SQL Server традиционно се отдръпва от предоставянето на естествени решения за някои от по-често срещаните статистически въпроси, като например изчисляване на медиана. Според WikiPedia "медианата се описва като числова стойност, разделяща горната половина на извадка, популация или вероятностно разпределение от долната половина. Медианата на краен списък от числа може да бъде намерена чрез подреждане на всички наблюдения от от най-ниската стойност до най-високата стойност и избирането на средната. Ако има четен брой наблюдения, тогава няма единична средна стойност; тогава медианата обикновено се дефинира като средна стойност от двете средни стойности."
По отношение на заявка на SQL Server, ключовото нещо, което ще вземете от това, е, че трябва да „подредите“ (сортирате) всички стойности. Сортирането в SQL Server обикновено е доста скъпа операция, ако няма поддържащ индекс, а добавянето на индекс за поддръжка на операция, която вероятно не се изисква, често може да не си струва.
Нека да разгледаме как обикновено сме решавали този проблем в предишни версии на SQL Server. Първо нека създадем много проста таблица, така че да можем да видим, че нашата логика е правилна и да изведем точна медиана. Можем да тестваме следните две таблици, едната с четен брой редове, а другата с нечетен брой редове:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Само от случайно наблюдение можем да видим, че медианата за таблицата с нечетни редове трябва да бъде 6, а за четната таблица трябва да бъде 7,5 ((6+9)/2). Така че сега нека видим някои решения, които са били използвани през годините:
SQL Server 2000
В SQL Server 2000 бяхме ограничени до много ограничен T-SQL диалект. Проучвам тези опции за сравнение, защото някои хора все още използват SQL Server 2000, а други може да са надстроили, но тъй като средните им изчисления са написани „в миналото“, кодът може да изглежда така и днес.
2000_A – максимум едната половина, мин. другата
Този подход взема най-високата стойност от първите 50 процента, най-ниската стойност от последните 50 процента, след което ги разделя на две. Това работи за четни или нечетни редове, тъй като в четен случай двете стойности са двата средни реда, а в нечетния случай двете стойности всъщност са от един и същи ред.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #temp таблица
Този пример първо създава #temp таблица и използвайки същия тип математика, както по-горе, определя двата "средни" реда с помощта на последователен IDENTITY колона, подредена от колоната val. (Редът на присвояване на IDENTITY на стойности може да се разчита само поради MAXDOP настройка.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 въведе някои интересни нови функции на прозореца, като ROW_NUMBER() , което може да помогне за решаването на статистически проблеми като медиана малко по-лесно, отколкото бихме могли в SQL Server 2000. Всички тези подходи работят в SQL Server 2005 и по-нова версия:
2005_A – номера на редовете за дуел
Този пример използва ROW_NUMBER() за да преминете нагоре и надолу стойностите веднъж във всяка посока, след което намира "средните" един или два реда въз основа на това изчисление. Това е доста подобно на първия пример по-горе, с по-лесен синтаксис:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – номер на ред + брой
Този е доста подобен на горния, като се използва едно изчисление на ROW_NUMBER() и след това с помощта на общия COUNT() за да намерите "средните" един или два реда:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – вариация на номер на ред + брой
Колегата MVP Ицик Бен-Ган ми показа този метод, който постига същия отговор като горните два метода, но по много малко по-различен начин:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
В SQL Server 2012 имаме нови възможности за прозорец в T-SQL, които позволяват статистическите изчисления като медиана да бъдат изразени по-директно. За да изчислим медианата за набор от стойности, можем да използваме PERCENTILE_CONT() . Можем също така да използваме новото разширение „пейджинг“ към ORDER BY клауза (OFFSET / FETCH ).
2012_A – нова функционалност за разпространение
Това решение използва много просто изчисление чрез разпределение (ако не искате средната стойност между двете средни стойности в случай на четен брой редове).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – пейджинг трик
Този пример реализира умно използване на OFFSET / FETCH (и не точно такъв, за който е предназначен) – просто преминаваме към реда, който е един преди половината от броя, след което вземаме следващите един или два реда в зависимост от това дали броят е нечетен или четен. Благодаря на Itzik Ben-Gan, че посочи този подход.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Но кое се представя по-добре?
Потвърдихме, че всички горни методи дават очакваните резултати на нашата малка маса и знаем, че версията на SQL Server 2012 има най-чистия и логичен синтаксис. Но коя трябва да използвате във вашата натоварена производствена среда? Можем да изградим много по-голяма таблица от системни метаданни, като се уверим, че имаме много дублиращи се стойности. Този скрипт ще създаде таблица с 10 000 000 неуникални цели числа:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
В моята система медианата за тази таблица трябва да бъде 146 099 561. Мога да изчисля това доста бързо без ръчна проверка на място от 10 000 000 реда, като използвам следната заявка:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Резултати:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Така че сега можем да създадем съхранена процедура за всеки метод, да проверим дали всеки от тях произвежда правилния изход и след това да измерваме показатели за производителност като продължителност, процесор и четене. Ще изпълним всички тези стъпки със съществуващата таблица, а също и с копие на таблицата, което не се възползва от клъстерирания индекс (ще го пуснем и ще създадем отново таблицата като купчина).
Създадох седем процедури, прилагащи методите на заявка по-горе. За краткост няма да ги изброявам тук, но всеки от тях се казва dbo.Median_<version> , напр. dbo.Median_2000_A , dbo.Median_2000_B , и др., съответстващи на описаните по-горе подходи. Ако изпълним тези седем процедури с помощта на безплатния SQL Sentry Plan Explorer, ето какво наблюдаваме по отношение на продължителност, процесор и четене (обърнете внимание, че изпълняваме DBCC FREEPROCCACHE и DBCC DROPCLEANBUFFERS между изпълненията):
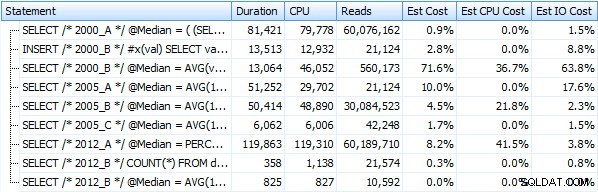
И тези показатели изобщо не се променят много, ако вместо това работим срещу купчина. Най-голямата процентна промяна беше методът, който все пак се оказа най-бързият:трикът за пейджинг с помощта на OFFSET / FETCH:
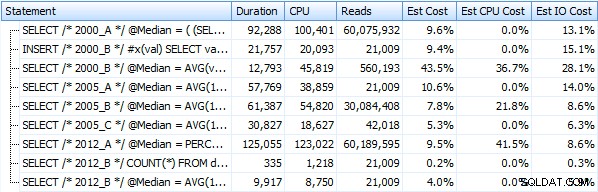
Ето графично представяне на резултатите. За да стане по-ясно, маркирах най-бавния изпълнител в червено и най-бързия подход в зелено.
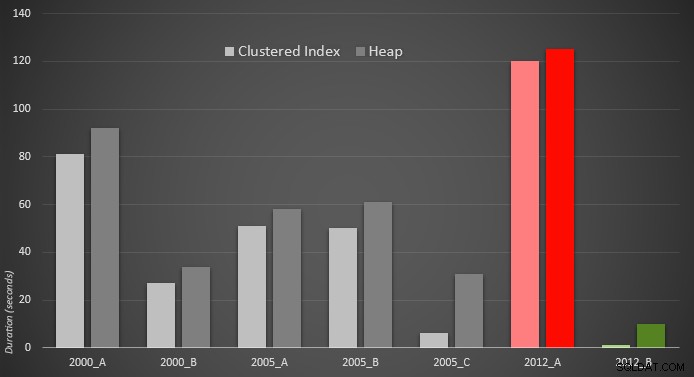
Бях изненадан да видя, че и в двата случая PERCENTILE_CONT() – който е проектиран за този тип изчисления – всъщност е по-лош от всички други по-ранни решения. Предполагам, че това просто показва, че макар понякога по-нов синтаксис да улесни кодирането ни, това не винаги гарантира, че производителността ще се подобри. Също така бях изненадан да видя OFFSET / FETCH се оказва толкова полезен в сценарии, които обикновено не отговарят на целта му – пагинация.
Във всеки случай, надявам се, че съм демонстрирал кой подход трябва да използвате, в зависимост от вашата версия на SQL Server (и че изборът трябва да бъде същият, независимо дали имате поддържащ индекс за изчислението или не).