Много хора използват статистиката за изчакване като част от общата си методология за отстраняване на неизправности в производителността, както и аз, така че въпросът, който исках да проуча в тази публикация, е относно видовете чакане, свързани с режийните разходи на наблюдателя. Под режийни разходи на наблюдателя имам предвид въздействието върху пропускателната способност на работното натоварване на SQL Server, причинено от SQL Profiler, проследявания от страна на сървъра или сесии на разширени събития. За повече по темата за режийните наблюдатели вижте следните две публикации от моя колега Джонатан Кехайяс :
- Измерване на „режим на наблюдателя“ на SQL Trace спрямо разширени събития
- Въздействие на разширеното събитие query_post_execution_showplan в SQL Server 2012
Така че в тази публикация бих искал да мина през няколко варианта на наблюдателя над главата и да видя дали можем да намерим последователни типове изчакване, свързани с измереното влошаване. Има различни начини, по които потребителите на SQL Server прилагат проследяване в своите производствени среди, така че резултатите ви може да варират, но аз исках да покрия няколко широки категории и да докладвам за това, което открих:
- Използване на сесията на SQL Profiler
- Използване на проследяване от страна на сървъра
- Използване на проследяване от страна на сървъра, запис към бавен вход/изход
- Разширено използване на събития с цел за пръстен буфер
- Разширено използване на събития с целеви файл
- Използване на разширени събития с цел на файл на бавен вход/изход
- Разширено използване на събития с цел на файл по бавен вход/изход без загуба на събитие
Вероятно можете да измислите други варианти на темата и ви каня да споделите всякакви интересни констатации относно статистиката на наблюдателя и изчакването като коментар в тази публикация.
Основна линия
За теста използвах виртуална машина VMware с четири vCPU и 4 GB RAM. Моят гост на виртуална машина беше на OCZ Vertex SSD. Операционната система беше Windows Server 2008 R2 Enterprise, а версията на SQL Server е 2012, SP1 CU4.
Що се отнася до „работното натоварване“, използвам заявка само за четене в цикъл спрямо примерната база данни за кредит от 2008 г., настроена на GO 10 000 000 пъти.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Също така изпълнявам тази заявка чрез 16 едновременни сесии. Крайният резултат на моята тестова система е 100% използване на процесора във всички vCPU на виртуалния гост и средно 14 492 пакетни заявки в секунда за период от 2 минути.
По отношение на проследяването на събития, във всеки тест използвах Showplan XML Statistics Profile за SQL Profiler и тестове за проследяване от страна на сървъра – и query_post_execution_showplan за разширени сесии на събития. Събитията на плана за изпълнение са много скъпи, точно затова ги избрах, за да мога да видя дали при екстремни обстоятелства мога да извлека теми от тип чакане или не.
За тестване на натрупването на тип чакане през тестов период използвах следната заявка. Нищо фантастично – просто изчистване на статистиката, изчакване 2 минути и след това събиране на първите 10 натрупвания на чакане за екземпляра на SQL Server през периода на теста за влошаване:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Забележете, че не филтриране на фонови изчакващи типове, които обикновено се филтрират, и това е така, защото не исках да елиминирам нещо, което обикновено е доброкачествено – но при това обстоятелство всъщност сочи към реална област за по-нататъшно проучване.
Сесия на SQL Profiler
Следната таблица показва пакетните заявки преди и след в секунда при активиране на проследяване на локално проследяване на SQL Profiler Showplan XML Statistics Profile (работи на същата VM като екземпляра на SQL Server):
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки за сесия на SQL Profiler в секунда (средно 2 минути) |
|---|---|
| 14 492 | 1416 |
Можете да видите, че проследяването на SQL Profiler причинява значителен спад в пропускателната способност.
Що се отнася до натрупаното време за изчакване през същия период, най-добрите типове на изчакване бяха както следва (както и при останалите тестове в тази статия, направих няколко теста и резултатът като цяло беше последователен):
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67 142 | 1 149 824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 313 | 180 449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 086 |
| LAZYWRITER_SLEEP | 120 | 120 059 |
| DIRTY_PAGE_ANKETA | 1198 | 120 038 |
| HADR_WORK_QUEUE | 12 | 120 015 |
| LOGMGR_QUEUE | 937 | 120 011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
Типът на изчакване, който ми идва, е TRACEWRITE – който е дефиниран от Books Online като тип на изчакване, който „се появява, когато доставчикът на проследяване на набор от редове на SQL Trace изчаква или безплатен буфер, или буфер със събития за обработка“. Останалите типове на изчакване изглеждат като стандартни фонови типове изчакване, които обикновено се филтрират от вашия набор от резултати. Нещо повече, говорих за подобен проблем с прекомерното проследяване в статия през 2011 г., озаглавена Observer overhead – опасностите от твърде много проследяване – така че бях запознат с този тип чакане понякога правилно насочване към проблемите на наблюдателя. Сега в този конкретен случай, за който писах в блога, това не беше SQL Profiler, а друго приложение, използващо доставчика на проследяване на набор от редове (неефективно).
Проследяване от страна на сървъра
Това беше за SQL Profiler, но какво да кажем за режийното проследяване от страна на сървъра? Следната таблица показва пакетните заявки преди и след в секунда при разрешаване на записване на локална проследяване от страна на сървъра във файл:
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки на SQL Profiler за секунда (средно 2 минути) |
|---|---|
| 14 492 | 4015 |
Най-добрите типове изчакване бяха както следва (направих няколко теста и резултатът беше последователен):
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 015 |
| SLEEP_TASK | 253 | 180 871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 046 |
| HADR_WORK_QUEUE | 12 | 120 042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 021 |
| XE_DISPATCHER_WAIT | 3 | 120 006 |
| ЧАКАЙТЕ | 1 | 120 000 |
| LOGMGR_QUEUE | 931 | 119 993 |
| DIRTY_PAGE_ANKETA | 1193 | 119 958 |
| XE_TIMER_EVENT | 55 | 119 954 |
Този път не виждаме TRACEWRITE (сега използваме доставчик на файлове) и другият тип на изчакване, свързан с проследяване, недокументираният SQLTRACE_INCREMENTAL_FLUSH_SLEEP се изкачи нагоре – но в сравнение с първия тест, има много подобно натрупано време на изчакване (120 046 срещу 120 006) – и моята колежка Ерин Стелато (@erinstellato) говори за този конкретен тип чакане в публикацията си „Разбиране кога статистиката за чакане е изчистена за последно . Така че, гледайки другите типове чакащи, нито един не е надежден червен флаг.
Записване на трасиране от страна на сървъра към бавен вход/изход
Ами ако поставим файла за проследяване от страна на сървъра на бавен диск? Следната таблица показва пакетните заявки преди и след в секунда при активиране на локална трасировка от страна на сървъра, която записва във файл на USB устройство:
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки на SQL Profiler за секунда (средно 2 минути) |
|---|---|
| 14 492 | 260 |
Както виждаме – производителността е значително влошена – дори в сравнение с предишния тест.
Най-добрите типове чакане бяха следните:
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351 174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2273 | 299 995 |
| SLEEP_TASK | 240 | 194 264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181 458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125 007 |
| LAZYWRITER_SLEEP | 63 | 124 437 |
| LOGMGR_QUEUE | 941 | 120 559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120 516 |
| ЧАКАЙТЕ | 1 | 120 515 |
| DIRTY_PAGE_ANKETA | 1204 | 120 513 |
Един тип чакане, който изскача за този тест, е недокументираният SQLTRACE_FILE_BUFFER . Не е много документирано за това, но въз основа на името можем да направим обосновано предположение (особено като се има предвид конфигурацията на този конкретен тест).
Разширени събития към целта на пръстен буфер
След това нека прегледаме констатациите за еквиваленти на сесията с разширени събития. Използвах следната дефиниция на сесията:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
Следващата таблица показва пакетните заявки преди и след в секунда при активиране на XE сесия с цел на пръстен буфер (при улавяне на query_post_execution_showplan събитие):
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки на SQL Profiler за секунда (средно 2 минути) |
|---|---|
| 14 492 | 4737 |
Най-добрите типове чакане бяха следните:
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299 992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 006 |
| SLEEP_TASK | 240 | 181 739 |
| LAZYWRITER_SLEEP | 120 | 120 219 |
| HADR_WORK_QUEUE | 12 | 120 038 |
| DIRTY_PAGE_ANKETA | 1198 | 120 035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 011 |
| LOGMGR_QUEUE | 936 | 120 008 |
| ЧАКАЙТЕ | 1 | 120 001 |
Нищо не скочи като свързано с XE, само „шум“ на фоновата задача.
Разширени събития към целеви файл
Какво ще кажете за промяната на сесията, за да се използва цел на файл вместо цел на пръстен буфер? Следната таблица показва пакетните заявки преди и след в секунда при активиране на XE сесия с целеви файл вместо цел за пръстен буфер:
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки на SQL Profiler за секунда (средно 2 минути) |
|---|---|
| 14 492 | 4299 |
Най-добрите типове чакане бяха следните:
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2103 | 299 996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 253 | 180 663 |
| LAZYWRITER_SLEEP | 120 | 120 187 |
| HADR_WORK_QUEUE | 12 | 120 029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| ЧАКАЙТЕ | 1 | 120 001 |
| XE_TIMER_EVENT | 59 | 119 966 |
| LOGMGR_QUEUE | 935 | 119 957 |
Нищо, с изключение на XE_TIMER_EVENT , изскочи като свързано с XE. Хранилището за тип на изчакване на Боб Уорд посочва, че това е безопасно за игнориране, освен ако не е имало нещо възможно нередно – но реално бихте ли забелязали този обикновено доброкачествен тип чакане, ако беше на 9 място във вашата система по време на влошаване на производителността? И какво, ако вече го филтрирате поради нормалното му доброкачествен характер?
Разширени събития към бавен вход/изход файл цел
Ами ако сложа файла на бавен вход/изход? Следната таблица показва пакетните заявки преди и след в секунда при активиране на XE сесия с целеви файл на USB памет:
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки на SQL Profiler за секунда (средно 2 минути) |
|---|---|
| 14 492 | 4386 |
Най-добрите типове чакане бяха следните:
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 046 |
| SLEEP_TASK | 253 | 180 719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 427 |
| LAZYWRITER_SLEEP | 120 | 120 190 |
| HADR_WORK_QUEUE | 12 | 120 025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| ЧАКАЙТЕ | 1 | 120 002 |
| DIRTY_PAGE_ANKETA | 1197 | 119 977 |
| XE_TIMER_EVENT | 59 | 119 949 |
Отново нищо, свързано с XE, не изскача, освен XE_TIMER_EVENT .
Разширени събития до цел за бавен вход/изход на файла, без загуба на събитие
Следващата таблица показва пакетните заявки преди и след в секунда при активиране на XE сесия с целеви файл на USB памет, но този път без допускане на загуба на събитие (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – което не се препоръчва и ще видите в резултатите защо това може да бъде:
| Базови пакетни заявки за секунда (средно 2 минути) | Пакетни заявки на SQL Profiler за секунда (средно 2 минути) |
|---|---|
| 14 492 | 539 |
Най-добрите типове чакане бяха следните:
| тип_чакане | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8773 | 1 707 845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 337 | 180 446 |
| LAZYWRITER_SLEEP | 120 | 120 032 |
| DIRTY_PAGE_ANKETA | 1198 | 120 026 |
| HADR_WORK_QUEUE | 12 | 120 009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
| ЧАКАЙТЕ | 1 | 120 000 |
| XE_TIMER_EVENT | 59 | 119 944 |
С екстремното намаляване на пропускателната способност виждаме XE_BUFFERMGR_FREEBUF_EVENT скочи до позиция номер едно в нашите натрупани резултати от времето за изчакване. Този е документирано в Books Online и Microsoft ни казва, че това събитие е свързано с XE сесии, конфигурирани без загуба на събития и където всички буфери в сесията са пълни.
Влияние на наблюдателя
Като оставим настрана видовете изчакване, беше интересно да се отбележи какво влияние оказва всеки метод на наблюдение върху способността на нашето работно натоварване да обработва пакетни заявки:
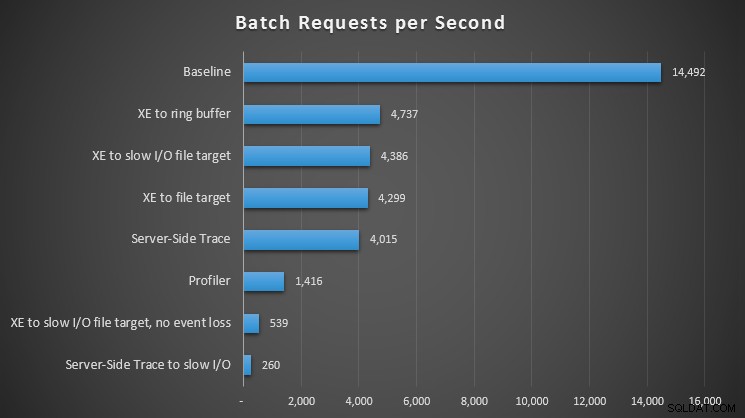
Влияние на различните методи за наблюдение върху пакетните заявки в секунда
За всички подходи имаше значително – но не шокиращо – удар в сравнение с нашето изходно ниво (без наблюдение); най-много болка обаче се усеща при използване на Profiler, когато се използва проследяване от страна на сървъра към бавен вход/изход или разширени събития към файл цел по бавен вход/изход – но само когато е конфигуриран без загуба на събития. При загуба на събитие тази настройка действително се изпълняваше наравно с целта на файла към бърз I/O път, вероятно защото успя да изпусне много повече събития.
Резюме
Не тествах всеки възможен сценарий и със сигурност има други интересни комбинации (да не говорим за различни поведения, базирани на версията на SQL Server), но ключовото заключение, което правя от това изследване, е, че не можете винаги да разчитате на очевидно натрупване на изчакване показалец, когато сте изправени пред сценарий отгоре на наблюдателя. Въз основа на тестовете в тази публикация, само три от седемте сценария показват специфичен тип изчакване, което потенциално може да ви помогне да ви насочи в правилната посока. Дори тогава – тези тестове бяха на контролирана система – и често хората филтрират гореспоменатите типове изчакване като доброкачествени фонови типове – така че може да не ги видите изобщо.
Имайки предвид това, какво можете да направите? За влошаване на производителността без ясни или очевидни симптоми, препоръчвам да разширите обхвата, за да попитате за следи и XE сесии (като настрана – препоръчвам също да разширите обхвата си, ако системата е виртуализирана или може да има неправилни опции за захранване). Например, като част от отстраняването на неизправности в системата, проверете sys.[traces] и sys.[dm_xe_sessions] за да видите дали в системата работи нещо, което е неочаквано. Това е допълнителен слой към това, за което трябва да се тревожите, но извършването на няколко бързи проверки може да ви спести значително време.



