Индексираните изгледи могат да бъдат създадени във всяко издание на SQL Server, но има редица поведения, които трябва да имате предвид, ако искате да се възползвате максимално от тях.
Автоматичните статистически данни изискват намек за NOEXPAND
SQL Server може автоматично да създава статистически данни, за да подпомогне оценката на мощността и вземането на решения въз основа на разходите по време на оптимизиране на заявката. Тази функция работи с индексирани изгледи, както и с базови таблици, но само ако изгледът е изрично наименуван в заявката и NOEXPAND намек е посочен. (Винаги има статистически обект, свързан с всеки индекс в изглед, това е автоматичното генериране и поддържане на статистически данни, които не са свързани с индекс, за което говорим тук.)
Ако сте свикнали да работите с не-Enterprise издания на SQL Server, може никога да не сте забелязали това поведение преди. По-ниските издания на SQL Server изискват NOEXPAND намек за създаване на план за заявка, който има достъп до индексиран изглед. Когато NOEXPAND е посочено, автоматичните статистически данни се създават за индексирани изгледи точно както се случва с обикновените таблици.
Пример – Стандартно издание с NOEXPAND
Използвайки SQL Server 2012 Standard Edition и примерната база данни Adventure Works, първо създаваме изглед, който съединява две таблици за продажби и изчислява общото количество на поръчката за клиент и продукт:
CREATE VIEW dbo.CustomerOrdersWITH SCHEMABINDING ASSELECT SOH.CustomerID, SOD.ProductID, OrderQty =SUM(SOD.OrderQty), NumRows =COUNT_BIG(*)FROM Sales.SalesOrderDetail КАТО SODJOIN SODJOIN Sales.Sales. .SalesOrderIDGROUP BY SOH.CustomerID, SOD.ProductID;
За да поддържа този изглед статистически данни, трябва да го материализираме, като добавим уникален клъстериран индекс. Комбинацията от клиент и продуктов идентификатор е гарантирано, че е уникална в изгледа (по дефиниция), така че ще използваме това като ключ. Бихме могли да посочим двете колони по всякакъв начин в индекса, но ако приемем, че очакваме повече заявки за филтриране по продукт, ние правим Product ID като водеща колона. Това действие също така създава статистически данни за индекса с хистограма, изградена от стойности на Product ID.
СЪЗДАВАЙТЕ УНИКАЛЕН КЛУСТРИРАН ИНДЕКС cuq В dbo.CustomerOrders (ProductID, CustomerID);
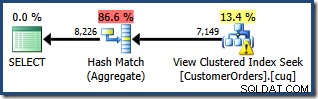
Сега от нас се иска да напишем заявка, която показва общото количество поръчки на клиент за определена гама продукти. Очакваме, че планът за изпълнение, използващ индексирания изглед, ще бъде ефективна стратегия, тъй като ще избегне присъединяване и ще работи с данни, които вече са частично агрегирани. Тъй като използваме SQL Server Standard Edition, трябва да посочим изгледа изрично и да използваме NOEXPAND намек за създаване на план за заявка, който има достъп до индексирания изглед:
ИЗБЕРЕТЕ CO.CustomerID, SUM(CO.OrderQty)ОТ dbo.CustomerOrders КАТО CO С (NOEXPAND), КЪДЕТО CO.ProductID МЕЖДУ 711 И 718GROUP BY CO.CustomerID;
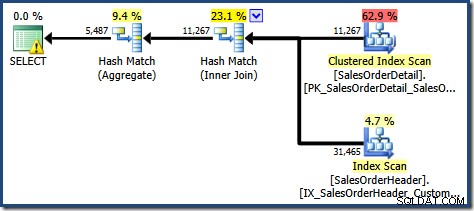
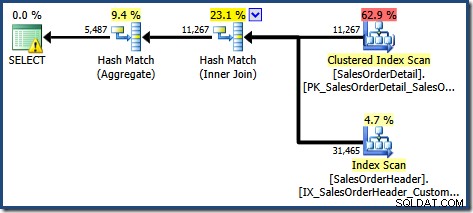
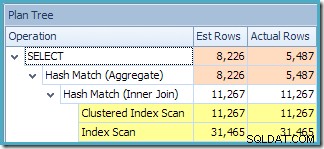
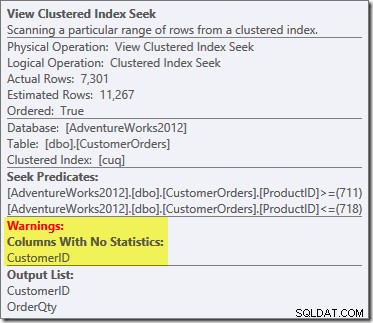
Създаденият план за изпълнение показва търсене в индексирания изглед за намиране на редове за продуктите от интерес, последвано от агрегиране за изчисляване на общото количество на клиент:
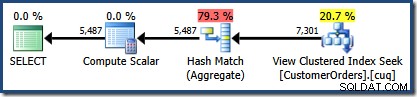
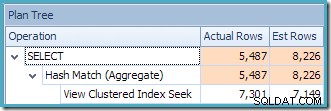
Изгледът на дървото на плановете на SQL Sentry Plan Explorer показва, че оценката на мощността е точно правилна за търсенето на индексиран изглед и е много добра за резултата от агрегата:
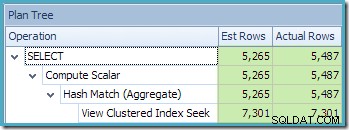
Като част от процеса на компилиране и оптимизиране за тази заявка, SQL Server създаде допълнителен статистически обект в колоната Customer ID на индексирания изглед. Тази статистика е изградена, защото очакваният брой и разпределение на идентификатори на клиенти може да са важни, например при избора на стратегия за агрегиране. Можем да видим новата статистика с помощта на Management Studio Object Explorer:
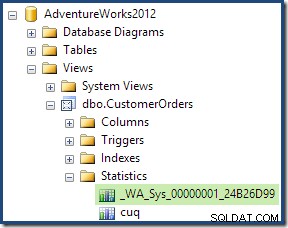
Щракването двукратно върху статистическия обект потвърждава, че е изграден от колоната с идентификатор на клиента в изгледа (не е основна таблица):
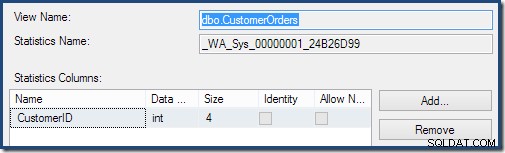
Индексираните изгледи могат да подобрят оценката на кардиналността
Все още използвайки стандартното издание, сега пускаме и пресъздаваме индексирания изглед (който също премахва статистическите данни за изгледа) и изпълняваме заявката отново, този път с NOEXPAND намек е коментиран:
ИЗБЕРЕТЕ CO.CustomerID, SUM(CO.OrderQty)ОТ dbo.CustomerOrders КАТО CO -- С (NOEXPAND) КЪДЕ CO.ProductID МЕЖДУ 711 И 718 GROUP BY CO.CustomerID;
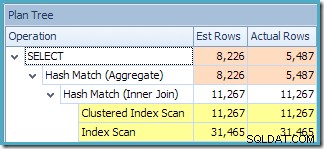
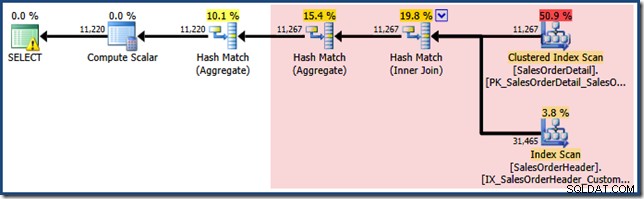
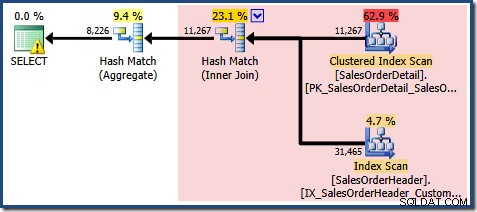
Както се очаква при използване на стандартно издание без NOEXPAND , полученият план за заявка работи върху базовите таблици, а не директно върху изгледа:

Предупредителният триъгълник на основния оператор в плана по-горе ни предупреждава за потенциално полезен индекс в таблицата с подробности за поръчката за продажба, който не е важен за нашите настоящи цели. Тази компилация не създава статистически данни за индексирания изглед. Единствената статистика за изгледа след компилиране на заявка е тази, свързана с клъстерирания индекс:
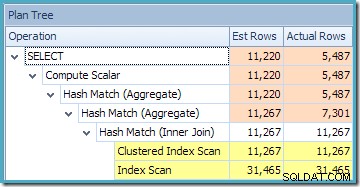
Изгледът на дървото на плановете за заявката показва, че оценката на мощността е правилна за двете сканирания на таблицата и присъединяването, но доста по-лоша за другите оператори на план:
Използване на индексирания изглед с NOEXPAND намек доведе до по-точни оценки за нашата тестова заявка, тъй като информацията с по-добро качество беше налична от статистическите данни за изгледа – по-специално статистическите данни, свързани с индекса на изгледа.
Като общо правило, точността на статистическата информация се влошава доста бързо, докато преминава през нея и се променя от операторите на плана на заявката. Обикновените присъединявания често не са твърде лоши в това отношение, но информацията за резултата от агрегирането често не е по-добра от образовано предположение. Предоставянето на оптимизатора на заявки с по-точна информация, използвайки статистически данни за индексираните изгледи, може да бъде полезна техника за повишаване на качеството и стабилността на плана.
Изглед без NOEXPAND може да доведе до по-нисък план
Планът за заявка, показан по-горе (Стандартно издание, без NOEXPAND ) всъщност е по-малко оптимален, отколкото ако бяхме написали заявката срещу основните таблици сами, вместо да позволим на оптимизатора на заявки да разшири изгледа. Заявката по-долу изразява същото логическо изискване, но не препраща към изгледа:
ИЗБЕРЕТЕ SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID МЕЖДУ 711 И 718C.Тази заявка произвежда следния план за изпълнение:
Този план включва една операция за агрегиране по-малко от преди. Когато беше използвано разширяване на изгледа, оптимизаторът на заявки за съжаление не успя да премахне излишната операция за агрегиране, което доведе до по-малко ефективен план за изпълнение. Окончателната оценка на кардиналитета за новата заявка също е малко по-добра, отколкото когато индексираният изглед е препратен без
NOEXPAND:
Независимо от това, най-добрите оценки все още са тези, получени при препратка към индексирания изглед с
NOEXPAND(повтаря се по-долу за удобство):
Enterprise Edition и съвпадение на изглед
В екземпляр на Enterprise Edition оптимизаторът на заявки може да може да използва индексиран изглед, дори ако заявката не споменава изгледа изрично. Ако оптимизаторът е в състояние да съпостави част от дървото на заявката с индексиран изглед, той може да избере да го направи въз основа на своята оценка на разходите за използване на изгледа или не. Логиката за съпоставяне на изглед е сравнително умна, но има ограничения, които са доста лесни за достигане на практика. Дори когато съвпадението на изгледа е успешно, оптимизаторът все още може да бъде подведен от неточни оценки на разходите.
Съветът за заявка EXPAND VIEWS
Започвайки с по-редките възможности, може да има случаи, в които заявка препраща към индексиран изглед, но по-добър план би бил получен чрез достъп до базовите таблици вместо това. При тези обстоятелства подсказката на заявката
EXPAND VIEWSможе да се използва:ИЗБЕРЕТЕ CO.CustomerID, SUM(CO.OrderQty)ОТ dbo.CustomerOrders КАТО COWHERE CO.ProductID МЕЖДУ 711 И 718ГРУПА ПО CO.CustomerIDOPTION (РАЗГРАЖДАНЕ НА ИЗГЛЕДИТЕ);В Enterprise Edition тази заявка произвежда същия план, както се вижда в Standard Edition, когато
NOEXPANDнамек беше пропуснат (включително операцията за излишно агрегиране):
Като настрана,
EXPAND VIEWSнамекът е лошо наименуван, според мен. SQL Server винаги разширява дефинициите на изглед в заявка, освен акоNOEXPANDнамек е посочен.EXPAND VIEWShint деактивира правила в оптимизатора, които могат да съпоставят части от разширеното дърво обратно към индексирани изгледи. При липса на който и да е намек, SQL Server първо разширява изглед до дефиницията на основната таблица, след което по-късно обмисля съвпадение обратно към индексирани изгледи. По-добро име заEXPAND VIEWSподсказката може да е билаDISABLE INDEXED VIEW MATCHING, защото това прави.
EXPAND VIEWShint вероятно най-често се използва за предотвратяване на съвпадение на заявка към базови таблици с индексиран изглед:ИЗБЕРЕТЕ SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID МЕЖДУ 711 ИЗГЛЕЖДАНЕ НА 711 И 718C.>Подсказката за заявката води до същия план за изпълнение и оценки, наблюдавани, когато използвахме Стандартно издание и същата заявка само за базова таблица:
Съпоставяне и статистика на изглед на предприятия
Дори в Enterprise Edition статистиките за неиндексни изгледи все още се създават само ако
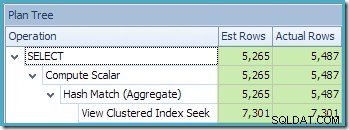
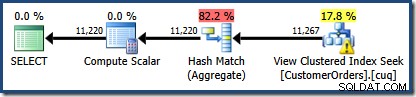
NOEXPANDсе използва подсказка. За да бъде абсолютно ясно, функцията за съпоставяне на изглед само за предприятия никога не води до създаване или актуализиране на статистически данни за изгледите. Това неинтуитивно поведение си струва да се проучи малко, тъй като може да има изненадващи странични ефекти.Сега изпълняваме нашата основна заявка спрямо изгледа на екземпляр на Enterprise Edition, без никакви намеци:
ИЗБЕРЕТЕ CO.CustomerID, SUM(CO.OrderQty)ОТ dbo.CustomerOrders КАТО COWHERE CO.ProductID МЕЖДУ 711 И 718GROUP BY CO.CustomerID;
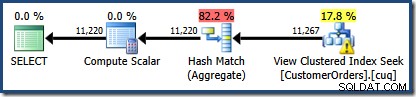
Ново нещо там е предупредителният триъгълник в търсенето на View clustered Index. Подсказката показва подробностите:
Не използвахме
NOEXPANDнамек, така че статистическите данни за колоната ИД на клиента на индексирания изглед не са създадени автоматично. Статистиката за идентификатора на клиента всъщност не е много важна в този опростен пример, но това не винаги ще бъде така.Любопитни оценки на кардиналитета
Второто интересно нещо е, че оценките за кардиналите изглеждат по-лоши от всеки случай, който сме срещали досега, включително примерите за стандартното издание.
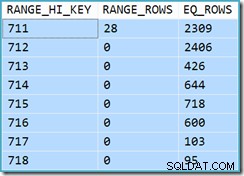
Първоначално е трудно да се види откъде идва оценката за кардиналност за търсенето на клъстериран индекс (11 267). Очакваме оценката да се основава на информация за хистограмата на идентификатора на продукта от статистическите данни, свързани с клъстерирания индекс на изгледа. Съответната част от тази хистограма е показана по-долу:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') С ХИСТОГРАМА;
Като се има предвид, че таблицата не е променена от създаването на статистическите данни, очакваме оценката да бъде проста сума от RANGE_ROWS и EQ_ROWS за стойности на идентификатора на продукта между 711 и 718 (обърнете внимание, че оценката трябва да изключва 28 RANGE_ROWS, показани срещу записа 711 тъй като тези редове съществуват под стойността на ключа 711). Сумата от показаните EQ_ROWS е 7,301. Това е точно броят на редовете, действително върнати от изгледа – така че откъде дойде оценката от 11 267?
Отговорът се крие в начина, по който съпоставянето на изглед работи в момента. Нашата заявка не посочи
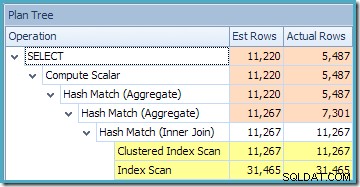
NOEXPANDнамек, така че първоначалните оценки на мощността се базират на дървото на заявката с разширен изглед. Това е най-лесно да видите, като погледнете отново прогнозния план за същата заявка сEXPAND VIEWSпосочено:
Червената засенчена област представлява частта от дървото, която се заменя с дейност за съвпадение на изглед. Изходната мощност от тази област е 11 267. Незащрихованата част с оценката от 11 220 не се влияе от съвпадението на изгледи. Точно това са оценките, които искахме да обясним:
Съвпадението на изглед просто заменя червената засенчена област с логически еквивалентно търсене в индексирания изглед. Той не използва статистическа информация от изгледа за преизчисляване на оценката за мощността.
До известна степен вероятно можете да оцените защо може да работи по този начин:като цяло, няма много причини да очакваме, че оценката, изчислена от един набор от статистическа информация, е по-добра от друга. Може да се направи случай, че статистическите данни за индексираните изгледи е по-вероятно да бъдат точни тук, в сравнение със статистическите данни, получени след присъединяване в червената засенчена област, но може да е трудно да се обобщи това или правилно да се отчете колко бързо различни източници на статистическата информация може да остане остаряла, тъй като основните данни се променят.
Може също да се твърди, че ако бяхме толкова сигурни, че информацията за индексирания изглед е по-добра, щяхме да използваме
NOEXPANDнамек.Още по-любопитни оценки на кардиналността
Още по-интересна ситуация възниква с Enterprise Edition, ако напишем заявката спрямо базовите таблици и разчитаме на автоматично съвпадение на изглед:
ИЗБЕРЕТЕ SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader КАТО SOHJOIN Sales.SalesOrderDetail КАТО SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID МЕЖДУ 711 И 718C.
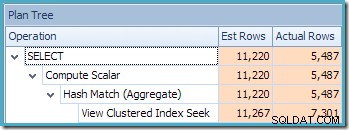
Предупреждението за липсваща статистика е същото като преди и има същото обяснение. По-интересната характеристика е, че сега имаме по-ниска оценка за броя на редовете, произведени от търсенето на клъстериран индекс (7149) и повишена оценка за броя на редовете, върнати от агрегирането (8226).
За да подчертаем смисъла, този план за заявка изглежда се основава на идеята, че 7 149 изходни реда могат да бъдат обобщени, за да се получат 8 226 реда!
Част от обяснението е същото като преди.
EXPAND VIEWSплан на заявка, показващ червения регион, който ще бъде заменен от съвпадение на изглед, е показан по-долу:
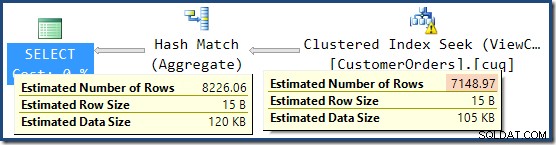
Това обяснява откъде идва крайната оценка от 8 226, но какво ще кажете за оценката за 7 149 реда? Следвайки логиката, видяна по-рано, изглежда, че изгледът трябва да показва приблизително 11 267 реда?
Отговорът е, че оценката от 7 149 е предположение. Да наистина. Индексираният изглед съдържа общо 79 433 реда. Процентът на магическите предположения за предиката Product ID BETWEEN е 9% – дава 0,09 * 79433 =7148,97 реда. Планът за SSMS заявка показва, че това изчисление е точно правилно, дори преди закръгляването:
В тази ситуация изглежда, че оптимизаторът на SQL Server е предпочел предположение, базирано на индексиран изглед, пред оценката за мощност след присъединяване от подмененото поддърво. Любопитно.
Резюме
Използване на
NOEXPANDhint гарантира, че индексиран изглед ще бъде използван в крайния план за заявка и позволява автоматичното създаване, поддържане и използване на неиндексни статистики от оптимизатора на заявки. Използване наNOEXPANDсъщо така гарантира, че първоначалните оценки на мощността се основават на информация за индексиран изглед, а не на извлечени от базови таблици.Ако
NOEXPANDне е посочено, препратките за изглед винаги се заменят с техните дефиниции на основната таблица, преди да започне компилацията на заявката (и следователно преди първоначалната оценка на мощността). Само в Enterprise SKU индексираните изгледи могат да бъдат заменени обратно в дървото на заявките по-късно в процеса на оптимизация.
EXPAND VIEWSнамек за заявка не позволява на оптимизатора да извършва съпоставяне на индексиран изглед на Enterprise Edition. Това се прилага независимо дали заявката първоначално е препращала към индексиран изглед или не. Когато се извърши съпоставяне на изгледи, съществуващата оценка на кардиналитета може да бъде заменена с предположение при някои обстоятелства.Статистическите данни, показани като липсващи в индексиран изглед, могат да бъдат създадени ръчно, но оптимизаторът обикновено няма да ги използва за заявки, които не използват
NOEXPANDнамек.Използването на индексирани изгледи може да подобри оценката на мощността, особено ако изгледът съдържа обединения или агрегирания. Заявките имат най-добрия шанс да се възползват от по-точни статистически данни за преглед, ако
NOEXPANDе посочено.