Промените във вътрешното представяне на разделени таблици между SQL Server 2005 и SQL Server 2008 доведоха до подобрени планове за заявки и производителност в повечето случаи (особено когато се включва паралелно изпълнение). За съжаление, същите промени причиниха някои неща, които работеха добре в SQL Server 2005, изведнъж да не работят толкова добре в SQL Server 2008 и по-късно. Тази публикация разглежда един пример, при който оптимизаторът на заявки на SQL Server 2005 създаде по-добър план за изпълнение в сравнение с по-късните версии.
Примерна таблица и данни
Примерите в тази публикация използват следната разделена таблица и данни:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Оформление на разделени данни
Нашата таблица има разделен клъстериран индекс. В този случай ключът за клъстериране също служи като ключ за разделяне (въпреки че това не е изискване като цяло). Разделянето води до отделни физически единици за съхранение (набори от редове), които процесорът на заявки представя на потребителите като едно цяло.
Диаграмата по-долу показва първите три дяла на нашата таблица (щракнете, за да увеличите):
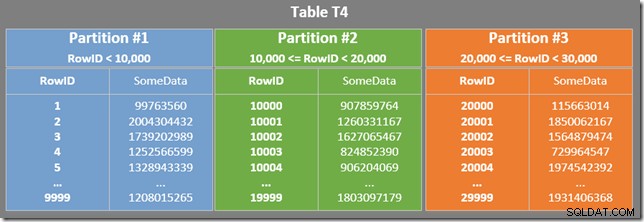
Неклъстерираният индекс се разделя по същия начин (той е „подравнен“):

Всеки дял на неклъстерирания индекс покрива диапазон от стойности на RowID. Във всеки дял данните се подреждат от SomeData (но стойностите на RowID няма да бъдат подредени като цяло).
Проблемът MIN/MAX
Доста добре известно е, че MIN и MAX агрегатите не се оптимизират добре върху разделени таблици (освен ако колоната, която се агрегира, не е и колоната за разделяне). За това ограничение (което все още съществува в SQL Server 2014 CTP 1) е писано много пъти през годините; любимото ми отразяване е в тази статия от Ицик Бен-Ган. За да илюстрирате накратко проблема, разгледайте следната заявка:
SELECT MIN(SomeData) FROM dbo.T4;
Планът за изпълнение на SQL Server 2008 или по-нова версия е както следва:

Този план чете всички 150 000 реда от индекса и Stream Aggregate изчислява минималната стойност (планът за изпълнение е по същество същият, ако вместо това поискаме максималната стойност). Планът за изпълнение на SQL Server 2005 е малко по-различен (макар и не по-добър):
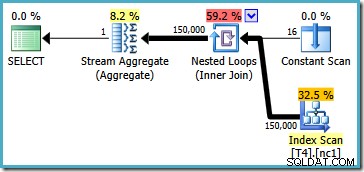
Този план повтаря номерата на дялове (изброени в Constant Scan), като сканира изцяло дял по един. Всичките 150 000 реда все още в крайна сметка се четат и обработват от Stream Aggregate.
Погледнете назад към разделената таблица и индексните диаграми и помислете как заявката може да бъде обработена по-ефективно в нашия набор от данни. Неклъстерираният индекс изглежда добър избор за разрешаване на заявката, тъй като съдържа стойности SomeData в ред, който може да бъде използван при изчисляване на агрегата.
Фактът, че индексът е разделен, усложнява малко нещата:всеки раздел на индекса се подрежда от колоната SomeData, но не можем просто да прочетем най-ниската стойност от която и да е конкретна дял, за да получите правилния отговор на цялата заявка.
След като се разбере основната природа на проблема, човек може да види, че ефективната стратегия би била да се намери най-ниската стойност на SomeData във всеки дял на индекса и след това вземете най-ниската стойност от резултатите за всеки дял.
Това по същество е решението, което Ицик представя в статията си; пренапишете заявката, за да изчислите агрегат за дял (използвайки APPLY синтаксис) и след това отново агрегирайте върху тези резултати за дял. Използвайки този подход, пренаписаният MIN заявката произвежда този план за изпълнение (вижте статията на Itzik за точния синтаксис):
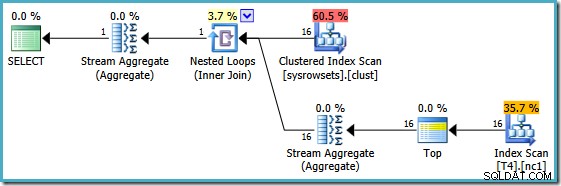
Този план чете номерата на дялове от системна таблица и извлича най-ниската стойност на SomeData във всеки дял. Окончателният Stream Aggregate просто изчислява минимума над резултатите за всеки дял.
Важната характеристика в този план е, че чете един ред от всеки дял (използвайки реда на сортиране на индекса във всеки дял). Той е много по-ефективен от плана на оптимизатора, който обработи всичките 150 000 реда в таблицата.
MIN и MAX в рамките на един дял
Сега помислете за следната заявка, за да намерите минималната стойност в колоната SomeData за диапазон от стойности на RowID, които се съдържат в рамките на един дял :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Видяхме, че оптимизаторът има проблеми с MIN и MAX върху множество дялове, но бихме очаквали тези ограничения да не се прилагат към заявка за един дял.
Единичният дял е този, ограничен от стойностите на RowID 10 000 и 20 000 (вижте дефиницията на функцията за разделяне). Функцията за разделяне беше дефинирана като RANGE RIGHT , така че граничната стойност от 10 000 принадлежи на дял #2, а границата от 20 000 принадлежи на дял #3. Следователно диапазонът от стойности на RowID, посочени от нашата нова заявка, се съдържа само в дял 2.
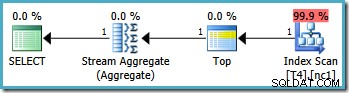
Графичните планове за изпълнение на тази заявка изглеждат еднакво във всички версии на SQL Server от 2005 г. нататък:
Анализ на плана
Оптимизаторът взе диапазона RowID, посочен в WHERE клауза и го сравни с дефиницията на функцията на дял, за да определи, че само дял 2 от неклъстерирания индекс трябва да бъде достъпен. Свойствата на плана на SQL Server 2005 за индексното сканиране показват ясно достъпа с един дял:
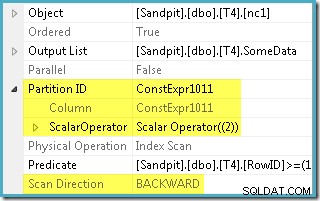
Другото подчертано свойство е посоката на сканиране. Редът на сканирането се различава в зависимост от това дали заявката търси минималната или максималната стойност на SomeData. Неклъстерираният индекс е подреден (на дял, запомнете) при нарастващи стойности на SomeData, така че посоката на сканиране на индекса е FORWARD ако заявката изисква минималната стойност и BACKWARD ако е необходима максималната стойност (екранната снимка по-горе е взета от MAX план на заявка).
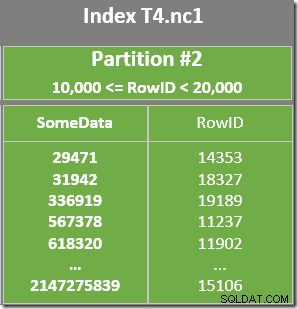
Също така има остатъчен предикат при сканирането на индекса, за да се провери дали стойностите на RowID, сканирани от дял 2, съвпадат с WHERE сказуемо предикат. Оптимизаторът приема, че стойностите на RowID се разпределят доста произволно чрез неклъстерирания индекс, така че очаква да намери първия ред, който съответства на WHERE сказуемо предикат доста бързо. Диаграмата за оформление на разделени данни показва, че стойностите на RowID наистина са доста произволно разпределени в индекса (който е подреден от колоната SomeData запомнете):
Операторът Top в плана на заявката ограничава сканирането на индекса до един ред (от долния или горния край на индекса в зависимост от посоката на сканиране). Индексните сканирания могат да бъдат проблематични в плановете за заявка, но операторът Top го прави ефективна опция тук:сканирането може да произведе само един ред, след което спира. Комбинацията от най-горното и подреденото сканиране на индекса ефективно извършва търсене до най-високата или най-ниската стойност в индекса, която също съответства на WHERE предикати на клауза. Агрегат на потока също се появява в плана, за да се гарантира, че NULL се генерира в случай, че не бъдат върнати редове от индексното сканиране. Скаларен MIN и MAX агрегатите са дефинирани да връщат NULL когато входът е празен набор.
Като цяло това е много ефективна стратегия и плановете имат прогнозна цена от само 0,0032921 единици като резултат. Дотук добре.
Проблемът с граничните стойности
Следващият пример променя горния край на диапазона RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Забележете, че заявката изключва стойността на 20 000 с помощта на оператор „по-малко от“. Припомнете си, че стойността 20 000 принадлежи на дял 3 (не на дял 2), тъй като функцията за дял е дефинирана като RANGE RIGHT . SQL Server2005 оптимизаторът се справя правилно с тази ситуация, създавайки оптималния план за заявка с един дял, с прогнозна цена от 0,0032878 :
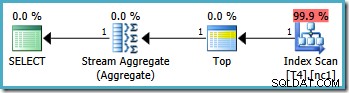
Същата заявка обаче произвежда различен план на SQL Server2008 и по-късно (включително SQL Server 2014 CTP 1):
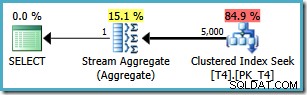
Сега имаме Clustered Index Seek (вместо желаната комбинация за индексно сканиране и Топ оператор). Всичките 5000 реда, които съответстват на WHERE клауза се обработват чрез Stream Aggregate в този нов план за изпълнение. Прогнозната цена на този план е 0,0199319 единици – повече отшест пъти цената на плана за SQL Server 2005.
Причина
Оптимизаторите на SQL Server 2008 (и по-нови) не разбират съвсем правилно вътрешната логика, когато се позовава на интервал, но изключва , гранична стойност, принадлежаща на различен дял. Оптимизаторът неправилно смята, че ще има достъп до множество дялове, и заключава, че не може да използва оптимизация с един дял за MIN и MAX агрегати.
Заобиколни решения
Една от опциите е да пренапишете заявката с помощта на оператори>=и <=, така че да не препращаме към гранична стойност от друг дял (дори да го изключим!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Това води до оптимален план, докосване на един дял:
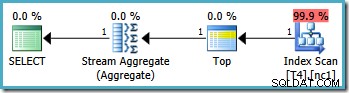
За съжаление, не винаги е възможно да се зададат правилни гранични стойности по този начин (в зависимост от типа на колоната за разделяне). Пример за това е с типовете дата и час, където е най-добре да използвате полуотворени интервали. Друго възражение срещу това заобикаляне е по-субективно:функцията за разделяне изключва една граница от диапазона, така че изглежда най-естествено да се напише заявката също така, като се използва синтаксис на полуотворен интервал.
Второто решение е да посочите изрично номера на дяла (и да запазите полуотворения интервал):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Това създава оптималния план, с цената на изискване на допълнителен предикат и разчитане на потребителя да определи какъв трябва да бъде номерът на дяла.
Разбира се, би било по-добре, ако оптимизаторите от 2008 г. и по-нови създадоха същия оптимален план, който направи SQL Server 2005. В един перфектен свят едно по-всеобхватно решение би се отнасяло и до случая с много дялове, което прави заобикалящото решение, което Ицик описва, също ненужно.