Данните вероятно са един от най-ценните активи в една компания. Поради това винаги трябва да имаме план за възстановяване при бедствия (DRP), за да предотвратим загуба на данни в случай на авария или хардуерна повреда.
Архивирането е най-простата форма на DR, но може да не винаги е достатъчно, за да гарантира приемлива цел на точката на възстановяване (RPO). Препоръчително е да имате поне три резервни копия, съхранявани на различни физически места.
Най-добрата практика диктува, че архивните файлове трябва да имат един съхраняван локално на сървъра на базата данни (за по-бързо възстановяване), друг в централизиран сървър за архивиране и последният в облака.
За този блог ще разгледаме кои опции предоставя Amazon AWS за съхранението на PostgreSQL резервни копия в облака и ще покажем някои примери как да го направите.
Относно Amazon AWS
Amazon AWS е един от най-напредналите доставчици на облак в света по отношение на функции и услуги, с милиони клиенти. Ако искаме да стартираме нашите PostgreSQL бази данни на Amazon AWS, имаме някои опции...
-
Amazon RDS:Позволява ни да създаваме, управляваме и мащабираме PostgreSQL база данни (или различни технологии за бази данни) в облака по лесен и бърз начин.
-
Amazon Aurora:Това е PostgreSQL съвместима база данни, създадена за облака. Според уебсайта на AWS той е три пъти по-бърз от стандартните PostgreSQL бази данни.
-
Amazon EC2:Това е уеб услуга, която осигурява преоразмеряем изчислителен капацитет в облака. Той ви предоставя пълен контрол върху вашите изчислителни ресурси и ви позволява да настроите и конфигурирате всичко за вашите екземпляри от вашата операционна система до вашите приложения.
Но всъщност не е необходимо нашите бази данни да работят на Amazon, за да съхраняваме резервните си копия тук.
Съхранение на резервни копия в Amazon AWS
Има различни опции за съхраняване на резервното ни копие на PostgreSQL в AWS. Ако използваме нашата база данни PostgreSQL на AWS, имаме повече опции и (тъй като сме в една и съща мрежа) може да бъде и по-бързо. Нека видим как AWS може да ни помогне да съхраняваме резервните си копия.
AWS CLI
Първо, нека подготвим средата си за тестване на различните опции на AWS. За нашите примери ще използваме On-prem PostgreSQL 11 сървър, работещ на CentOS 7. Тук трябва да инсталираме AWS CLI, следвайки инструкциите от този сайт.
Когато имаме инсталиран нашия AWS CLI, можем да го тестваме от командния ред:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Сега следващата стъпка е да конфигурираме нашия нов клиент, изпълняващ командата aws с опцията configure.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:За да получите тази информация, можете да отидете в секцията IAM AWS и да проверите текущия потребител или ако предпочитате, можете да създадете нов за тази задача.
След това сме готови да използваме AWS CLI за достъп до нашите услуги на Amazon AWS.
Amazon S3
Това е може би най-често използваната опция за съхранение на резервни копия в облака. Amazon S3 може да съхранява и извлича произволно количество данни от всяко място в Интернет. Това е проста услуга за съхранение, която предлага изключително издръжлива, високодостъпна и безкрайно мащабируема инфраструктура за съхранение на данни на ниски разходи.
Amazon S3 предоставя прост интерфейс за уеб услуги, който можете да използвате за съхраняване и извличане на произволно количество данни, по всяко време, от всяко място в мрежата и (с AWS CLI или AWS SDK) вие може да го интегрира с различни системи и езици за програмиране.
Как да го използвам
Amazon S3 използва кофи. Те са уникални контейнери за всичко, което съхранявате в Amazon S3. И така, първата стъпка е достъп до конзолата за управление на Amazon S3 и създаване на нова кофа.
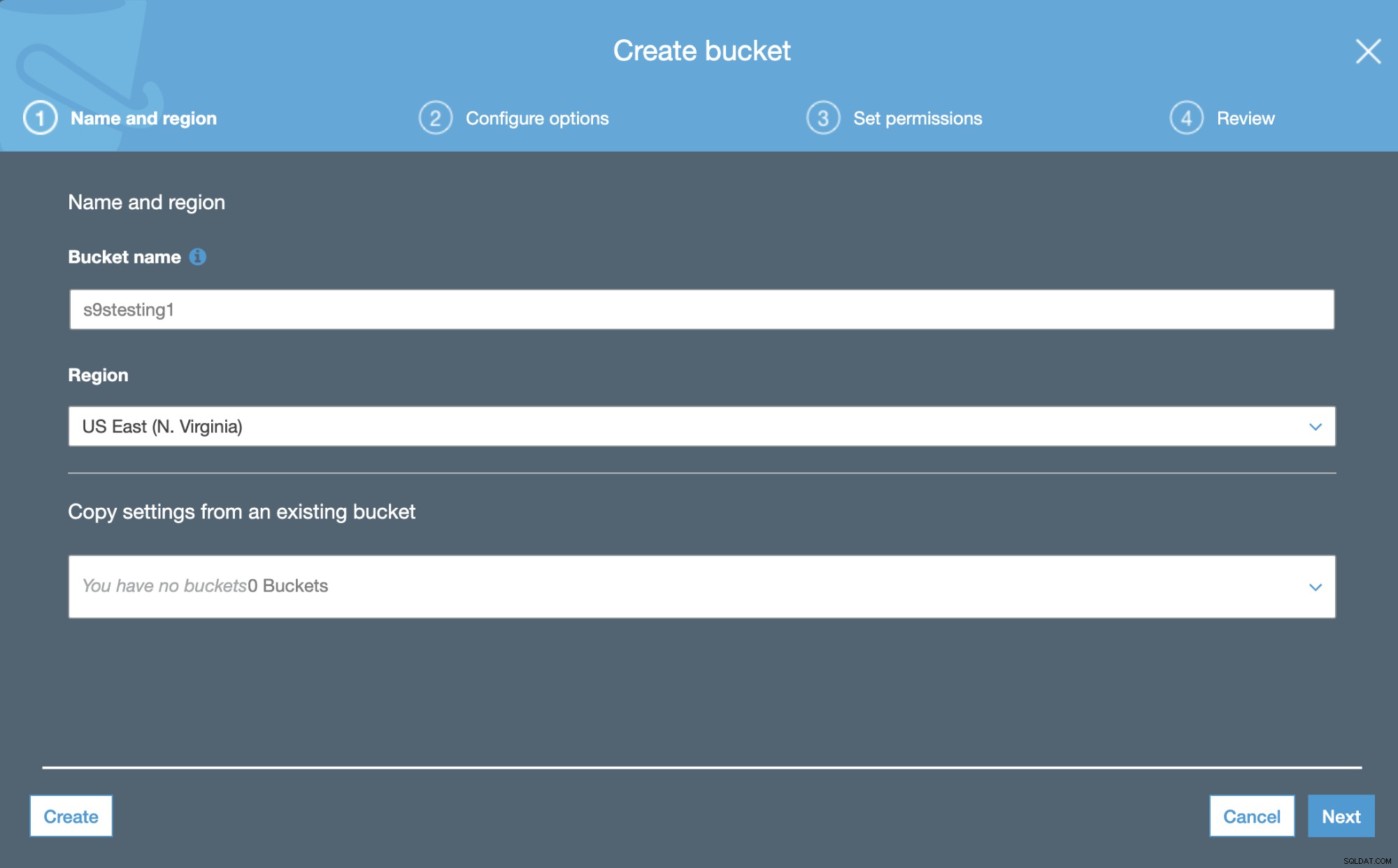
В първата стъпка просто трябва да добавим името на кошчето и AWS регион.
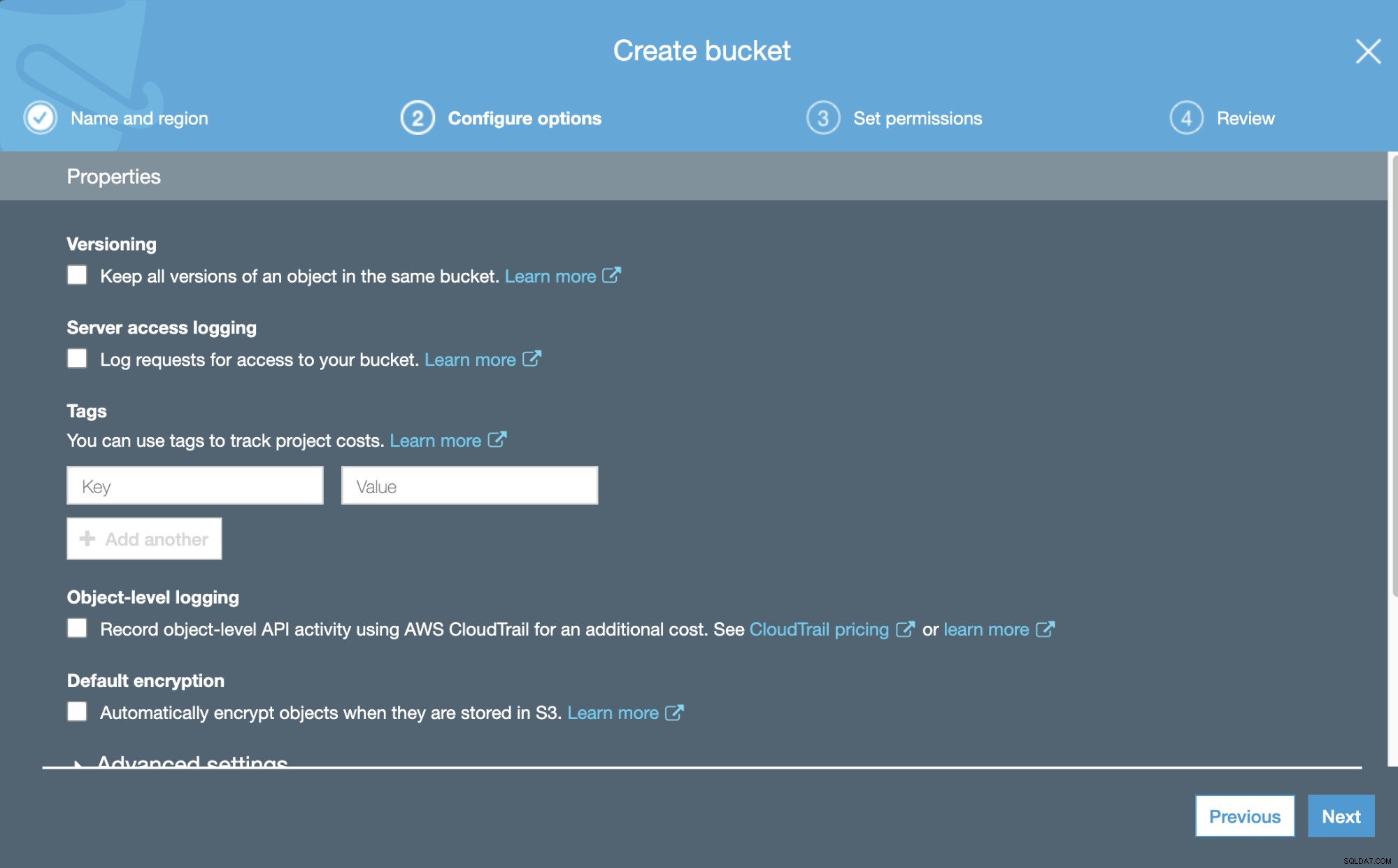
Сега можем да конфигурираме някои подробности за нашата нова кофа, като версия и регистриране.

И след това можем да посочим разрешенията за тази нова кофа.
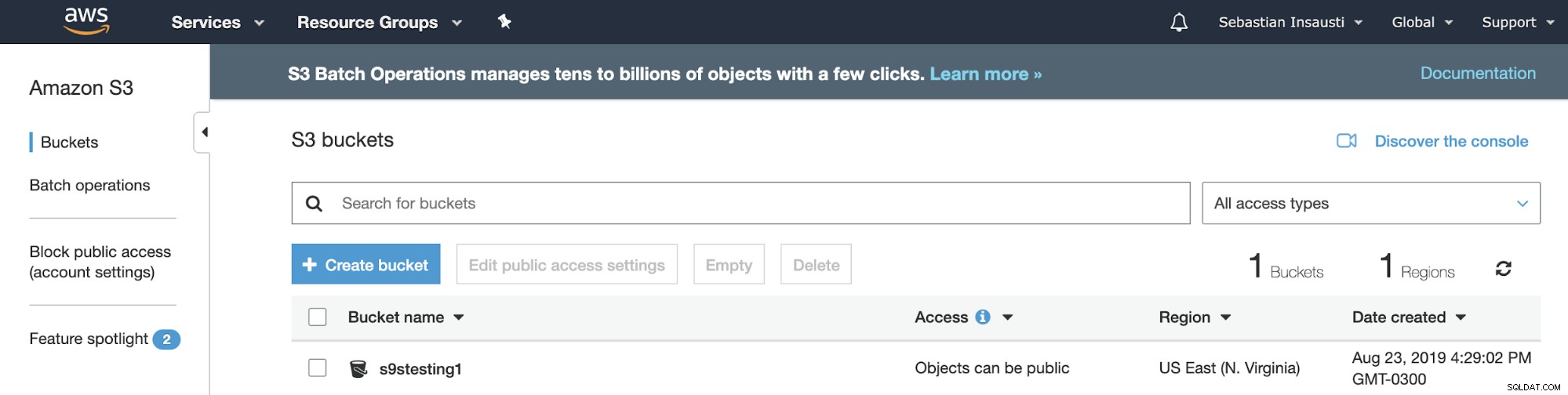
Сега имаме създадената ни кофа, нека видим как можем да я използваме за съхранявайте нашите резервни копия на PostgreSQL.
Първо, нека тестваме нашия клиент, който го свързва към S3.
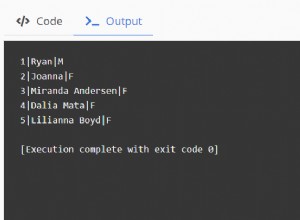
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Работи! С предишната команда изброяваме текущите създадени кошчета.
И така, сега можем просто да качим резервното копие в услугата S3. За това можем да използваме aws sync или aws cp команда.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Можем да проверим съдържанието на Bucket от уеб сайта на AWS.
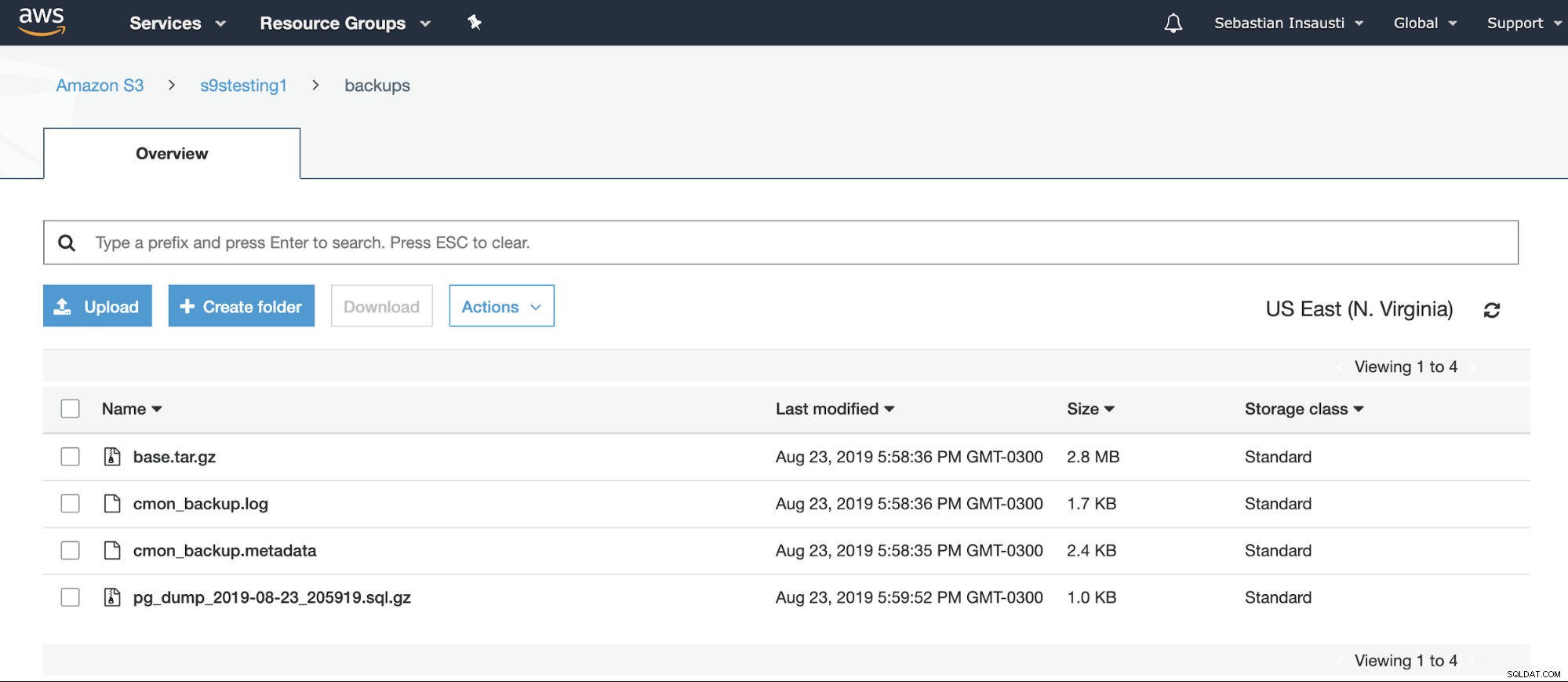
Или дори с помощта на AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzЗа повече информация относно AWS S3 CLI можете да проверите официалната документация на AWS.
Amazon S3 Glacier
Това е по-евтината версия на Amazon S3. Основната разлика между тях е скоростта и достъпността. Можете да използвате Amazon S3 Glacier, ако цената за съхранение трябва да остане ниска и не се нуждаете от милисекунди достъп до данните си. Използването е друга важна разлика между тях.
Как да го използвам
Вместо кофи, Amazon S3 Glacier използва Vaults. Това е контейнер за съхранение на всеки обект. И така, първата стъпка е да получите достъп до конзолата за управление на Amazon S3 Glacier и да създадете нов Vault.
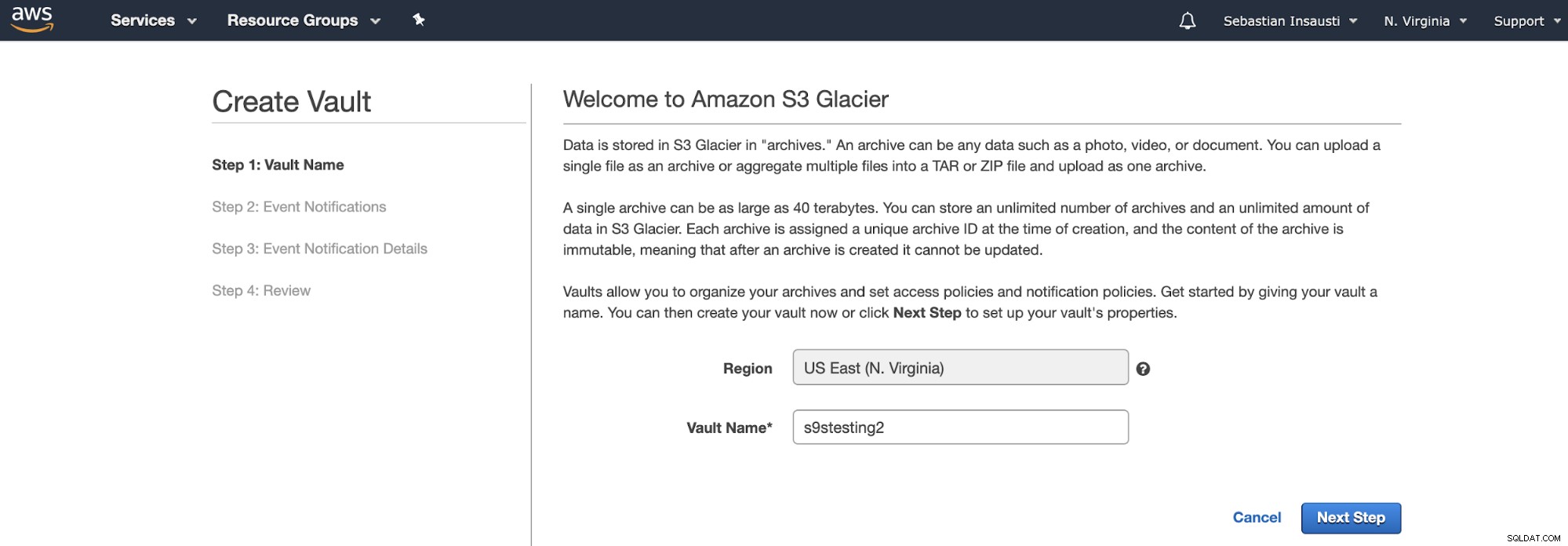
Тук трябва да добавим името на трезора и региона и в Следващата стъпка, можем да активираме известията за събития, които използват услугата Amazon Simple Notification Service (Amazon SNS).
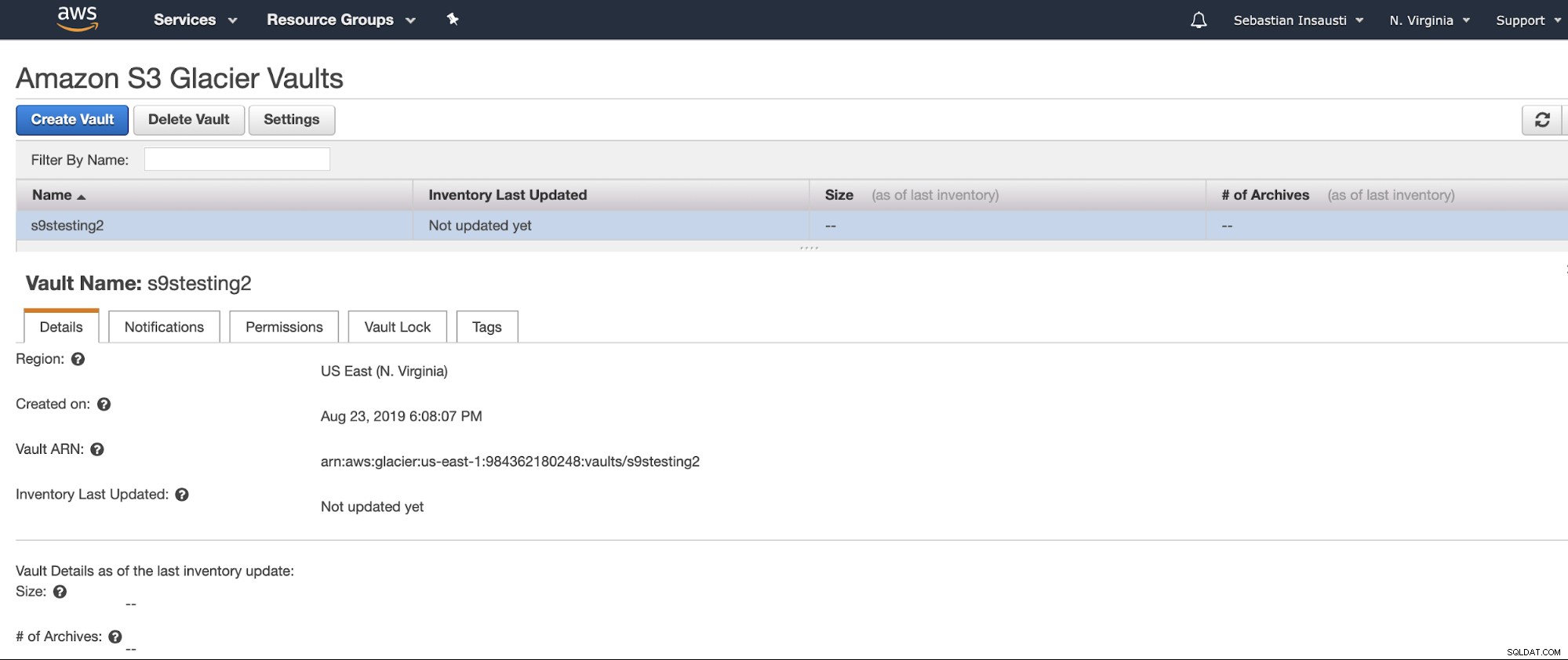
Сега създадехме нашия Vault, можем да осъществим достъп до него от AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Работи. Така че сега можем да качим нашето резервно копие тук.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Едно важно нещо е, че състоянието на Vault се актуализира приблизително веднъж на ден, така че трябва да изчакаме да видим качения файл.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Тук имаме нашия файл, качен в нашия S3 Glacier Vault.
За повече информация относно AWS Glacier CLI можете да проверите официалната документация на AWS.
EC2
Тази опция за архивиране е по-скъпата и отнема много време, но е полезна, ако искате да имате пълен контрол върху средата за съхранение на архиви и желаете да изпълнявате персонализирани задачи върху архивите (напр. Проверка на архивиране .)
Amazon EC2 (Elastic Compute Cloud) е уеб услуга, която осигурява преоразмеряем изчислителен капацитет в облака. Той ви предоставя пълен контрол над вашите изчислителни ресурси и ви позволява да настроите и конфигурирате всичко за вашите екземпляри от вашата операционна система до вашите приложения. Освен това ви позволява бързо да мащабирате капацитета, както нагоре, така и надолу, с промяната на вашите изчислителни изисквания.
Amazon EC2 поддържа различни операционни системи като Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux и FreeBSD.
Как да го използвам
Отидете в секцията Amazon EC2 и натиснете Launch Instance. В първата стъпка трябва да изберете операционната система на екземпляра EC2.
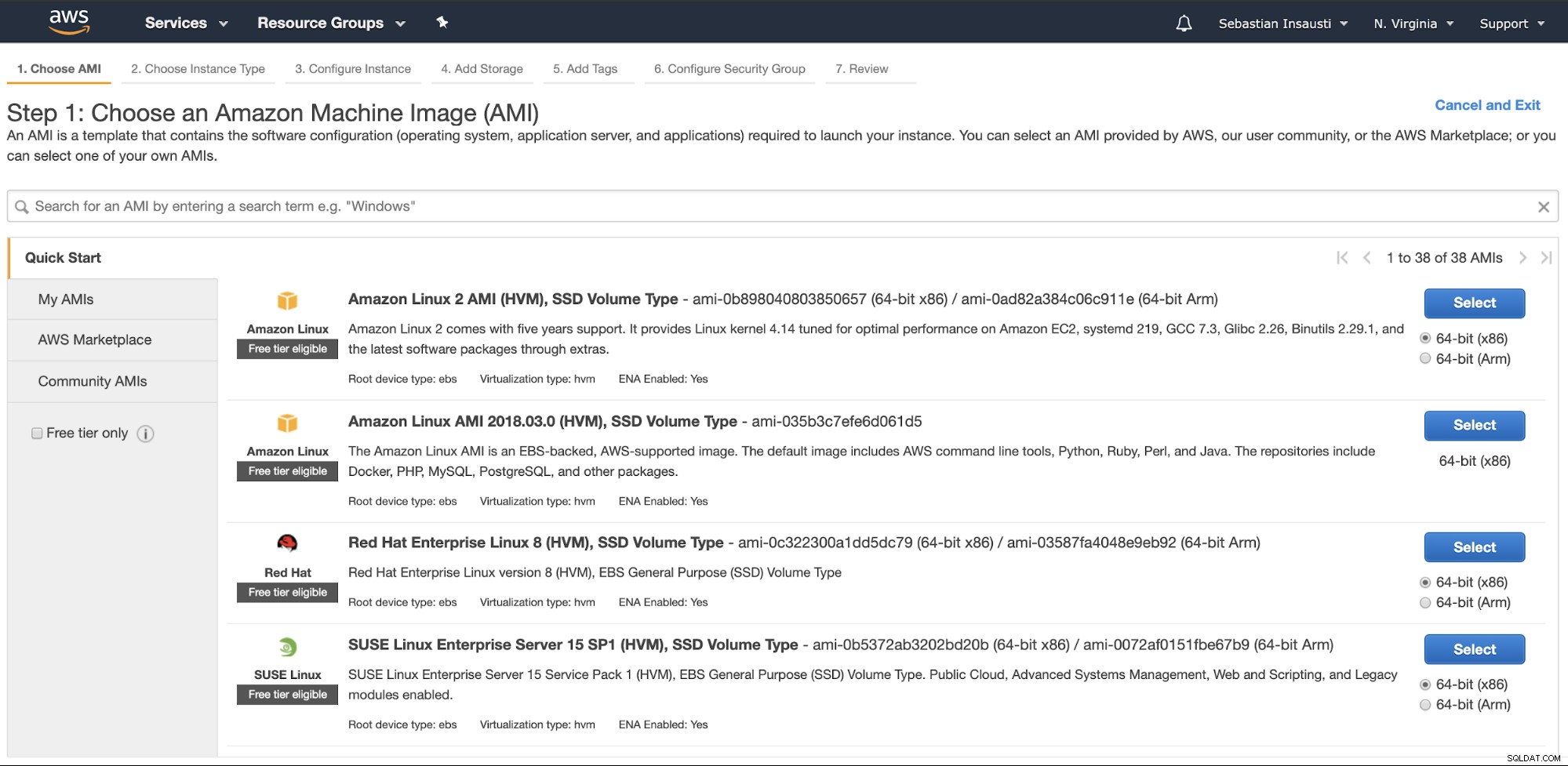
В следващата стъпка трябва да изберете ресурсите за новия екземпляр.
След това можете да посочите по-подробна конфигурация като мрежа, подмрежа и др. .
Сега можем да добавим повече капацитет за съхранение на този нов екземпляр и като резервен сървър, трябва да го направим.
Когато завършим задачата за създаване, можем да отидем в секцията Инстанции, за да вижте нашия нов EC2 екземпляр.
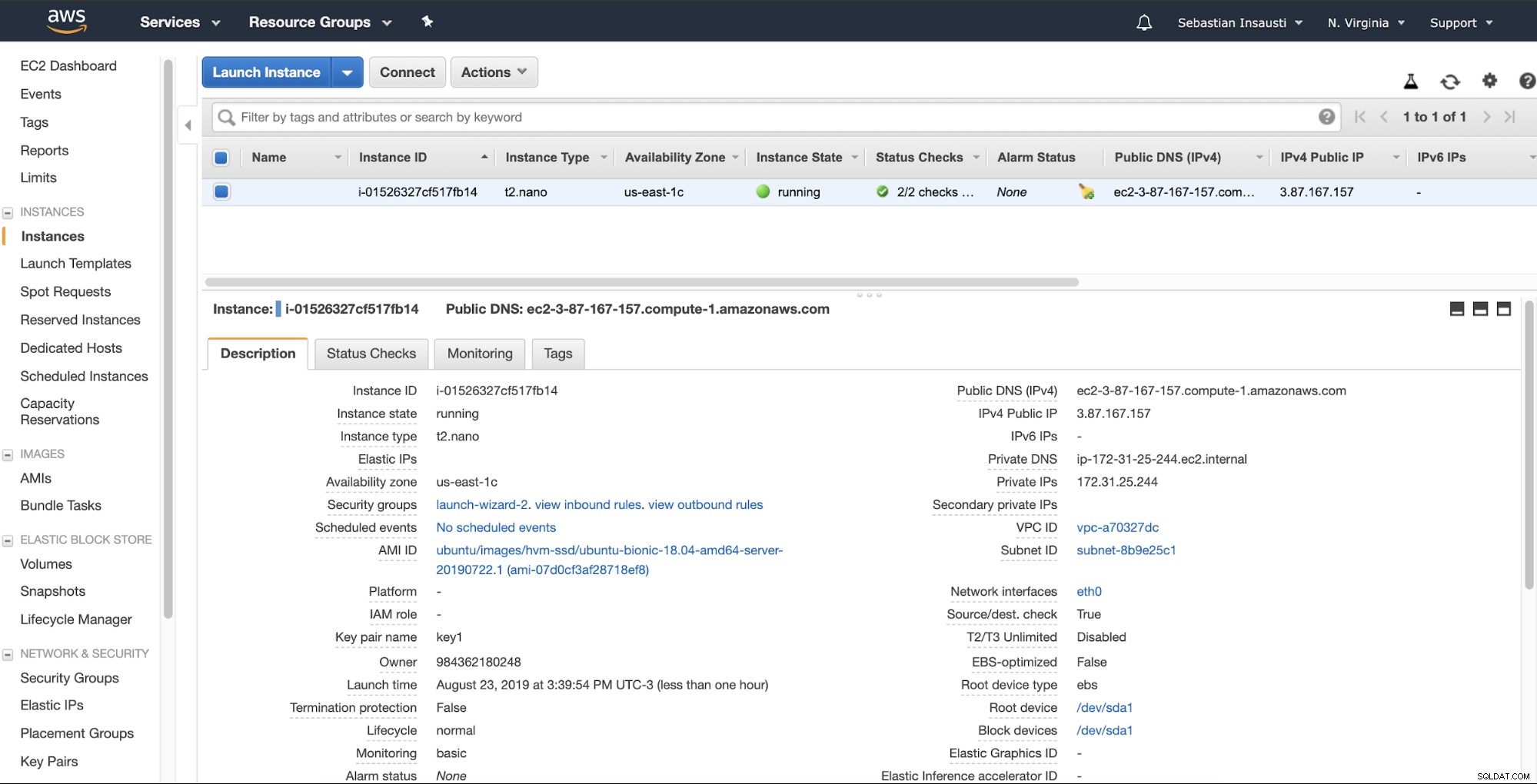
Когато екземплярът е готов (състоянието на екземпляра се изпълнява), можете да съхраните архивиране тук, например изпращането му чрез SSH или FTP чрез публичния DNS, създаден от AWS. Нека видим пример с Rsync и още един с командата SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00Архивиране на AWS
AWS Backup е централизирана услуга за архивиране, която ви предоставя възможности за управление на архивиране, като планиране на архивиране, управление на задържане и наблюдение на архивиране, както и допълнителни функции, като архивиране на жизнения цикъл на ниска цена ниво на съхранение, архивно съхранение и криптиране, което е независимо от неговите изходни данни, и политики за достъп до архивиране.
Можете да използвате AWS Backup за управление на резервни копия на EBS томове, RDS бази данни, DynamoDB таблици, файлови системи EFS и томове на Storage Gateway.
Как да го използвам
Отидете в секцията за архивиране на AWS на конзолата за управление на AWS.
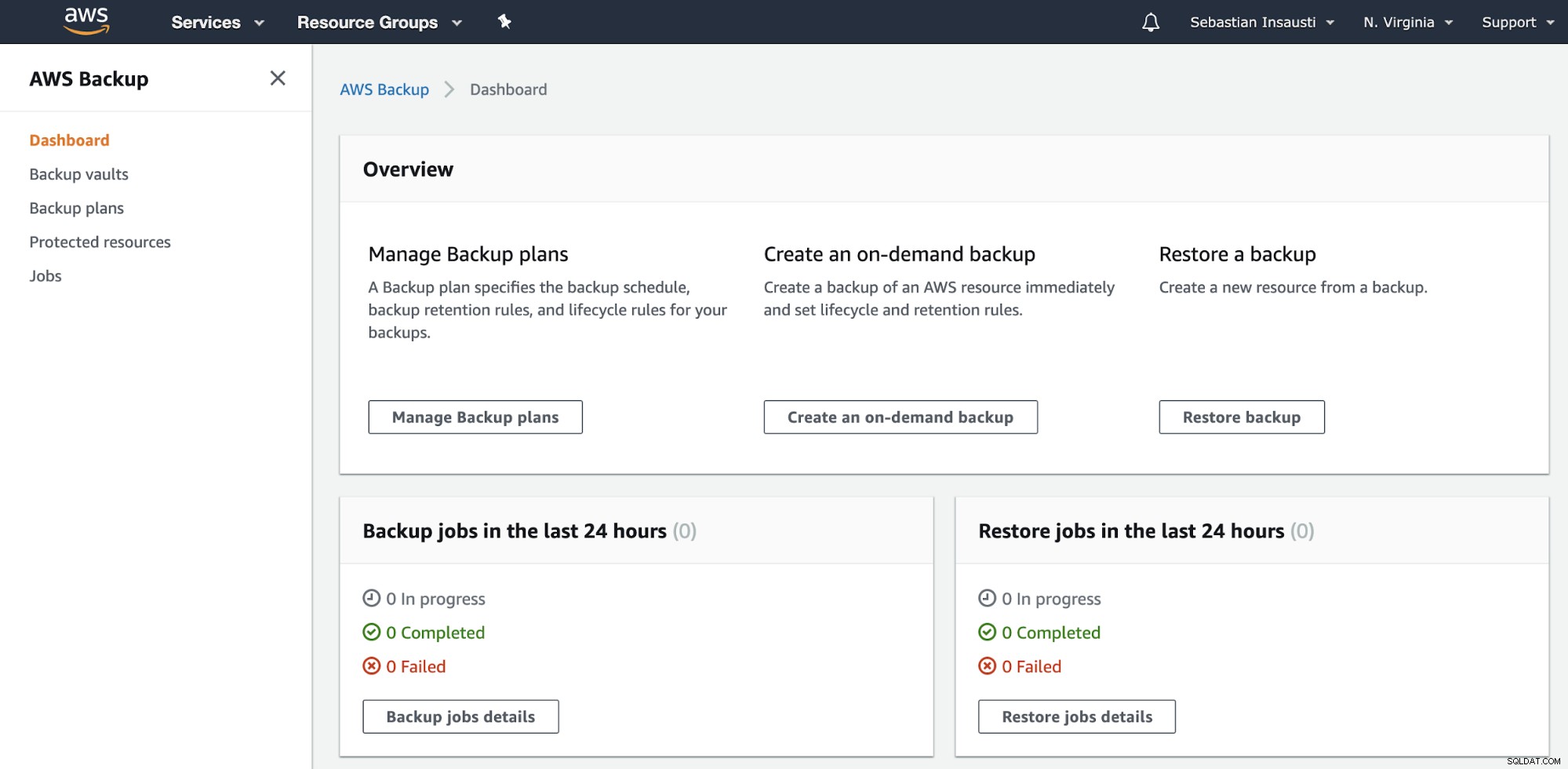
Тук имате различни опции, като например график, създаване или възстановяване на резервно копие . Нека видим как да създадем ново архивно копие.
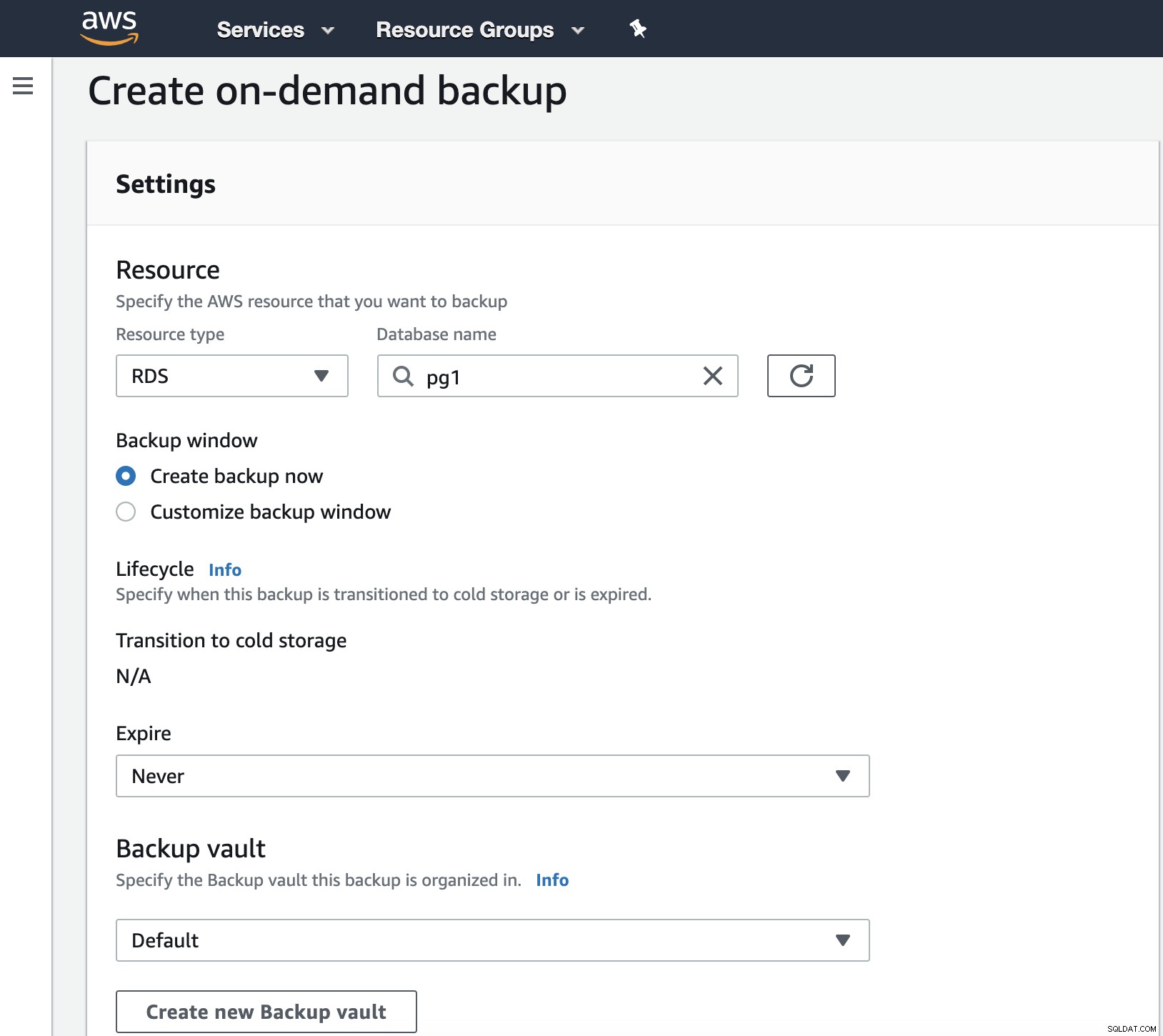
В тази стъпка трябва да изберем типа на ресурса, който може да бъде DynamoDB, RDS, EBS, EFS или Storage Gateway и повече подробности като дата на изтичане, архивен хранилище и ролята на IAM.
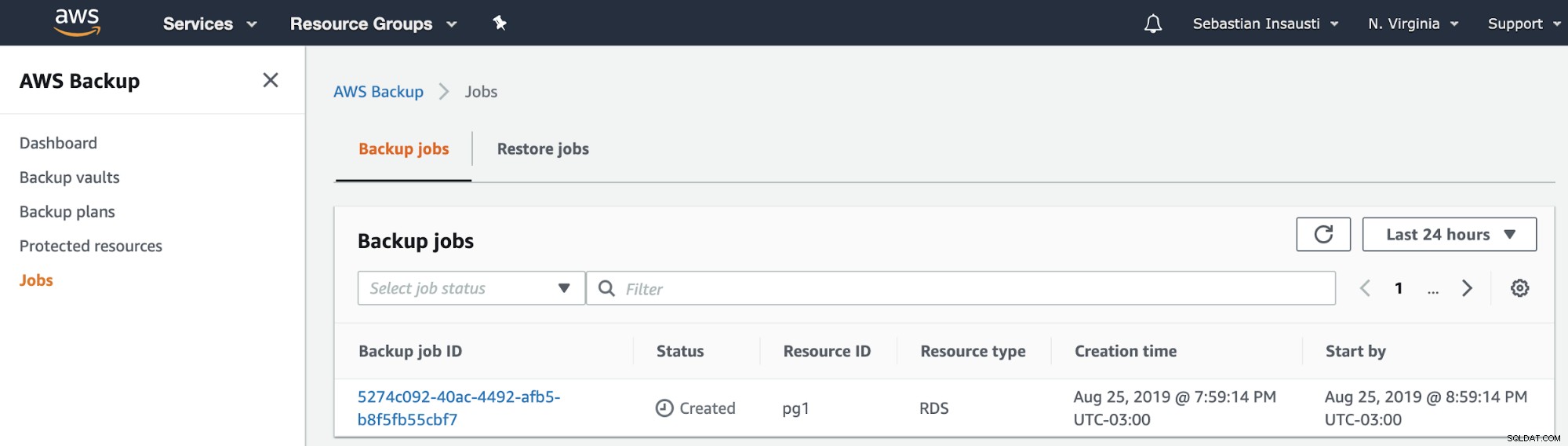
След това можем да видим новото задание, създадено в секцията AWS Backup Jobs .
Моментна снимка
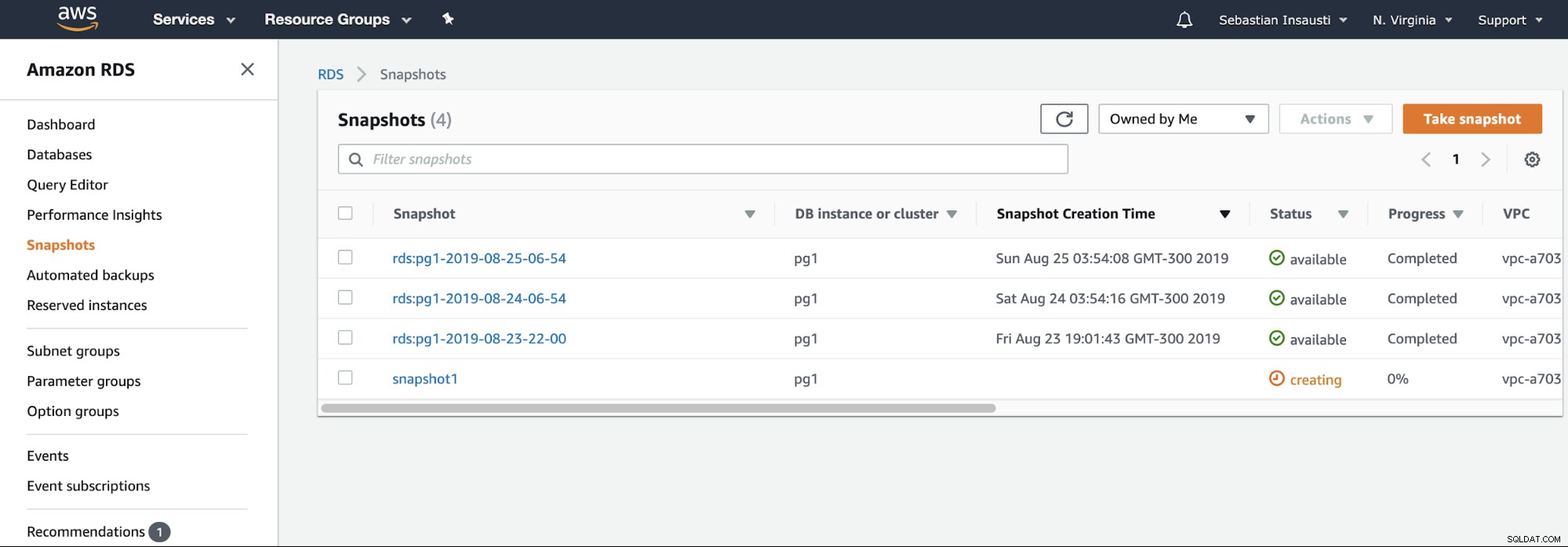
Сега можем да споменем тази известна опция във всички среди за виртуализация. Моментната снимка е резервно копие, направено в определен момент от време и AWS ни позволява да го използваме за продуктите на AWS. Нека дадем пример за RDS моментна снимка.
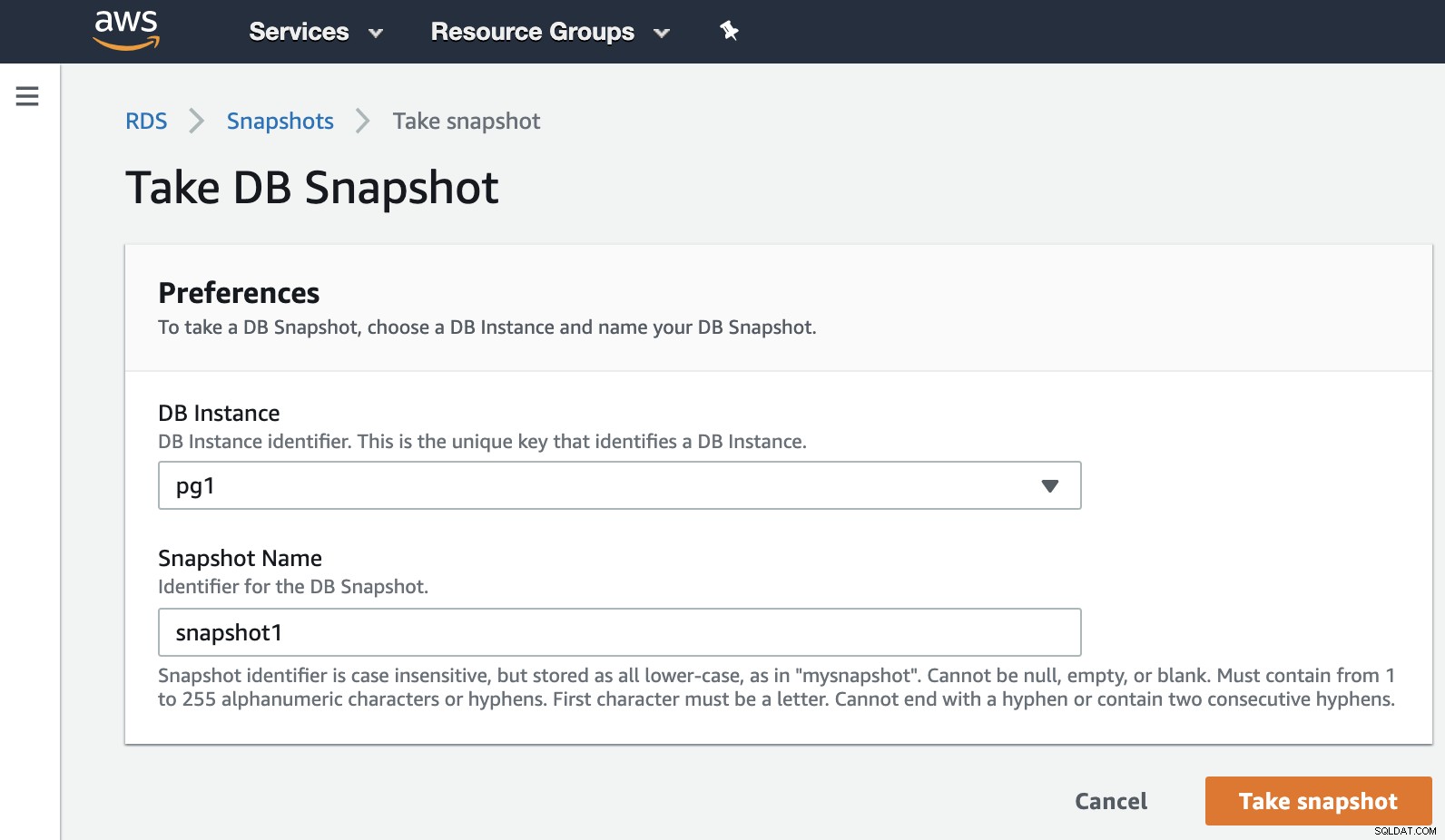
Трябва само да изберем екземпляра и да добавим името на моментната снимка и това е то. Можем да видим тази и предишната моментна снимка в раздела RDS Snapshot.
Управление на вашите архиви с ClusterControl
ClusterControl е цялостна система за управление на бази данни с отворен код, която автоматизира функциите за внедряване и управление, както и наблюдение на здравето и производителността. ClusterControl поддържа внедряване, управление, наблюдение и мащабиране за различни технологии за бази данни и среди, включително EC2. Така че можем например да създадем нашия EC2 екземпляр на AWS и да разположим/импортираме нашата услуга за база данни с ClusterControl.

Създаване на резервно копие
За тази задача отидете на ClusterControl -> Изберете Cluster -> Backup -> Създайте архив.
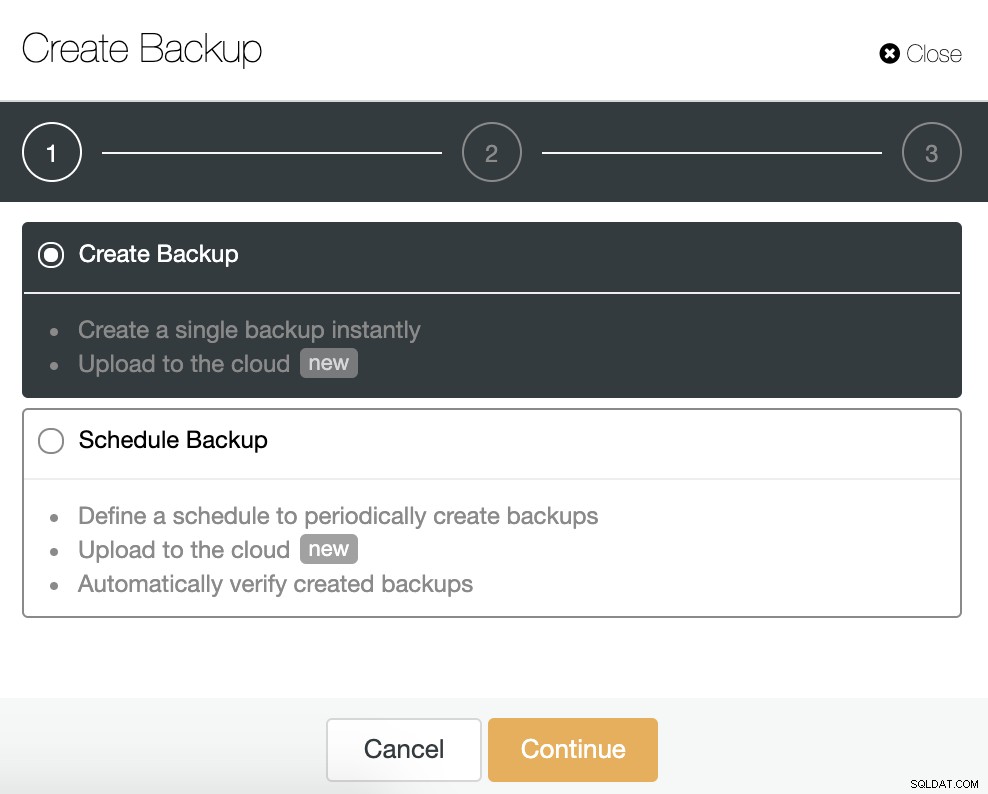
Можем да създадем ново архивиране или да конфигурираме насрочено такова. За нашия пример незабавно ще създадем едно резервно копие.
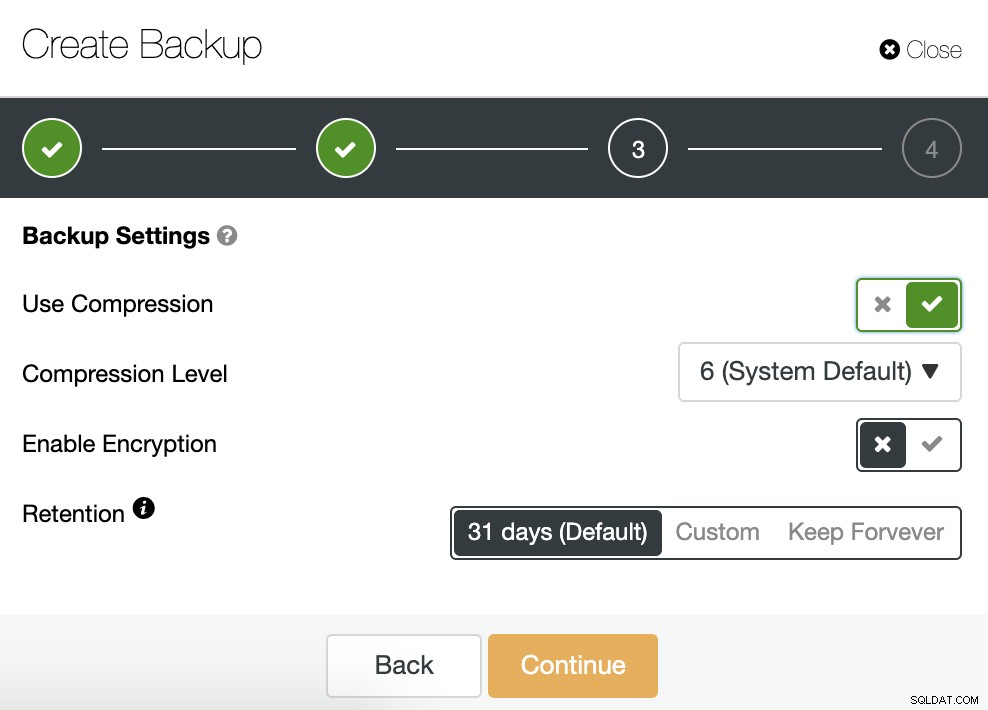
Трябва да изберем един метод, сървърът, от който ще бъде взето архивирането и къде искаме да съхраняваме архива. Можем също да качим нашето резервно копие в облака (AWS, Google или Azure), като активираме съответния бутон.
След това указваме използването на компресия, нивото на компресия, криптиране и задържане период за нашето резервно копие.
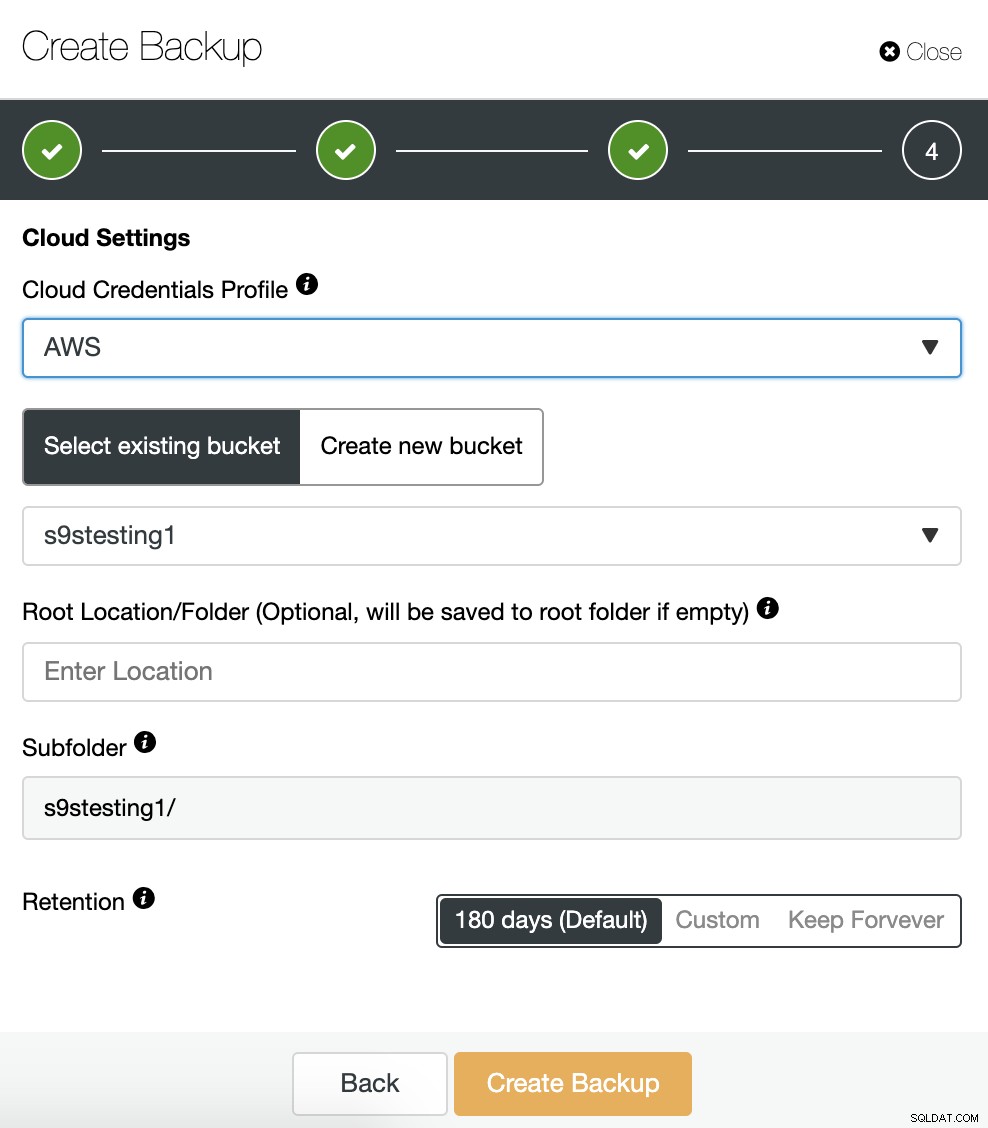
Ако сме активирали опцията за архивиране на качване в облака, ще видим раздел за определяне на доставчика на облак (в този случай AWS) и идентификационните данни (ClusterControl -> Integrations -> Cloud Providers). За AWS той използва услугата S3, така че трябва да изберем кофа или дори да създадем нова, за да съхраняваме нашите резервни копия.
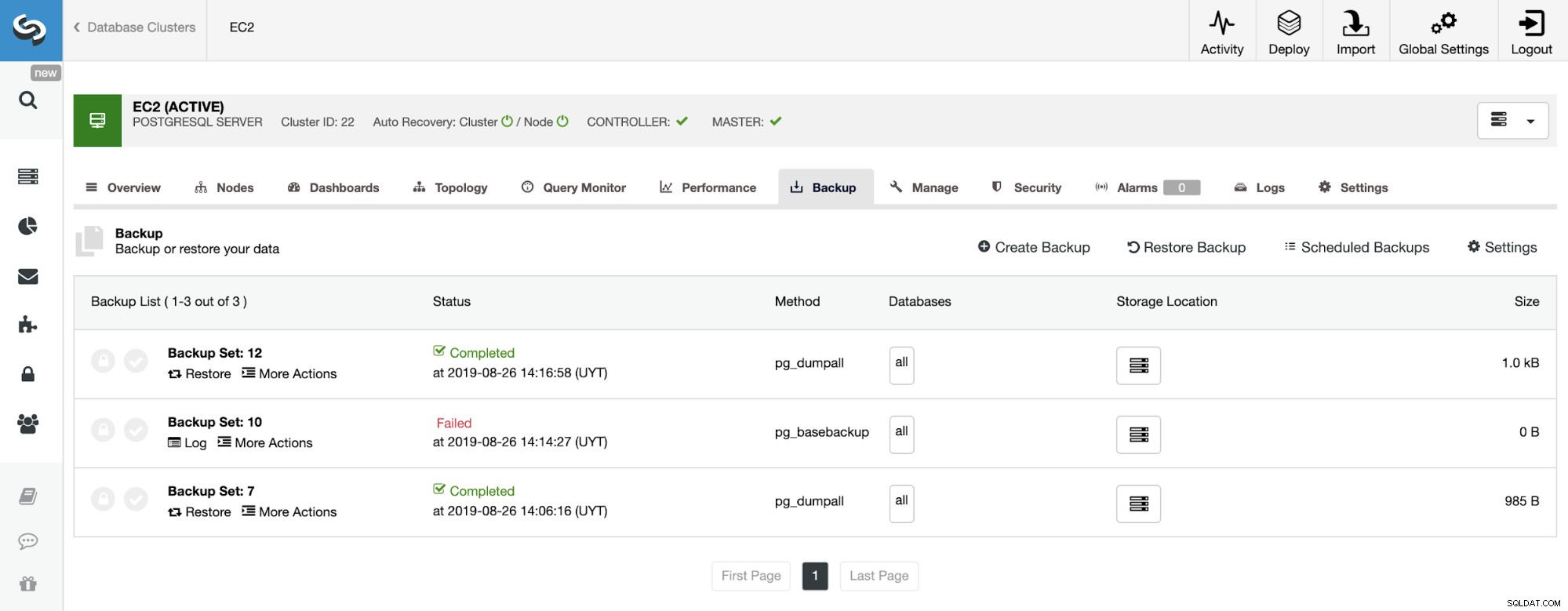
В секцията за архивиране можем да видим напредъка на архивирането и информация като метод, размер, местоположение и др.
Заключение
Amazon AWS ни позволява да съхраняваме нашите резервни копия на PostgreSQL, независимо дали го използваме като доставчик на облак на база данни или не. За да имате ефективен план за архивиране, трябва да помислите за съхраняване на поне едно резервно копие на базата данни в облака, за да избегнете загуба на данни в случай на хардуерна повреда в друго хранилище за архивиране. Облакът ви позволява да съхранявате толкова резервни копия, колкото искате да съхранявате или платите.