[ Част 1 | Част 2 | Част 3 | Част 4 ]
MERGE израз (въведен в SQL Server 2008) ни позволява да изпълняваме смес от INSERTs , UPDATE и DELETE операции с помощта на един израз. Проблемите със защитата на Хелоуин за MERGE са предимно комбинация от изискванията на отделните операции, но има някои важни разлики и няколко интересни оптимизации, които важат само за MERGE .
Избягване на проблема с Хелоуин с MERGE
Започваме с разглеждане отново на примера за демонстрация и постановка от част втора:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Както може би си спомняте, този пример беше използван, за да покаже, че INSERTs изисква Хелоуин защита, когато таблицата за вмъкване на целеви елементи също е посочена в SELECT част от заявката (EXISTS клауза в този случай). Правилното поведение за INSERTs изявлението по-горе е да се опитате да добавите и двете 1234 стойности и следователно да се провали с PRIMARY KEY нарушение. Без разделяне на фазите, INSERTs ще добави неправилно една стойност, завършвайки без да бъде изхвърлена грешка.
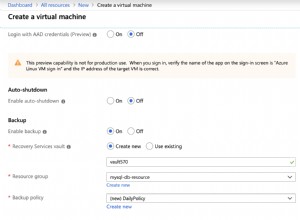
Планът за изпълнение INSERT
Кодът по-горе има една разлика от този, използван във втора част; е добавен неклъстериран индекс към таблицата за етапи. INSERTs план за изпълнение все още изисква обаче Хелоуин защита:
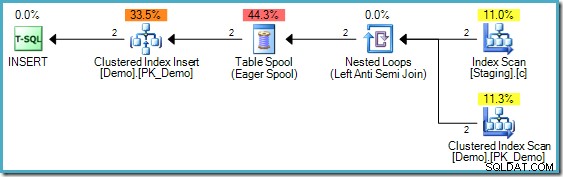
Планът за изпълнение на MERGE
Сега опитайте същото логическо вмъкване, изразено с помощта на MERGE синтаксис:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
В случай, че не сте запознати със синтаксиса, логиката там е да сравнявате редове в таблиците Staging и Demo на стойността SomeKey и ако не бъде намерен съвпадащ ред в целевата (Демо) таблицата, ние вмъкваме нов ред. Това има точно същата семантика като предишния INSERT...WHERE NOT EXISTS код, разбира се. Планът за изпълнение обаче е доста различен:
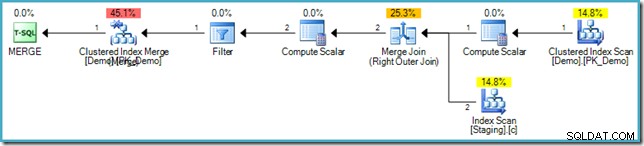
Забележете липсата на Eager Table Spool в този план. Въпреки това, заявката все още произвежда правилното съобщение за грешка. Изглежда SQL Server е намерил начин да изпълни MERGE планирайте итеративно, като спазвате логическото разделяне на фазите, изисквано от стандарта SQL.
Оптимизацията за запълване на дупки
При правилните обстоятелства оптимизаторът на SQL Server може да разпознае, че MERGE изявлението запълва дупки , което е просто още един начин да се каже, че изразът добавя само редове, където има съществуваща празнина в ключа на целевата таблица.
За да бъде приложена тази оптимизация, стойностите, използвани в WHEN NOT MATCHED BY TARGET клаузата трябва точно съвпада с ON част от USING клауза. Освен това целевата таблица трябва да има уникален ключ (изискване, удовлетворено от PRIMARY KEY в настоящия случай). Когато тези изисквания са изпълнени, MERGE изявлението не изисква защита от проблема с Хелоуин.
Разбира се, MERGE изявлението е логично без повече или по-малко запълване на дупки отколкото оригиналния INSERT...WHERE NOT EXISTS синтаксис. Разликата е, че оптимизаторът има пълен контрол върху внедряването на MERGE оператор, докато INSERTs синтаксисът ще изисква от него да разсъждава за по-широката семантика на заявката. Човек може лесно да види, че INSERTs също запълва дупки, но оптимизаторът не мисли за нещата по същия начин, по който ние.
За илюстриране на точното съвпадение изискване, което споменах, помислете за следния синтаксис на заявката, който не възползвайте се от оптимизацията за запълване на дупки. Резултатът е пълна защита за Хелоуин, осигурена от Eager Table Spool:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Единствената разлика е умножението по едно в VALUES клауза – нещо, което не променя логиката на заявката, но което е достатъчно, за да предотврати прилагането на оптимизация за запълване на дупки.
Запълване на дупки с вложени цикли
В предишния пример оптимизаторът избра да обедини таблиците с помощта на обединяване за сливане. Оптимизацията за запълване на дупки може също да се приложи, когато е избрано съединение с вложени цикли, но това изисква допълнителна гаранция за уникалност на таблицата източник и търсене на индекс от вътрешната страна на съединението. За да видим това в действие, можем да изчистим съществуващите данни за етапа, да добавим уникалност към неклъстерирания индекс и да опитаме MERGE отново:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Полученият план за изпълнение отново използва оптимизацията за запълване на дупки, за да избегне защитата на Хелоуин, използвайки присъединяване на вложени цикли и търсене от вътрешната страна в целевата таблица:
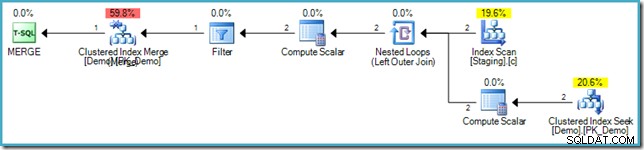
Избягване на ненужни обиколки на индекс
Когато се прилага оптимизацията за запълване на дупки, двигателят може да приложи и допълнителна оптимизация. Може да запомни текущата позиция на индекса, докато чете целевата таблица (обработване на един ред наведнъж, запомнете) и използвайте повторно тази информация при извършване на вмъкването, вместо да търсите надолу по b-дървото, за да намерите местоположението на вмъкване. Причината е, че текущата позиция за четене е много вероятно да бъде на същата страница, където трябва да се вмъкне новият ред. Проверката дали редът действително принадлежи на тази страница е много бърза, тъй като включва проверка само на най-ниския и най-високия ключ, който в момента се съхранява там.
Комбинацията от елиминиране на Eager Table Spool и запазване на навигация на индекс на ред може да осигури значителна полза при натоварванията на OLTP, при условие че планът за изпълнение се извлича от кеша. Цената на компилацията за MERGE операторите е по-скоро по-висока, отколкото за INSERTs , UPDATE и DELETE , така че повторното използване на плана е важно съображение. Също така е полезно да се уверите, че страниците имат достатъчно свободно пространство за поставяне на нови редове, като се избягват разделянето на страници. Това обикновено се постига чрез нормална поддръжка на индекса и присвояване на подходящ FILLFACTOR .
Споменавам OLTP работни натоварвания, които обикновено включват голям брой относително малки промени, тъй като MERGE оптимизациите може да не са добър избор, когато голям брой са редове, обработени на оператор. Други оптимизации като минимално регистрирани INSERTs в момента не може да се комбинира с запълване на дупки. Както винаги, характеристиките на производителността трябва да бъдат бенчмаркирани, за да се гарантира, че очакваните ползи са реализирани.
Оптимизацията за запълване на дупки за MERGE вмъкванията могат да се комбинират с актуализации и изтривания, като се използва допълнителен MERGE клаузи; всяка операция за промяна на данни се оценява отделно за проблема за Хелоуин.
Избягване на присъединяването
Окончателната оптимизация, която ще разгледаме, може да се приложи там, където MERGE операторът съдържа операции за актуализиране и изтриване, както и вмъкване за запълване на дупки, а целевата таблица има уникален клъстериран индекс. Следният пример показва често срещан MERGE модел, при който се вмъкват несъответстващи редове, а съвпадащите редове се актуализират или изтриват в зависимост от допълнително условие:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
MERGE изявлението, необходимо за извършване на всички необходими промени, е забележително компактно:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Планът за изпълнение е доста изненадващ:

Няма защита за Хелоуин, няма свързване между изходната и целевата таблици и рядко ще видите оператор за вмъкване на клъстериран индекс, последван от сливане на клъстериран индекс към същата таблица. Това е друга оптимизация, насочена към OLTP работни натоварвания с многократно използване на планове и подходящо индексиране.
Идеята е да прочетете ред от таблицата на източника и веднага да опитате да го вмъкнете в целта. Ако се получи ключово нарушение, грешката се потиска, операторът Insert извежда конфликтния ред, който е открил, и този ред след това се обработва за операция за актуализиране или изтриване, като се използва операторът за план за сливане както обикновено.
Ако оригиналното вмъкване успее (без ключово нарушение), обработката продължава със следващия ред от източника (операторът Merge обработва само актуализации и изтривания). Тази оптимизация е от полза преди всичко за MERGE заявки, при които повечето изходни редове водят до вмъкване. Отново се изисква внимателен сравнителен анализ, за да се гарантира, че производителността е по-добра от използването на отделни изявления.
Резюме
MERGE изявлението предоставя няколко уникални възможности за оптимизация. При правилните обстоятелства може да избегне необходимостта от добавяне на изрична защита за Хелоуин в сравнение с еквивалентен INSERTs операция или може би дори комбинация от INSERTs , UPDATE и DELETE изявления. Допълнително MERGE -специфичните оптимизации могат да избегнат обхода на индексното b-дърво, което обикновено е необходимо за намиране на позицията на вмъкване за нов ред, и може също така да избегнат необходимостта от пълно присъединяване на изходната и целевата таблица.
В последната част от тази серия ще разгледаме как оптимизаторът на заявки обосновава необходимостта от защита за Хелоуин и ще идентифицираме още някои трикове, които може да използва, за да избегне необходимостта от добавяне на Eager Table Spools към планове за изпълнение, които променят данните.
[ Част 1 | Част 2 | Част 3 | Част 4 ]