В скорошна нишка на StackExchange, потребител имаше следния проблем:
Искам заявка, която връща първото лице в таблицата с GroupID =2. Ако не съществува никой с GroupID =2, искам първия човек с RoleID =2.
Нека отхвърлим засега факта, че „първият“ е ужасно дефиниран. Всъщност потребителят не се интересуваше кой човек ще получи, дали идва на случаен принцип, произволно или чрез някаква изрична логика в допълнение към основните им критерии. Като игнорираме това, да приемем, че имате основна таблица:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
В реалния свят вероятно има други колони, допълнителни ограничения, може би външни ключове към други таблици и със сигурност други индекси. Но нека да го простим и да излезем със заявка.
Вероятни решения
С този дизайн на масата, решаването на проблема изглежда лесно, нали? Първият опит, който вероятно бихте направили, е:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Това използва TOP и условен ORDER BY да третира тези потребители с GroupID =2 като по-висок приоритет. Планът за тази заявка е доста прост, като по-голямата част от разходите се случват в операция за сортиране. Ето показателите по време на изпълнение спрямо празна таблица:
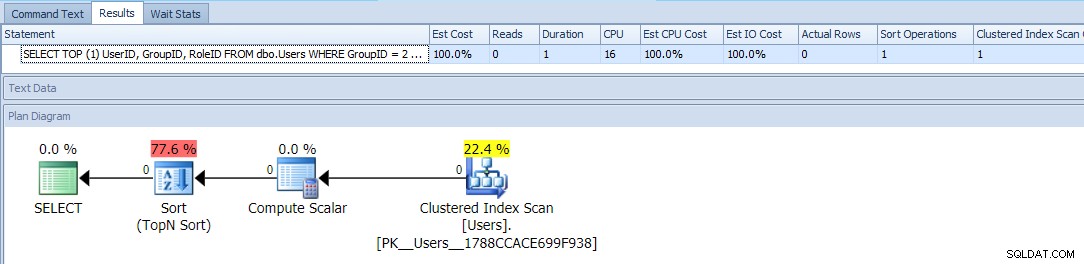
Това изглежда е толкова добро, колкото можете да направите – прост план, който сканира таблицата само веднъж и различен от досаден сорт, с който би трябвало да можете да живеете, няма проблем, нали?
Е, друг отговор в темата предлага този по-сложен вариант:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
На пръв поглед вероятно бихте помислили, че тази заявка е изключително по-малко ефективна, тъй като изисква две клъстерирани сканирания на индекса. Определено ще бъдете прав за това; ето показателите за план и време на изпълнение срещу празна таблица:
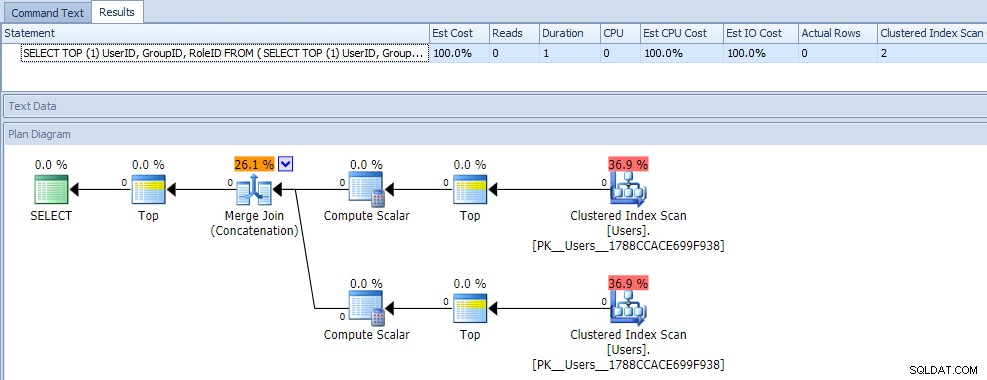
Но сега нека добавим данни
За да тествам тези заявки, исках да използвам някои реалистични данни. Така че първо попълних 1000 реда от sys.all_objects, с модулни операции срещу object_id, за да получа някакво прилично разпределение:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Сега, когато стартирам двете заявки, ето показателите по време на изпълнение:

Версията UNION ALL се предлага с малко по-малко I/O (4 четения срещу 5), по-ниска продължителност и по-ниски прогнозни общи разходи, докато условната версия ORDER BY има по-ниска прогнозна цена на процесора. Данните тук са доста малки, за да се направят някакви заключения; Просто го исках като кол в земята. Сега нека променим разпределението, така че повечето редове да отговарят на поне един от критериите (а понякога и двата):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Този път условната поръчка от има най-високите прогнозни разходи както за процесора, така и за I/O:

Но отново, при този размер на данните има относително незначително въздействие върху продължителността и четенията и освен прогнозните разходи (които така или иначе до голяма степен са компенсирани), тук е трудно да се обяви победител.
И така, нека добавим още много данни
Макар че предпочитам да създавам примерни данни от изгледите на каталога, тъй като всеки има такива, този път ще начертая върху таблицата Sales.SalesOrderHeaderEnlarged от AdventureWorks2012, разширена с помощта на този скрипт от Джонатан Кехайяс. В моята система тази таблица има 1 258 600 реда. Следният скрипт ще вмъкне милион от тези редове в нашата таблица dbo.Users:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Добре, сега, когато стартираме заявките, виждаме проблем:вариантът ORDER BY е минал паралелно и е заличил както четенията, така и CPU, което дава почти 120X разлика в продължителността:
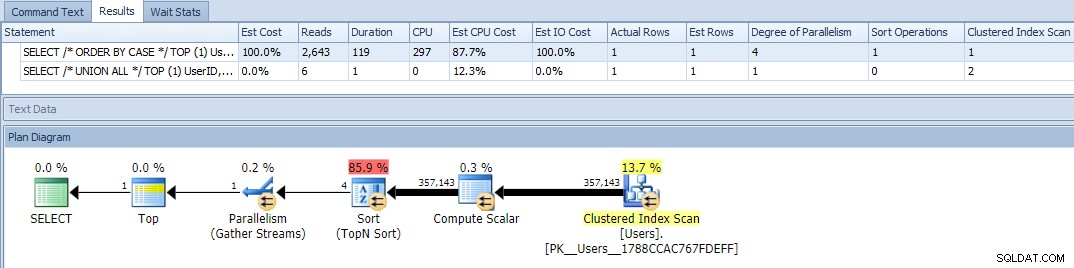
Премахването на паралелизъм (с помощта на MAXDOP) не помогна:
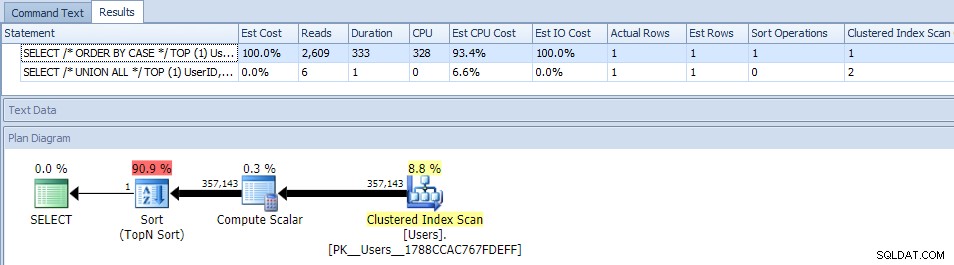
(Планът UNION ALL все още изглежда същият.)
И ако променим изкривяването на четно, където 95% от редовете отговарят на поне един критерий:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Запитванията все още показват, че сортирането е твърде скъпо:

А с MAXDOP =1 беше много по-лошо (само вижте продължителността):

И накрая, какво ще кажете за 95% изкривяване в двете посоки (например повечето редове отговарят на критериите за GroupID или повечето редове отговарят на критериите за RoleID)? Този скрипт ще гарантира, че поне 95% от данните имат GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Резултатите са доста сходни (отсега нататък ще спра да опитвам нещото MAXDOP):

И тогава, ако изкривим по друг начин, където поне 95% от данните имат RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Резултати:

Заключение
В нито един случай, който бих могъл да произведа, „по-простата“ заявка ORDER BY – дори с едно сканиране на индекси с по-малко клъстери – превъзхождаше по-сложната заявка UNION ALL. Понякога трябва да сте много внимателни какво трябва да направи SQL Server, когато въвеждате операции като сортиране в семантиката на заявката си, и да не разчитате само на простотата на плана (няма значение каквито и да било пристрастия, които може да имате въз основа на предишни сценарии).
Първият ви инстинкт често може да е правилен, но се обзалагам, че има моменти, когато има по-добър вариант, който изглежда, на повърхността, сякаш не би могъл да работи по-добре. Както в този пример. Ставам доста по-добре да поставям под въпрос предположенията, които съм направил от наблюдения, и да не правя общи изявления като „сканирането никога не работи добре“ и „по-простите заявки винаги се изпълняват по-бързо“. Ако премахнете думите никога и винаги от речника си, може да се окажете, че подлагате на изпитание повече от тези предположения и общи твърдения и в крайна сметка ще се окажете много по-добре.