Разделянето на таблици в SQL Server по същество е начин да направите множество физически таблици (набори от редове) да изглеждат като една таблица. Тази абстракция се извършва изцяло от процесора на заявки, дизайн, който улеснява нещата за потребителите, но прави сложни изисквания на оптимизатора на заявки. Тази публикация разглежда два примера, които надхвърлят възможностите на оптимизатора в SQL Server 2008 нататък.
Поръчката на присъединяване в колона има значение
Този първи пример показва как текстовият ред на ON условията на клаузата могат да повлияят на плана на заявката, създаден при присъединяване на разделени таблици. За начало имаме нужда от схема за разделяне, функция за разделяне и две таблици:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); След това зареждаме и двете таблици със 150 000 реда. Данните нямат голямо значение; този пример използва стандартна таблица с числа, съдържаща всички цели числа от 1 до 150 000 като източник на данни. И двете таблици са заредени с едни и същи данни.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Нашата тестова заявка извършва просто вътрешно свързване на тези две таблици. Отново, заявката не е важна или е предназначена да бъде особено реалистична, тя се използва за демонстриране на странен ефект при присъединяване на разделени таблици. Първата форма на заявката използва ON клауза, написана в реда на колоните c3, c2, c1:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Планът за изпълнение, създаден за тази заявка (на SQL Server 2008 и по-нови версии) включва паралелно хеш присъединяване с приблизителна цена от 2,6953 :
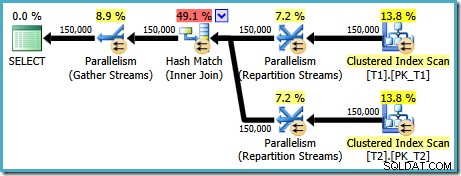
Това е малко неочаквано. И двете таблици имат клъстериран индекс в (c1, c2, c3) ред, разделен на c1, така че бихме очаквали обединяване за сливане, като се възползваме от подреждането на индексите. Нека се опитаме да напишем ON клауза в (c1, c2, c3) ред вместо това:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Планът за изпълнение вече използва очакваното обединяване при сливане с прогнозна цена от 1,64119 (надолу от 2,6953 ). Оптимизаторът също така решава, че не си струва да се използва паралелно изпълнение:
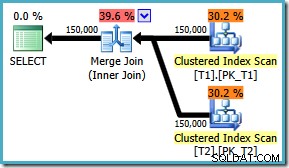
Отбелязвайки, че планът за обединяване на сливане е очевидно по-ефективен, можем да се опитаме да принудим присъединяване за сливане за оригиналния ON подреждане на клаузите с помощта на намек за заявка:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Полученият план наистина използва обединяване за сливане, както е поискано, но също така включва сортиране на двата входа и се връща към използването на паралелизъм. Прогнозната цена на този план е огромните 8,71063 :
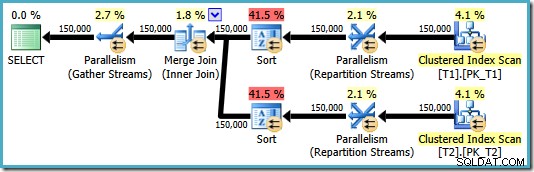
И двата оператора за сортиране имат едни и същи свойства:
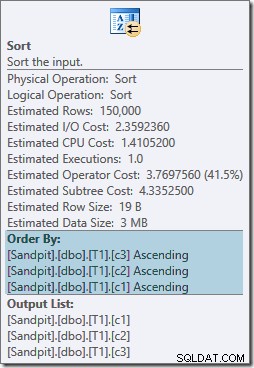
Оптимизаторът смята, че присъединяването за сливане се нуждае от своите входове, сортирани в стриктния писмен ред на ON клауза, като в резултат се въвеждат изрични сортове. Оптимизаторът е наясно, че обединяването на сливане изисква входните данни да бъдат сортирани по същия начин, но също така знае, че редът на колоните няма значение. Обединяването при сливане на (c1, c2, c3) е еднакво доволен от входовете, сортирани по (c3, c2, c1), както и с входовете, сортирани по (c2, c1, c3) или всяка друга комбинация.
За съжаление, това разсъждение е нарушено в оптимизатора на заявки, когато се включва разделяне. Това е бъг на оптимизатора това е коригирано в SQL Server 2008 R2 и по-нови, въпреки че флагът за проследяване 4199 е необходимо за активиране на корекцията:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Обикновено бихте активирали този флаг за проследяване с помощта на DBCC TRACEON или като опция за стартиране, защото QUERYTRACEON намекът не е документиран за използване с 4199. Флагът за проследяване е необходим в SQL Server 2008 R2, SQL Server 2012 и SQL Server 2014 CTP1.
Както и да е, когато флагът е активиран, заявката сега произвежда оптималното присъединяване за сливане, независимо от ON подреждане на клаузите:
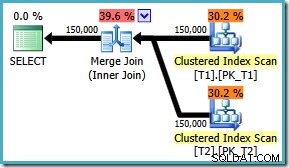
Няма поправка за SQL Server 2008 , решението е да напишете ON клауза в „правилния“ ред! Ако срещнете заявка като тази в SQL Server 2008, опитайте да принудите обединяване за сливане и погледнете сортовете, за да определите „правилния“ начин да напишете ON на вашата заявка клауза.
Този проблем не възниква в SQL Server 2005, тъй като тази версия реализира разделени заявки с помощта на APPLY модел:

Планът за заявки на SQL Server 2005 се присъединява към един дял от всяка таблица в даден момент, като използва таблица в паметта (Constant Scan), съдържаща номера на дялове за обработка. Всеки дял е свързан чрез сливане отделно от вътрешната страна на съединението и оптимизаторът 2005 е достатъчно умен, за да види, че ON Редът на колоните с клауза няма значение.
Този последен план е пример за колокирано присъединяване за сливане , съоръжение, което беше загубено при преминаване от SQL Server 2005 към новата реализация на разделяне в SQL Server 2008. Предложението относно Свързване за възстановяване на колокирани обединявания за сливане беше затворено като няма да се поправи.
Групиране по поръчка има значение
Втората особеност, която искам да разгледам, следва подобна тема, но е свързана с реда на колоните в GROUP BY клауза, а не ON клауза за вътрешно присъединяване. Ще ни трябва нова таблица, за да демонстрираме:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Таблицата има подравнен неклъстериран индекс, където „подравнено“ просто означава, че е разделена по същия начин като клъстерирания индекс (или хеп):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Нашата тестова заявка групира данни в трите неклъстерирани индексни колони и връща брой за всяка група:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Планът на заявката сканира неклъстерирания индекс и използва агрегат за съвпадение на хеш за преброяване на редове във всяка група:
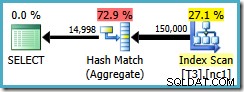
Има два проблема с Hash Aggregate:
- Това е блокиращ оператор. Не се връщат редове на клиента, докато всички редове не бъдат агрегирани.
- Изисква предоставяне на памет, за да държи хеш таблицата.
В много реални сценарии ние бихме предпочели Stream Aggregate тук, защото този оператор блокира само за група и не изисква предоставяне на памет. Използвайки тази опция, клиентското приложение ще започне да получава данни по-рано, няма да се налага да чака предоставянето на памет, а SQL Server може да използва паметта за други цели.
Можем да изискваме от оптимизатора на заявки да използва Stream Aggregate за тази заявка, като добавим OPTION (ORDER GROUP) намек за заявка. Това води до следния план за изпълнение:

Операторът Sort е напълно блокиран и също така изисква предоставяне на памет, така че този план изглежда по-лош от простото използване на хеш агрегат. Но защо е необходим сортът? Свойствата показват, че редовете се сортират в реда, определен от нашия GROUP BY клауза:
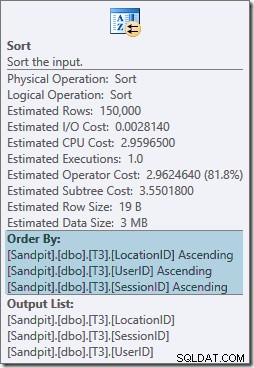
Този сорт се очаква тъй като подравняването на индекса на дял (в SQL Server 2008 нататък) означава, че номерът на дяла се добавя като водеща колона на индекса. Всъщност неклъстерираните индексни ключове (раздел, потребител, сесия, местоположение) се дължат на разделянето. Редовете в индекса все още се сортират по потребител, сесия и местоположение, но само във всеки дял.
Ако ограничим заявката до един дял, оптимизаторът би трябвало да може да използва индекса за захранване на Stream Aggregate без сортиране. В случай, че това изисква някакво обяснение, посочването на един дял означава, че планът на заявката може да елиминира всички други дялове от неклъстерното индексно сканиране, което води до поток от редове, който е подреден по (потребител, сесия, местоположение).
Можем да постигнем това елиминиране на дял изрично с помощта на $PARTITION функция:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
За съжаление, тази заявка все още използва Hash Aggregate с прогнозна цена на плана от 0,287878 :
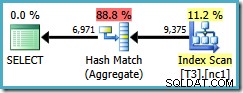
Сканирането вече е малко над един дял, но подреждането (потребител, сесия, местоположение) не е помогнало на оптимизатора да използва Stream Aggregate. Може да възразите, че подреждането (потребител, сесия, местоположение) не е полезно, защото GROUP BY клаузата е (местоположение, потребител, сесия), но редът на ключовете няма значение за операция за групиране.
Нека добавим ORDER BY клауза в реда на индексните ключове за доказване на точката:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Обърнете внимание, че ORDER BY клаузата съвпада с неклъстерирания индексен ключов ред, въпреки че GROUP BY клаузата не. Планът за изпълнение на тази заявка е:
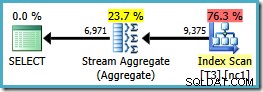
Сега имаме Stream Aggregate, който търсехме, с прогнозна цена на плана от 0,0423925 (в сравнение с 0,287878 за плана Hash Aggregate – почти 7 пъти повече).
Другият начин за постигане на поток Aggregate тук е да пренаредите GROUP BY колони, за да съответстват на неклъстерираните индексни ключове:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Тази заявка произвежда същия план за поток от агрегати, показан непосредствено по-горе, с точно същата цена. Тази чувствителност към GROUP BY реда на колоните е специфичен за заявките за разделени таблици в SQL Server 2008 и по-нови версии.
Може да разпознаете, че основната причина за проблема тук е подобна на предишния случай, включващ Merge Join. Както Merge Join, така и Stream Aggregate изискват вход, сортиран по ключовете за свързване или агрегиране, но нито един от тях не се интересува от реда на тези ключове. Обединяването при сливане на (x, y, z) е също толкова щастливо, когато получавате редове, подредени по (y, z, x) или (z, y, x), и същото важи за Stream Aggregate.
Това ограничение на оптимизатора важи и за DISTINCT при същите обстоятелства. Следната заявка води до план Hash Aggregate с прогнозна цена от 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
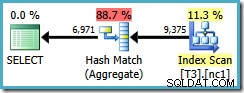
Ако напишем DISTINCT колони в реда на неклъстерираните индексни ключове...
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
... ние сме възнаградени с план Stream Aggregate с цена от 0,041455 :

За да обобщим, това е ограничение на оптимизатора на заявки в SQL Server 2008 и по-нови (включително SQL Server 2014 CTP 1), което не е разрешено чрез използване на флаг за проследяване 4199 какъвто беше случаят с примера на Merge Join. Проблемът възниква само при разделени таблици с GROUP BY или DISTINCT над три или повече колони с помощта на подравнен разделен индекс, където се обработва един дял.
Както при примера на Merge Join, това представлява стъпка назад от поведението на SQL Server 2005. SQL Server 2005 не добави подразбиращ се водещ ключ към разделени индекси, използвайки APPLY вместо това техника. В SQL Server 2005 всички заявки, представени тук, използват $PARTITION за да посочите единичен дял, резултат в планове на заявка, който извършва елиминиране на дял и използва Stream Aggregates без пренареждане на текста на заявката.
Промените в обработката на разделени таблици в SQL Server 2008 подобриха производителността в няколко важни области, предимно свързани с ефективната паралелна обработка на дяловете. За съжаление, тези промени имаха странични ефекти, които не всички бяха разрешени в по-късните версии.



