SQL Server 2005 добави възможността за включване на неключови колони в неклъстериран индекс. В SQL Server 2000 и по-рано, за неклъстериран индекс, всички колони, дефинирани за индекс, бяха ключови колони, което означаваше, че са част от всяко ниво на индекса, от основното надолу до нивото на листа. Когато колона е дефинирана като включена колона, тя е част само от нивото на листа. Books Online отбелязва следните предимства на включените колони:
- Те могат да бъдат типове данни, които не са разрешени като колони с индексни ключови колони.
- Те не се вземат предвид от Database Engine при изчисляване на броя на колоните на индексния ключ или на размера на ключа на индекса.
Например колона varchar(max) не може да бъде част от индексен ключ, но може да бъде включена колона. Освен това тази колона varchar(max) не се отчита срещу ограничението от 900 байта (или 16 колони), наложено за индексния ключ.
Документацията също така отбелязва следното предимство на производителността:
Индекс с неключови колони може значително да подобри производителността на заявката, когато всички колони в заявката са включени в индекса като ключови или неключови колони. Повишаването на производителността се постига, защото оптимизаторът на заявки може да локализира всички стойности на колоните в индекса; не се осъществява достъп до данни от таблица или клъстерен индекс, което води до по-малко операции за вход/изход на диска.Можем да заключим, че независимо дали колоните на индекса са ключови колони или неключови колони, получаваме подобрение в производителността в сравнение с това, когато всички колони не са част от индекса. Но има ли разлика в производителността между двата варианта?
Настройката
Инсталирах копие на базата данни AdventuresWork2012 и проверих индексите за таблицата Sales.SalesOrderHeader, използвайки версията на Kimberly Tripp на sp_helpindex:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Индекси по подразбиране за Sales.SalesOrderHeader
Ще започнем с директна заявка за тестване, която извлича данни от множество колони:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Ако изпълним това срещу базата данни AdventureWorks2012 с помощта на SQL Sentry Plan Explorer и проверим плана и изхода за вход/изход на таблица, виждаме, че получаваме клъстерно сканиране на индекс с 689 логически четения:
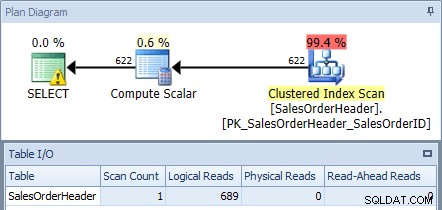
План за изпълнение от оригиналната заявка
(В Management Studio можете да видите показателите за I/O, като използвате SET STATISTICS IO ON; .)
SELECT има икона за предупреждение, защото оптимизаторът препоръчва индекс за тази заявка:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Тест 1
Първо ще създадем индекса, който оптимизаторът препоръчва (наречен NCI1_included), както и варианта с всички колони като ключови колони (с име NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Ако изпълним отново оригиналната заявка, след като го намекнем с NCI1 и веднъж го намекнем с NCI1_included, виждаме план, подобен на оригинала, но този път има търсене на индекс за всеки неклъстериран индекс, с еквивалентни стойности за таблица I/ O и подобни разходи (и двете около 0,006):
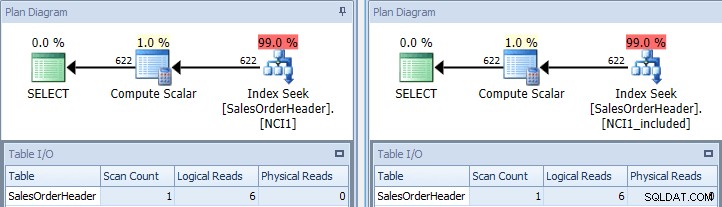
Оригинална заявка с търсене на индекс – ключ вляво, включване на дясно
(Броят на сканирането все още е 1, защото търсенето на индекс всъщност е скрито сканиране на диапазон.)
Сега базата данни AdventureWorks2012 не е представителна за производствена база данни по отношение на размера и ако погледнем броя на страниците във всеки индекс, виждаме, че са абсолютно еднакви:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
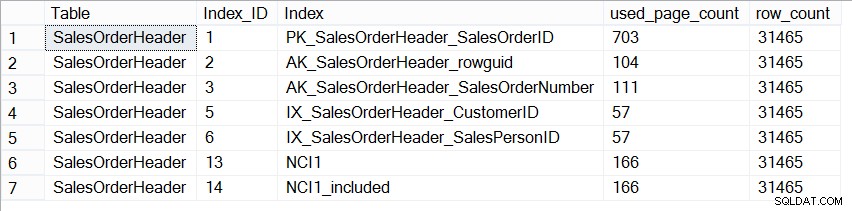
Размер на индексите в Sales.SalesOrderHeader
Ако разглеждаме производителността, идеално (и по-забавно) е да тествате с по-голям набор от данни.
Тест 2
Имам копие на базата данни AdventureWorks2012, която има таблица SalesOrderHeader с над 200 милиона реда (скрипт ТУК), така че нека създадем същите неклъстерирани индекси в тази база данни и да изпълним отново заявките:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
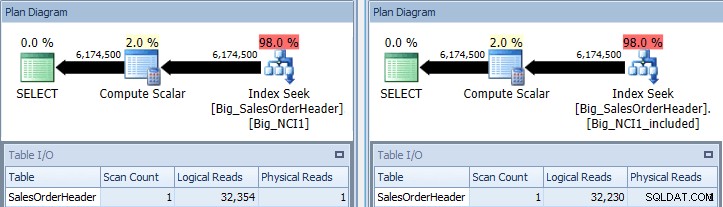
Оригинална заявка с търсене на индекс срещу Big_NCI1 (l) и Big_NCI1_Included ( r)
Сега получаваме някои данни. Заявката връща над 6 милиона реда и търсенето на всеки индекс изисква малко над 32 000 четения, а прогнозната цена е една и съща и за двете заявки (31,233). Все още няма разлики в производителността и ако проверим размера на индексите, виждаме, че индексът с включените колони има 5578 страници по-малко:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Размер на индексите на Sales.Big_SalesOrderHeader
Ако се задълбочим в това и проверим dm_dm_index_physical_stats, можем да видим, че разликата съществува в междинните нива на индекса:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
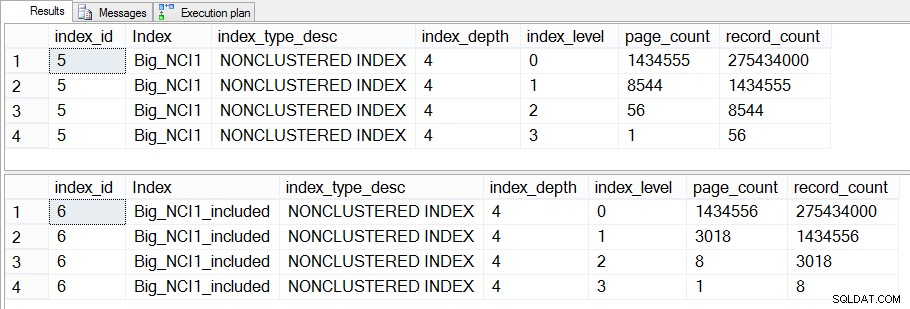
Размер на индексите (специфични за ниво) на Sales.Big_SalesOrderHeader
Разликата между междинните нива на двата индекса е 43 MB, което може да не е съществено, но вероятно все пак бих бил склонен да създам индекса с включени колони, за да спестя място – както на диска, така и в паметта. От гледна точка на заявката все още не виждаме голяма промяна в производителността между индекса с всички колони в ключа и индекса с включените колони.
Тест 3
За този тест нека променим заявката и добавим филтър за [SubTotal] >= 100 към клаузата WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
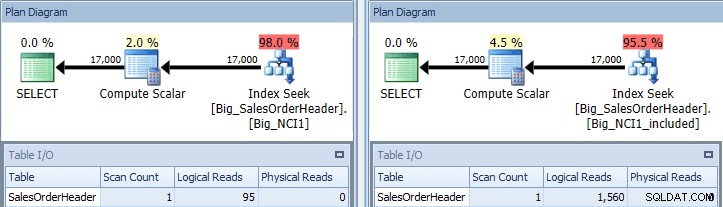
План за изпълнение на заявка с предикат SubTotal спрямо двата индекса
Сега виждаме разлика в I/O (95 прочитания срещу 1560), цената (0,848 срещу 1,55) и фина, но забележителна разлика в плана на заявката. Когато използвате индекса с всички колони в ключа, предикатът за търсене е CustomerID и SubTotal:
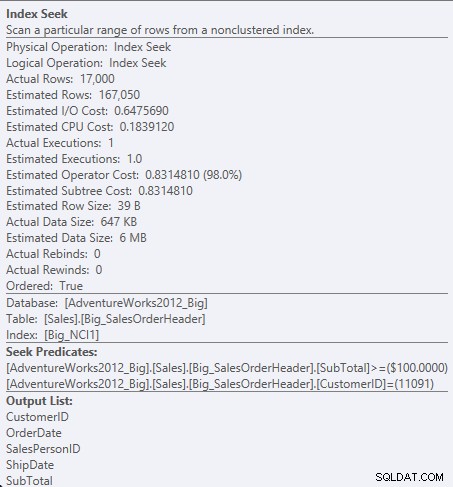
Търсете предикат срещу NCI1
Тъй като SubTotal е втората колона в ключа на индекса, данните са подредени и SubTotal съществува в междинните нива на индекса. Машината може да търси директно към първия запис с CustomerID от 11091 и SubTotal, по-голям или равен на 100, и след това да прочете индекса, докато не съществуват повече записи за CustomerID 11091.
За индекса с включените колони SubTotal съществува само в крайното ниво на индекса, така че CustomerID е предикатът за търсене, а SubTotal е остатъчен предикат (току-що посочен като Предикат на екранната снимка):
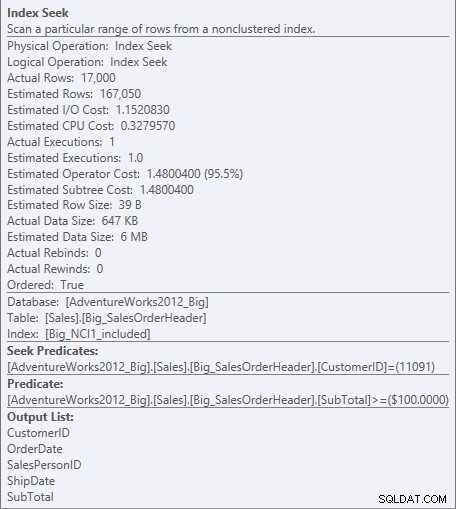
Търсете предикат и остатъчен предикат срещу NCI1_included
Машината може да търси директно към първия запис, където CustomerID е 11091, но след това трябва да преглежда всеки Запишете за CustomerID 11091, за да видите дали SubTotal е 100 или по-висока, тъй като данните са подредени от CustomerID и SalesOrderID (ключ за клъстериране).
Тест 4
Ще опитаме още един вариант на нашата заявка и този път ще добавим ORDER BY:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
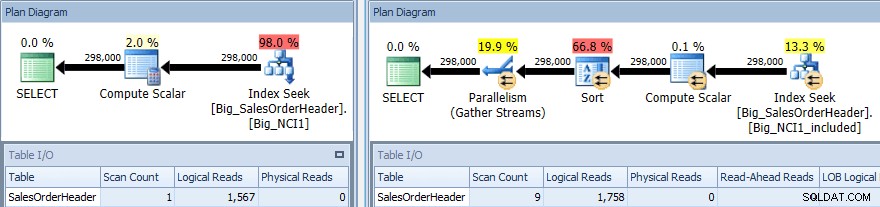
План за изпълнение на заявка със SORT спрямо двата индекса
Отново имаме промяна в I/O (макар и много лека), промяна в цената (1,5 срещу 9,3) и много по-голяма промяна във формата на плана; виждаме и по-голям брой сканирания (1 срещу 9). Заявката изисква данните да бъдат сортирани по SubTotal; когато SubTotal е част от индексния ключ, той се сортира, така че когато записите за CustomerID 11091 бъдат извлечени, те вече са в заявения ред.
Когато SubTotal съществува като включена колона, записите за CustomerID 11091 трябва да бъдат сортирани, преди да могат да бъдат върнати на потребителя, следователно оптимизаторът включва оператор за сортиране в заявката. В резултат на това заявката, която използва индекса Big_NCI1_included, също изисква (и се дава) предоставяне на памет от 29 312 KB, което е забележително (и се намира в свойствата на плана).
Резюме
Първоначалният въпрос, на който искахме да отговорим, беше дали ще видим разлика в производителността, когато една заявка използва индекса с всички колони в ключа, спрямо индекса с повечето колони, включени в нивото на листа. В първия ни набор от тестове нямаше разлика, но в третия и четвъртия тест имаше. В крайна сметка зависи от заявката. Разгледахме само два варианта – единият имаше допълнителен предикат, другият имаше ORDER BY – съществуват много повече.
Това, което разработчиците и администраторите на данни трябва да разберат, е, че има някои големи ползи от включването на колони в индекс, но те не винаги ще работят по същия начин като индексите, които имат всички колони в ключа. Може да е изкушаващо да преместите колони, които не са част от предикати и съединения, извън ключа и просто да ги включите, за да намалите общия размер на индекса. В някои случаи обаче това изисква повече ресурси за изпълнение на заявка и може да влоши производителността. Деградацията може да е незначителна; може и да не е...няма да разберете, докато не тествате. Ето защо, когато проектирате индекс, е важно да помислите за колоните след водещия – и да разберете дали те трябва да бъдат част от ключа (например защото запазването на подредените данни ще осигури полза) или могат да служат на целта си, както са включени колони.
Както е типично при индексирането в SQL Server, трябва да тествате заявките си с вашите индекси, за да определите най-добрата стратегия. Това си остава изкуство и наука – опитвайки се да намерим минималния брой индекси, за да задоволим възможно най-много заявки.