Зареждането на трансформация на извличане (ETL) е гръбнакът за всяко хранилище за данни. В света на хранилището за данни данните се управляват от ETL процеса, който се състои от три процеса, извличане-извличане/придобиване на данни от източници, данни за промяна на трансформацията в необходимия формат и зареждане и изпращане на данни до местоназначението обикновено в склад за данни или витрина с данни.
Научете SSIS и започнете своя безплатен пробен период днес!
SQL Server Integration Services (SSIS) е инструментът от семейството ETL, който е полезен за разработване и управление на корпоративно хранилище за данни. Склад за данни по собствена характеристика работи върху огромен обем данни и производителността е голямо предизвикателство при управлението на огромен обем данни за всеки архитект или DBA.
Съображения за подобряване на ETL
Днес ще обсъдя колко лесно можете да подобрите производителността на ETL или да проектирате високопроизводителна ETL система с помощта на SSIS. За по-добро разбиране ще разделя десет метода в две различни категории; първо, съображения за времето за проектиране на пакета SSIS и второ конфигуриране на различни стойности на свойствата на компонентите, налични в пакета SSIS.
Съображения по време на проектиране на пакета SSIS
#1 Успоредно извличане на данни:SSIS предоставя начин за извличане на данни паралелно с помощта на контейнери за последователност в потока за управление. Можете да проектирате пакет по такъв начин, че да може да изтегля данни от независими таблици или файлове паралелно, което ще помогне за намаляване на общото време за изпълнение на ETL.
#2 Извличане на необходимите данни:изтеглете само необходимия набор от данни от всяка таблица или файл. Трябва да избягвате тенденцията да изтегляте всичко налично от източника за сега, който ще използвате в бъдеще; той изяжда мрежовата честотна лента, консумира системни ресурси (I/O и CPU), изисква допълнително съхранение и влошава цялостната производителност на ETL системата.
Ако вашата ETL система е наистина динамична по своята същност и изискванията ви често се променят, би било по-добре да обмислите други подходи за проектиране, като управляван от мета данни ETL и т.н., вместо да проектирате, за да привлечете всичко наведнъж.
#3 Избягвайте използването на компоненти за асинхронна трансформация:SSIS е богат инструмент с набор от компоненти за трансформация за постигане на сложни задачи по време на изпълнение на ETL, но в същото време ви струва много, ако тези компоненти не се използват правилно.
Две категории компоненти за трансформация са налични в SSIS:Синхронни и Асинхронен .
Синхронните трансформации са тези компоненти, които обработват всеки ред и натискат надолу към следващия компонент/назначение, той използва разпределена буферна памет и не изисква допълнителна памет, тъй като е пряка връзка между входно/изходен ред с данни, който се вписва напълно в разпределената памет. Компоненти като търсене, извлечени колони и преобразуване на данни и т.н. попадат в тази категория.
Асинхронните трансформации са онези компоненти, които първо съхраняват данни в буферната памет, след което обработват операции като сортиране и агрегатиране. Необходима е допълнителна буферна памет за изпълнение на задачата и докато буферната памет е налична, тя задържа всички данни в паметта и блокира транзакцията, известна също като блокираща трансформация. За да изпълни задачата, SSIS двигателят (движител на тръбопровода на потока от данни) ще задели допълнителна буферна памет, което отново е излишно за ETL системата. Компоненти като Сортиране, Обединяване, Обединяване, Присъединяване и др. попадат в тази категория.
Като цяло трябва да избягвате асинхронни трансформации, но все пак, ако попаднете в ситуация, в която нямате друг избор, тогава трябва да сте наясно как да се справите с наличните стойности на свойствата на тези компоненти. Ще ги обсъдя по-късно в тази статия.
#4 Оптимално използване на събития в манипулаторите на събития:за проследяване на напредъка на изпълнение на пакета или предприемане на друго подходящо действие за конкретно събитие, SSIS предоставя набор от събития. Събитията са много полезни, но прекомерното използване на събития ще струва допълнителни разходи при изпълнение на ETL.
Тук трябва да потвърдите всички характеристики, преди да активирате събитие в пакета SSIS.
#5 Трябва да сте наясно със схемата на таблицата на местоназначението, когато работите върху огромен обем данни. Трябва да помислите два пъти, когато трябва да изтеглите огромен обем данни от източника и да ги изпратите в хранилище за данни или витрина с данни. Може да видите проблеми с производителността, когато се опитвате да изпратите огромни данни в местоназначението с комбинация от операции за вмъкване, актуализиране и изтриване (DML), тъй като може да има вероятност таблицата на местоназначението да има клъстерирани или неклъстерирани индекси, което може да причини много разбъркване на данни в паметта поради DML операции.
Ако ETL има проблеми с производителността поради огромно количество DML операции на таблица, която има индекс, трябва да направите подходящи промени в ETL дизайна, като например да премахнете съществуващите клъстерни индекси във фазата на предварително изпълнение и да създадете отново всички индекси във фазата след изпълнение. Може да намерите други по-добри алтернативи за разрешаване на проблема въз основа на вашата ситуация.
Конфигуриране на свойства на компонентите
#6 Контролирайте паралелното изпълнение на задача чрез конфигуриране на MaxConcurrentExecutables и EngineThreads Имот. Задачите за SSIS пакет и поток от данни имат свойство да контролират паралелното изпълнение на задача:MaxConcurrentExecutables е свойството на ниво пакет и има стойност по подразбиране -1 , което означава, че максималният брой задачи, които могат да бъдат изпълнени, е равен на общия брой процесори на машината плюс два;
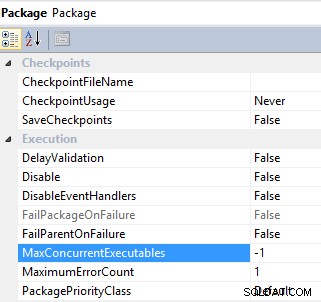
Пакет
EngineThreads е свойство на ниво задача на поток от данни и има стойност по подразбиране от 10, което определя общия брой нишки, които могат да бъдат създадени за изпълнение на задачата за поток от данни.
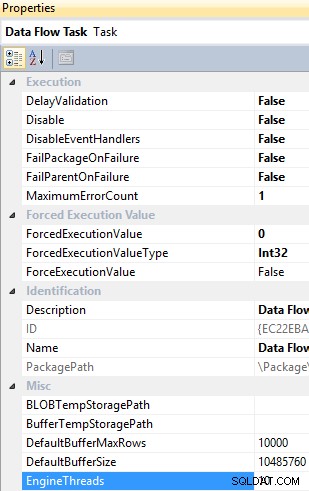
Задача за поток от данни
Можете да промените стойностите по подразбиране на тези свойства според нуждите на ETL и наличността на ресурси.
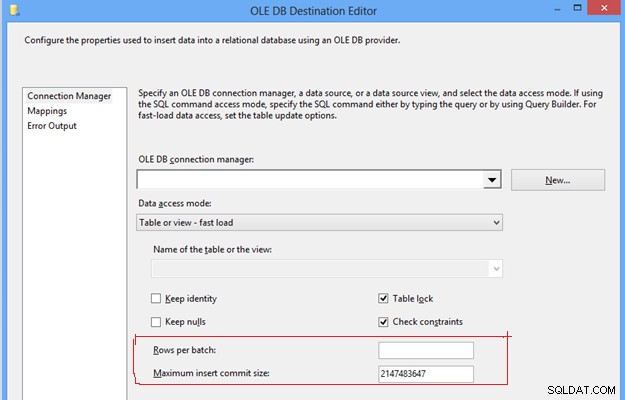
#7 Конфигурирайте опцията за режим на достъп до данни в OLEDB Destination. В задачата за поток от данни SSIS можем да намерим дестинацията OLEDB, която предоставя няколко опции за изтласкване на данни в таблицата на местоназначението, под режима за достъп до данни; първо, опцията „Таблица или изглед“, която вмъква ред по ред; второ, опцията „Бързо зареждане на таблица или преглед“, която вътрешно използва израза за групово вмъкване за изпращане на данни в целевата таблица, което винаги осигурява по-добра производителност в сравнение с други опции. След като изберете опцията „бързо зареждане“, тя ви дава повече контрол за управление на поведението на таблицата на местоназначението по време на операция за изпращане на данни, като „Запазване на идентичност“, „Запазване на нулеви стойности“, „Заключване на таблица“ и „Проверка на ограниченията“.
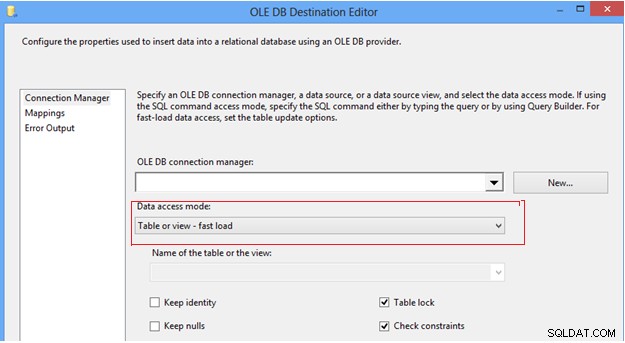
OLE DB Destination Editor
Силно препоръчително е да използвате опцията за бързо зареждане, за да изпратите данни в целевата таблица, за да подобрите ефективността на ETL.
#8, Конфигуриране на редове за партида и максимален размер за вмъкване в OLEDB дестинация. Тези две настройки са важни за контролиране на производителността на tempdb и регистрационния файл на транзакциите, тъй като с дадените стойности по подразбиране на тези свойства той ще изтласка данни в целевата таблица под една партида и една транзакция. Това ще изисква прекомерно използване на tembdb и регистър на транзакциите, което се превръща в проблем с производителността на ETL поради прекомерната консумация на памет и дисково съхранение.
OLE DB Destination Editor
За да подобрите производителността на ETL, можете да поставите положителна стойност на цяло число и в двете свойства въз основа на очаквания обем данни, което ще помогне за разделянето на цял куп данни на множество пакети, а данните в групата отново могат да бъдат записани в таблицата на местоназначението в зависимост от определена стойност. Това ще избегне прекомерната употреба на tempdb и регистър на транзакциите, което ще помогне за подобряване на производителността на ETL.
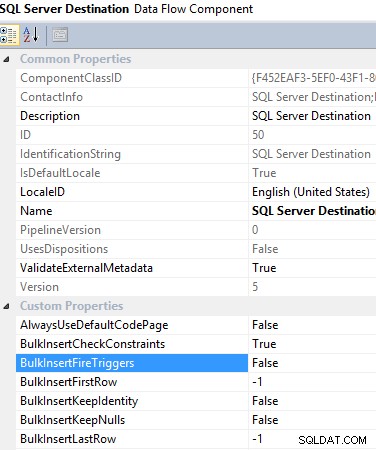
#9 Използване на SQL Server Destination в задача за поток от данни. Когато искате да изпратите данни в локална база данни на SQL Server, силно се препоръчва да използвате SQL Server Destination, тъй като предоставя много предимства за преодоляване на ограниченията на други опции, което ви помага да подобрите производителността на ETL. Например, той използва функцията за групово вмъкване, която е вградена в SQL Server, но ви дава възможност да приложите трансформация, преди да заредите данни в целевата таблица. Освен това ви дава възможност да активирате/деактивирате тригера, който да се задейства при зареждане на данни, което също помага за намаляване на разходите за ETL.
Компонент на потока от данни за цел на SQL сървър
#10 Избягвайте имплицитно привеждане на типа. Когато данните идват от плосък файл, мениджърът на връзката с плосък файл третира всички колони като низов (DS_STR) тип данни, включително числови колони. Както знаете, SSIS използва буферна памет за съхраняване на целия набор от данни и прилага необходимата трансформация, преди да изтласка данните в таблицата на местоназначението. Сега, когато всички колони са низови типове данни, това ще изисква повече място в буфера, което ще намали производителността на ETL.
За да подобрите производителността на ETL, трябва да преобразувате всички числови колони в подходящия тип данни и да избягвате имплицитно преобразуване, което ще помогне на SSIS машината да побере повече редове в един буфер.
Обобщение на подобренията в производителността на ETL
В тази статия проучихме колко лесно може да се контролира ефективността на ETL във всеки един момент. Това са 10 често срещани начина за подобряване на производителността на ETL. Може да има повече методи, базирани на различни сценарии, чрез които производителността може да се подобри.
Като цяло, с помощта на категоризация можете да определите как да се справите със ситуацията. Ако сте във фаза на проектиране на хранилище за данни, може да се наложи да се концентрирате и върху двете категории, но ако поддържате някаква наследена система, тогава първо работете отблизо върху втората категория.