Всеки продукт има грешки и SQL Server не е изключение. Използването на характеристиките на продукта по малко необичаен начин (или комбинирането на сравнително нови функции заедно) е чудесен начин да ги намерите. Бъговете могат да бъдат интересни и дори образователни, но може би някои от радостите се губят, когато откритието води до пейджъра ви да се включи в 4 сутринта, може би след особено социална вечер с приятели...
Бъгът, който е обект на тази публикация, вероятно е сравнително рядък в дивата природа, но не е класически край. Знам за поне един консултант, който го е срещал в производствена система. По една напълно несвързана тема, трябва да използвам възможността да кажа „здравей“ на Grumpy Old DBA (блог).
Ще започна с малко подходяща информация за обединяванията за сливане. Ако сте сигурни, че вече знаете всичко, което трябва да знаете за присъединяването към сливане, или просто искате да преминете към преследването, не се колебайте да превъртите надолу до секцията, озаглавена „Бъгът“.
Сливане на присъединяване
Присъединяването на сливане не е много сложно нещо и може да бъде много ефективно при правилните обстоятелства. Той изисква неговите входове да са сортирани по свързващите ключове и се представя най-добре в режим един към много (където поне от неговите входове са уникални за свързващите ключове). За обединения „едно към много“ със среден размер, серийното обединяване изобщо не е лош избор, при условие че изискванията за сортиране на входа могат да бъдат изпълнени, без да се извършва изрично сортиране.
Избягването на сортиране най-често се постига чрез използване на подреждането, предоставено от индекс. Обединяването при сливане може също да се възползва от запазения ред на сортиране от по-ранно, неизбежно сортиране. Страхотно нещо за обединяването с обединяване е, че може да спре обработката на входните редове веднага щом всеки от входните редове свърши. И последно нещо:обединяването на сливане не се интересува дали редът на сортиране на входа е възходящ или низходящ (въпреки че и двата входа трябва да са еднакви). Следният пример използва стандартна таблица с числа, за да илюстрира повечето от точките по-горе:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Забележете, че индексите, налагащи първичните ключове на тези две таблици, са дефинирани като низходящи. Планът на заявката за INSERT има редица интересни функции:
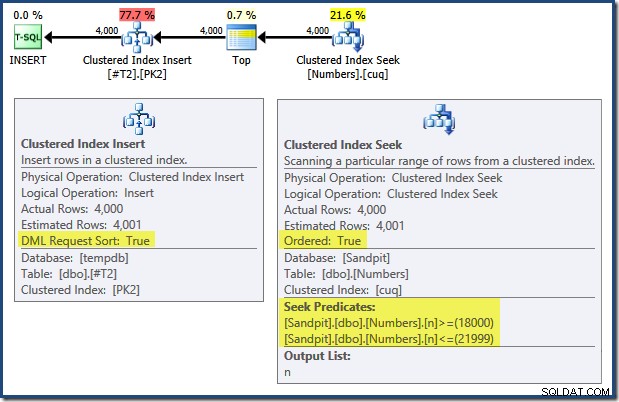
При четене отляво надясно (както е само разумно!) Вмъкването на клъстериран индекс има зададено свойство "DML Request Sort". Това означава, че операторът изисква редове в ред на ключове с клъстериран индекс. Клъстерираният индекс (прилагане на първичния ключ в този случай) се дефинира като DESC , така че редовете с по-високи стойности трябва да пристигнат първи. Клъстерираният индекс в моята таблица с числа е ASC , така че оптимизаторът на заявки избягва изрично сортиране, като търси първо най-високото съвпадение в таблицата с числа (21 999), след което сканира към най-ниското съвпадение (18 000) в обратен индексен ред. Изгледът „Дърво на плановете“ в SQL Sentry Plan Explorer показва ясно обратното (обратно) сканиране:
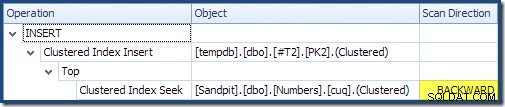
Сканирането назад обръща естествения ред на индекса. Сканиране назад на ASC индексен ключ връща редове в низходящ ред на ключове; обратно сканиране на DESC индексният ключ връща редове във възходящ ред на ключове. „Посока на сканиране“ не указва сама по себе си върнатия ред на ключове – трябва да знаете дали индексът е ASC или DESC за да вземе това решение.
Използвайки тези тестови таблици и данни (T1 има 10 000 реда, номерирани от 10 000 до 19 999 включително; T2 има 4 000 реда, номерирани от 18 000 до 21 999) следната заявка свързва двете таблици заедно и връща резултатите в низходящ ред на двата ключа:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Заявката връща правилните съвпадащи 2000 реда, както бихте очаквали. Планът след изпълнение е следният:
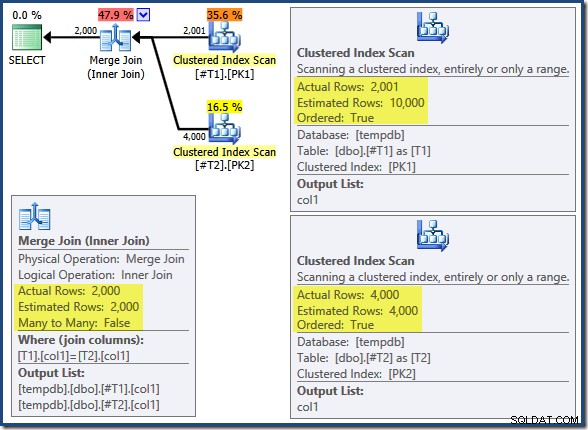
Обединяването на сливане не се изпълнява в режим много към много (горният вход е уникален за клавишите за присъединяване) и оценката за мощността на 2000 реда е точно правилна. Клъстерното индексно сканиране на таблица T2 е подредено (въпреки че трябва да изчакаме малко, за да разберем дали този ред е напред или назад) и оценката за мощността на 4000 реда също е точно правилна. Клъстерното индексно сканиране на таблица T1 е също поръчан, но са прочетени само 2 001 реда, докато се оценяват 10 000. Дървовидният изглед на плана показва, че и двете клъстерирани индексни сканирания са подредени напред:
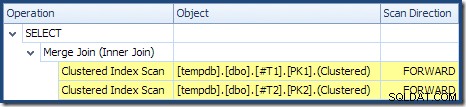
Припомнете си, че четете DESC индекс FORWARD ще произведе редове в обратен ключов ред. Точно това се изисква от ORDER BY T1.col DESC, T2.col1 DESC клауза, така че не е необходимо изрично сортиране. Псевдокод за присъединяване един към много (възпроизведен от блога на Craig Freedman Merge Join) е:

Сканиране в низходящ ред на T1 връща редове, започващи от 19 999 и намаляващи към 10 000. Сканиране в низходящ ред на T2 връща редове, започващи от 21 999 и намаляващи към 18 000. Всичките 4000 реда в T2 в крайна сметка се четат, но итеративният процес на сливане спира, когато ключовата стойност 17 999 се прочете от T1 , защото T2 изчерпва редовете. Следователно обработката на сливане завършва без пълно четене на T1 . Той чете редове от 19 999 надолу до 17 999 включително; общо 2001 реда, както е показано в плана за изпълнение по-горе.
Чувствайте се свободни да стартирате отново теста с ASC индекси вместо това, като също така променя ORDER BY клауза от DESC към ASC . Създаденият план за изпълнение ще бъде много подобен и няма да са необходими сортове.
За да обобщим точките, които ще бъдат важни в даден момент, Merge Join изисква сортирани входове по ключ за присъединяване, но няма значение дали ключовете са сортирани възходящо или низходящо.
Бъгът
За да възпроизведете грешката, поне една от нашите таблици трябва да бъде разделена. За да запази резултатите управляеми, този пример ще използва само малък брой редове, така че функцията за разделяне също се нуждае от малки граници:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Първата таблица съдържа две колони и е разделена на ПЪРВИЧНИЯ КЛЮЧ:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Втората таблица не е разделена. Той съдържа първичен ключ и колона, която ще се присъедини към първата таблица:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Примерните данни
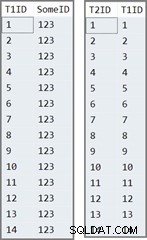
Първата таблица има 14 реда, всички с една и съща стойност в SomeID колона. SQL Server присвоява IDENTITY стойности на колони, номерирани от 1 до 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Втората таблица просто се попълва с IDENTITY стойности от таблица първа:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Данните в двете таблици изглеждат така:
Тестовата заявка
Първата заявка просто се присъединява към двете таблици, прилагайки един предикат на клауза WHERE (който съвпада с всички редове в този силно опростен пример):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Резултатът съдържа всичките 14 реда, както се очаква:

Поради малкия брой редове, оптимизаторът избира план за присъединяване на вложени цикли за тази заявка:
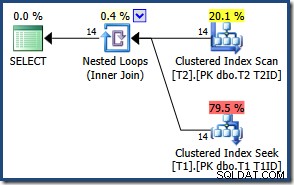
Резултатите са същите (и все още верни), ако принудим хеширане или обединяване:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
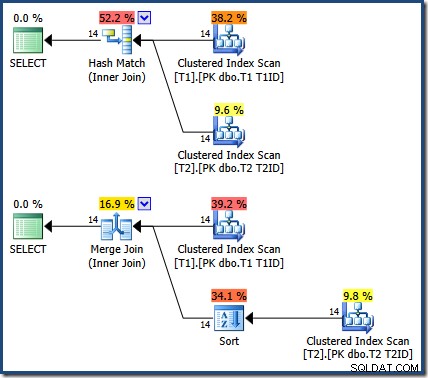
Сливането там е едно към много, с изрично сортиране на T1ID изисква се за таблица T2 .
Проблемът с низходящия индекс
Всичко е наред, докато един ден (по основателни причини, които не трябва да ни засягат тук) друг администратор не добави низходящ индекс към SomeID колона от таблица 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Нашата заявка продължава да дава правилни резултати, когато оптимизаторът избере вложени цикли или хеш присъединяване, но това е различна история, когато се използва обединяване с обединяване. Следното все още използва намек за заявка, за да принуди Merge Join, но това е само следствие от ниския брой редове в примера. Оптимизаторът естествено ще избере един и същ план за присъединяване към сливане с различни данни в таблицата.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Планът за изпълнение е:
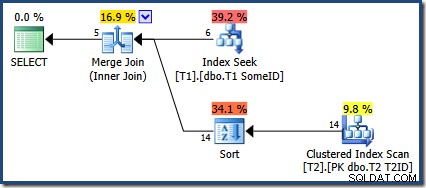
Оптимизаторът е избрал да използва новия индекс, но заявката вече произвежда само пет реда изход:

Какво стана с останалите 9 реда? За да бъде ясно, този резултат е неправилен. Данните не са се променили, така че всички 14 реда трябва да бъдат върнати (както все още са с план за вложени цикли или хеш присъединяване).
Причина и обяснение
Новият неклъстериран индекс на SomeID не е деклариран като уникален, така че ключът за клъстериран индекс се добавя безшумно към всички неклъстерирани индексни нива. SQL Server добавя T1ID колона (клъстерираният ключ) към неклъстерирания индекс, точно както ако бяхме създали индекса така:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Забележете липсата на DESC квалификатор на тихо добавения T1ID ключ. Индексните клавиши са ASC по подразбиране. Това не е проблем само по себе си (въпреки че допринася). Второто нещо, което се случва с нашия индекс автоматично, е, че той е разделен по същия начин, по който е основната таблица. И така, пълната спецификация на индекса, ако трябваше да я изпишем изрично, би била:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Това вече е доста сложна структура, с ключове във всякакви различни порядки. Той е достатъчно сложен, за да може оптимизаторът на заявки да го обърка, когато разсъждава за реда на сортиране, предоставен от индекса. За да илюстрирате, разгледайте следната проста заявка:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Допълнителната колона просто ще ни покаже към кой дял принадлежи текущият ред. В противен случай това е просто заявка, която връща T1ID стойности във възходящ ред, WHERE SomeID = 123 . За съжаление резултатите не са това, което е посочено в заявката:
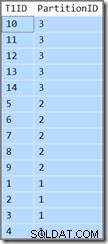
Заявката изисква този T1ID стойностите трябва да се връщат във възходящ ред, но не получаваме това. Получаваме стойности във възходящ ред на дял , но самите дялове се връщат в обратен ред! Ако дяловете са били върнати във възходящ ред (и T1ID стойностите остават сортирани във всеки дял, както е показано) резултатът ще бъде правилен.
Планът на заявката показва, че оптимизаторът е бил объркан от водещия DESC ключ на индекса и смята, че трябва да прочете дяловете в обратен ред за правилни резултати:
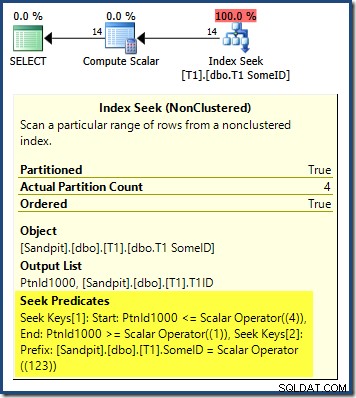
Търсенето на дял започва от най-десния дял (4) и продължава назад към дял 1. Може да си помислите, че можем да решим проблема, като изрично сортираме по номер на дял ASC в ORDER BY клауза:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Тази заявка връща същите резултати (това не е печатна грешка или грешка при копиране/поставяне):
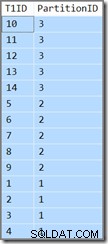
Идентификационният номер на дяла все още е в низходящ ред (не нарастващ, както е посочено) и T1ID се сортира само възходящо във всеки дял. Такова е объркването на оптимизатора, той наистина смята (поемете дълбоко дъх сега), че сканирането на разделения индекс на водещо-низходящ ключ в посока напред, но с обърнати дялове, ще доведе до реда, определен от заявката.
Не го обвинявам, ако трябва да бъда откровен, различните съображения за реда на сортиране също ме боли главата.
Като последен пример, помислете за:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Резултатите са:

Отново T1ID ред на сортиране във всеки дял е правилно низходящ, но самите дялове са изброени назад (те отиват от 1 до 3 надолу по редовете). Ако дяловете бяха върнати в обратен ред, резултатите биха били правилно 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Обратно към присъединяването за сливане
Причината за неправилните резултати със заявката за присъединяване към сливане вече е очевидна:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
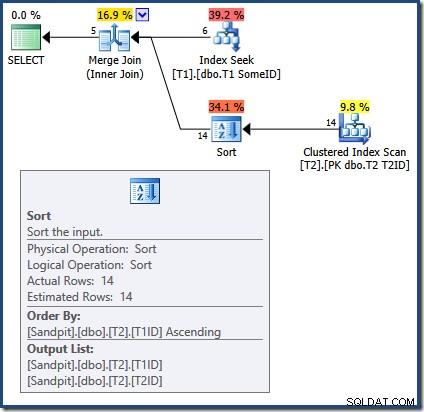
Обединяването за сливане изисква сортирани входове. Входът от T2 е изрично сортирано по T1TD така че това е добре. Оптимизаторът неправилно обосновава, че индексът на T1 може да предостави редове в T1ID поръчка. Както видяхме, това не е така. Търсенето на индекс произвежда същия изход като заявка, която вече сме виждали:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Само първите 5 реда са в T1ID поръчка. Следващата стойност (5) със сигурност не е във възходящ ред и Merge Join интерпретира това като край на потока, вместо да създава грешка (лично очаквах твърдение за продажба на дребно тук). Както и да е, ефектът е, че Merge Join неправилно завършва обработката рано. Като напомняне, (непълните) резултати са:

Заключение
Това е много сериозен бъг според мен. Простото търсене на индекс може да върне резултати, които не спазват ORDER BY клауза. По-важното е, че вътрешните разсъждения на оптимизатора са напълно нарушени за разделени неуникални неклъстерирани индекси с низходящ водещ ключ.
Да, това е леко необичайно подреждане. Но, както видяхме, правилните резултати могат внезапно да бъдат заменени с неправилни, само защото някой е добавил низходящ индекс. Не забравяйте, че добавеният индекс изглеждаше достатъчно невинен:няма изричен ASC/DESC несъответствие на ключовете и без изрично разделяне.
Грешката не се ограничава до Merge Joins. Потенциално всяка заявка, която включва разделена таблица и която разчита на реда на сортиране на индекса (явна или неявна), може да стане жертва. Тази грешка съществува във всички версии на SQL Server от 2008 до 2014 CTP 1 включително. Windows SQL Azure Database не поддържа разделяне, така че проблемът не възниква. SQL Server 2005 използва различен модел на внедряване за разделяне (базирано на APPLY ) и също не страда от този проблем.
Ако имате малко време, моля, помислете за гласуване за моя елемент Connect за тази грешка.
Разделителна способност
Корекцията за този проблем вече е достъпна и документирана в статия от базата знания. Моля, имайте предвид, че корекцията изисква актуализация на кода и флаг за проследяване 4199 , което позволява редица други промени в процесора на заявки. Необичайно е грешка с неправилни резултати да бъде коригирана под 4199. Помолих за разяснение по въпроса и отговорът беше:
Въпреки че този проблем включва неправилни резултати като други спешни корекции, включващи процесора на заявки, ние сме активирали тази корекция само под флаг за проследяване 4199 за SQL Server 2008, 2008 R2 и 2012. Тази корекция обаче е „включена“ от по подразбиране без флага за проследяване в SQL Server 2014 RTM.