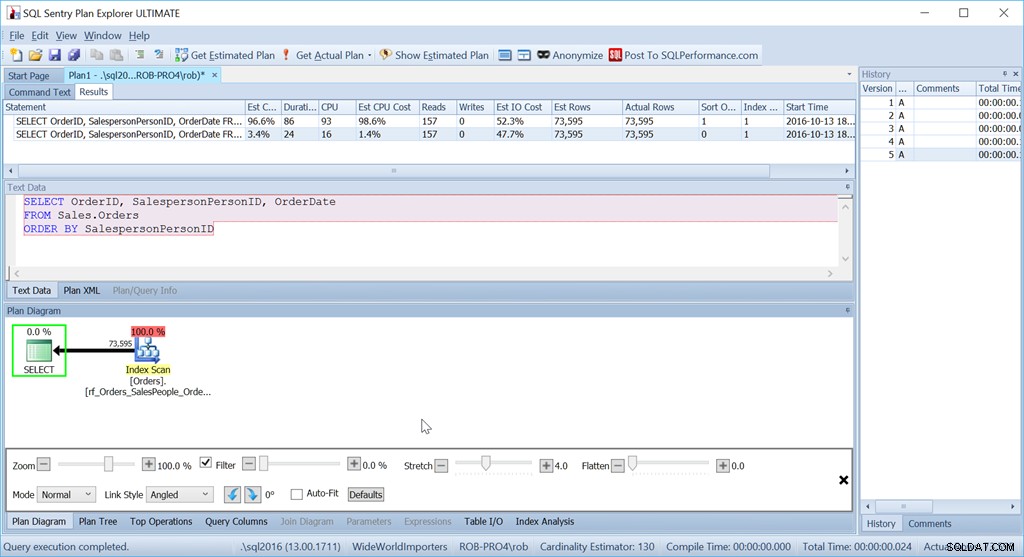
Виждаме, че приблизителната цена на процесора на тази по-проста заявка е 1,4% от партидата, докато при персонализираната версия е 98,6%. Това е СЕДЕСЕТ ПЪТИ по-лошо. Показанията обаче са еднакви – това е добре. Продължителността е много по-лоша, както и процесорът.
Не обичам сортовете. Те могат да бъдат гадни.
Една опция, която имам тук, е да добавя изчислена колона към моята таблица и да я индексирам, но това ще окаже влияние върху всичко, което търси всички колони в таблицата, като ORM, Power BI или всичко, което прави SELECT * . Така че това не е толкова страхотно (въпреки че ако някога успеем да добавим скрити изчислени колони, това би било наистина хубава опция тук).
Друг вариант, който е по-продължителен (някои може да предполагат, че би ми подхождало – и ако си мислите, че:Ой! Не бъди толкова груб!) и използва повече четения, е да помислим какво бихме направили в реалния живот, ако трябваше да направим това.
Ако имах купчина от 73 595 поръчки, сортирани по поръчка на продавач, и трябваше първо да ги върна с конкретен продавач, нямаше да пренебрегна реда, в който бяха, и просто бих ги сортирал всички, щях да започна с гмуркане и намиране на тези за Salesperson 7 – запазвайки ги в реда, в който са били. Тогава щях да намеря тези, които не бяха тези, които не бяха Salesperson 7 – поставяйки ги на следващо място и отново ги държах в реда, в който вече бяха в.
В T-SQL това се прави по следния начин:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Това получава два набора данни и ги конкатенира. Но оптимизаторът на заявки може да види, че трябва да поддържа реда на SalespersonPersonID, след като двата набора са свързани, така че прави специален вид конкатенация, която поддържа този ред. Това е присъединяване с обединяване (свързване) и планът изглежда така:
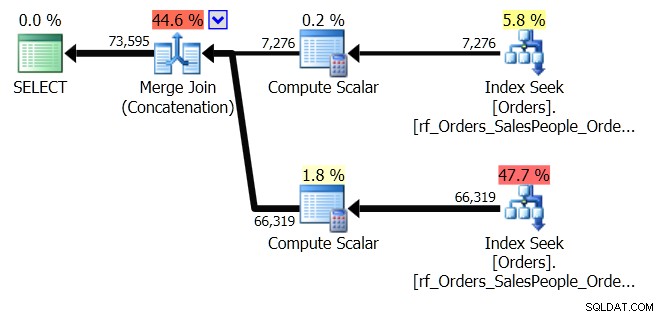
Виждате, че е много по-сложно. Но се надяваме, че ще забележите, че няма оператор за сортиране. Присъединяването на сливане (Конкатенация) извлича данните от всеки клон и създава набор от данни, който е в правилния ред. В този случай първо ще изтегли всички 7 276 реда за Salesperson 7, а след това ще изтегли останалите 66 319, защото това е необходимата поръчка. Във всеки набор данните са в реда на SalespersonPersonID, който се поддържа, докато данните преминават през тях.
Споменах по-рано, че използва повече четения и го прави. Ако покажа изхода SET STATISTICS IO, сравнявайки двете заявки, виждам това:
Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред чете 0.Таблица 'Поръчки'. Брой на сканиране 1, логически четения 157, физически четения 0, четене напред 0, логически четения 0, лобни физически четения 0, лобно четене напред чете 0.
Таблица 'Поръчки '. Брой на сканиране 3, логически четения 163, физически четения 0, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Използвайки версията за персонализирано сортиране, това е само едно сканиране на индекса, като се използват 157 четения. Използвайки метода "Union All", това са три сканирания – едно за SalespersonPersonID =7, едно за SalespersonPersonID <7 и едно за SalespersonPersonID> 7. Можем да видим последните две, като разгледаме свойствата на второто търсене в индекс:
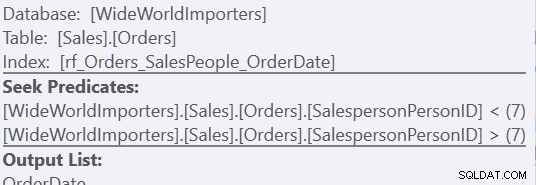
За мен обаче ползата идва от липсата на работна маса.
Вижте приблизителната цена на процесора:

Това не е толкова малко, колкото нашите 1,4%, когато избягваме напълно сортирането, но все пак е значително подобрение спрямо нашия метод за персонализирано сортиране.
Но едно предупреждение...
Да предположим, че съм създал този индекс по различен начин и имах OrderDate като ключова колона, а не като включена колона.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Сега моят метод „Union All“ изобщо не работи както трябва.
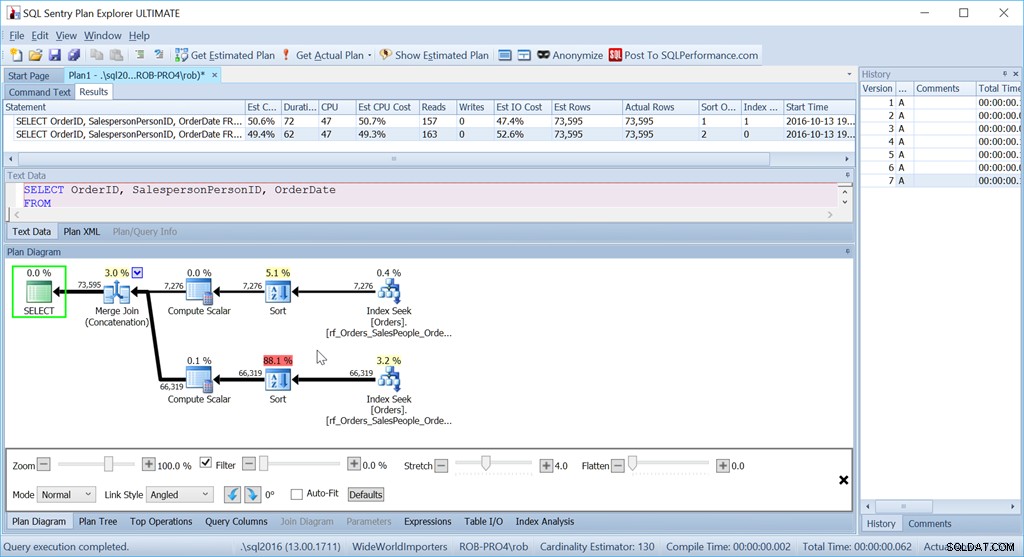
Въпреки че използвах точно същите заявки както преди, моят хубав план вече има два оператора за сортиране и работи почти толкова зле, колкото оригиналната ми версия Scan + Sort.
Причината за това е странност на оператора Merge Join (Concatenation), а уликата е в оператора Sort.

Подрежда се от SalespersonPersonID, последвано от OrderID – който е клъстерираният индексен ключ на таблицата. Той избира това, защото е известно, че това е уникално и е по-малък набор от колони за сортиране от SalespersonPersonID, последвано от OrderDate, последвано от OrderID, което е реда на набора от данни, произведен от три сканирания диапазон на индекси. Един от онези моменти, когато Оптимизаторът на заявки не забелязва по-добра опция, която е точно там.
С този индекс ще ни трябва и нашия набор от данни, подреден по OrderDate, за да създадем предпочитания от нас план.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
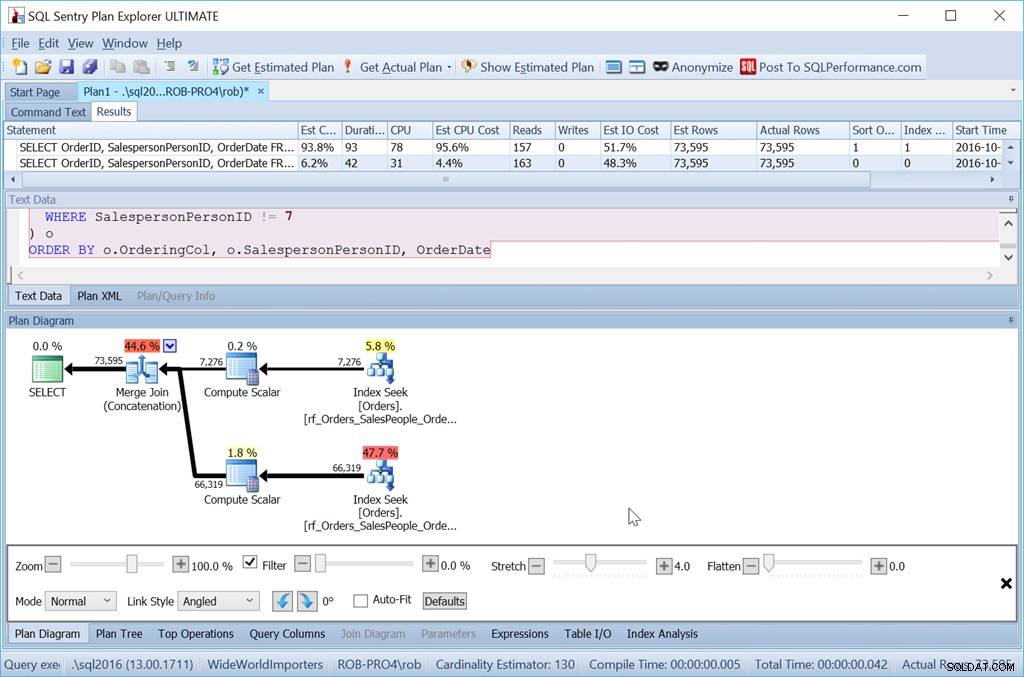
Така че определено е повече усилия. Заявката е по-дълга за писане, тя е повече четения и трябва да имам индекс без допълнителни ключови колони. Но със сигурност е по-бързо. С още повече редове въздействието е още по-голямо и не е нужно да рискувам сортиране да се разлее към tempdb.
За малки набори моят отговор на StackOverflow все още е добър. Но когато този оператор за сортиране ми струва производителността, тогава ще използвам метода Union All / Merge Join (Concatenation).