Първичният и външният ключ са фундаментални характеристики на релационните бази данни, както първоначално е отбелязано в статията на E.F. Codd, „Релационен модел на данни за големи споделени банки данни“, публикувана през 1970 г. Често повтаряният цитат е „Ключът, целият ключ, и нищо освен ключа, така че помогни ми Код."
Фон:Първични ключове
Първичният ключ е ограничение в SQL Server, което действа за уникално идентифициране на всеки ред в таблица. Ключът може да бъде дефиниран като единична колона, различна от NULL, или комбинация от колони без NULL, която генерира уникална стойност и се използва за налагане на целостта на обекта за таблица. Таблицата може да има само един първичен ключ и когато за таблица е дефинирано ограничение на първичен ключ, се създава уникален индекс. Този индекс ще бъде клъстериран индекс по подразбиране, освен ако не е посочен като неклъстериран индекс, когато е дефинирано ограничението на първичния ключ.
Помислете за Sales.SalesOrderHeader таблица в AdventureWorks2012 база данни. Тази таблица съдържа основна информация за поръчка за продажба, включително дата на поръчката и идентификатор на клиента и всяка продажба е уникално идентифицирана чрез SalesOrderID , който е първичен ключ за таблицата. Всеки път, когато към таблицата се добавя нов ред, ограничението на първичния ключ (с име PK_SalesOrderHeader_SalesOrderID ) се проверява, за да се гарантира, че вече не съществува ред със същата стойност за SalesOrderID .
Външни ключове
Отделни от първичните ключове, но много свързани, са външните ключове. Външен ключ е колона или комбинация от колони, която е същата като първичния ключ, но в различна таблица. Външните ключове се използват за дефиниране на връзка и налагане на целостта между две таблици.
За да продължите да използвате гореспоменатия пример, SalesOrderID колоната съществува като външен ключ в Sales.SalesOrderDetail таблица, където се съхранява допълнителна информация за продажбата, като идентификатор на продукта и цена. Когато се добави нова продажба към SalesOrderHeader таблица, не е необходимо да добавяте ред за тази продажба към SalesOrderDetail таблица Въпреки това, когато добавяте ред към SalesOrderDetail таблица, съответен ред за SalesOrderID трябва съществуват в SalesOrderHeader таблица.
Обратно, когато изтривате данни, ред за конкретен SalesOrderID може да бъде изтрит по всяко време от SalesOrderDetail таблица, но за да бъде изтрит ред от SalesOrderHeader таблица, свързани редове от SalesOrderDetail ще трябва първо да се изтрие.
За разлика от ограниченията на първичния ключ, когато ограничение за външен ключ е дефинирано за таблица, индекс не се създава по подразбиране от SQL Server. Въпреки това, не е необичайно разработчиците и администраторите на бази данни да ги добавят ръчно. Външният ключ може да бъде част от съставен първичен ключ за таблицата, в който случай би съществувал клъстериран индекс с външния ключ като част от ключа за клъстериране. Като алтернатива, заявките може да изискват индекс, който включва външния ключ и една или повече допълнителни колони в таблицата, така че ще бъде създаден неклъстериран индекс, който да поддържа тези заявки. Освен това, индексите на външни ключове могат да осигурят ползи за производителността за обединения на таблици, включващи първичния и външния ключ, и могат да повлияят на производителността, когато стойността на първичния ключ се актуализира или ако редът бъде изтрит.
В AdventureWorks2012 база данни, има една таблица, SalesOrderDetail , с SalesOrderID като външен ключ. За SalesOrderDetail таблица, SalesOrderID и SalesOrderDetailID комбинирайте, за да образувате първичен ключ, поддържан от клъстериран индекс. Ако SalesOrderDetail таблицата нямаше индекс в SalesOrderID колона, след това, когато един ред се изтрие от SalesOrderHeader , SQL Server ще трябва да провери дали няма редове за същия SalesOrderID стойност съществува. Без никакви индекси, които съдържат SalesOrderID колона, SQL Server ще трябва да извърши пълно сканиране на таблицата на SalesOrderDetail . Както можете да си представите, колкото по-голяма е посочената таблица, толкова по-дълго ще отнеме изтриването.
Пример
Можем да видим това в следния пример, който използва копия на гореспоменатите таблици от AdventureWorks2012 база данни, които са разширени с помощта на скрипт, който можете да намерите тук. Скриптът е разработен от Jonathan Kehayias (блог | @SQLPoolBoy) и създава SalesOrderHeaderEnlarged таблица с 1 258 600 реда и SalesOrderDetailEnlarged таблица с 4 852 680 реда. След като скриптът беше стартиран, ограничението за външния ключ беше добавено с помощта на операторите по-долу. Имайте предвид, че ограничението се създава с ON DELETE CASCADE опция. С тази опция, когато се издава актуализация или изтриване срещу SalesOrderHeaderEnlarged таблица, редове в съответната таблица(и) – в този случай просто SalesOrderDetailEnlarged – се актуализират или изтриват.
В допълнение, клъстерираният индекс по подразбиране за SalesOrderDetailEnglarged беше премахнат и пресъздаден, за да има само SalesOrderDetailID като първичен ключ, тъй като представлява типичен дизайн.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
С ограничението на външния ключ и без поддържащ индекс, беше издадено едно изтриване срещу SalesOrderHeaderEnlarged таблица, което доведе до премахването на един ред от SalesOrderHeaderEnlarged и 72 реда от SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Статистическите IO и информацията за времето показаха следното:
Време за анализиране и компилиране на SQL Server:Време на процесора =8 ms, изминало време =8 ms.
Таблица 'SalesOrderDetailEnlarged'. Брой на сканиране 1, логически четения 50647, физически четения 8, четене напред 50667, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Таблица „Работна маса“. Брой на сканиране 2, логическо четене 7, физическо четене 0, четене напред 0, логически четене на лоб 0, физическо четене на лоб 0, четене напред в лоб четене 0.
Таблица 'SalesOrderHeaderEnlarged'. Брой на сканиране 0, логически четения 15, физически четения 14, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Време за изпълнение на SQL Server:
Време на процесора =1045 ms, изминало време =1898 ms.
Използвайки SQL Sentry Plan Explorer, планът за изпълнение показва клъстерно сканиране на индекс срещу SalesOrderDetailEnlarged тъй като няма индекс на SalesOrderID :
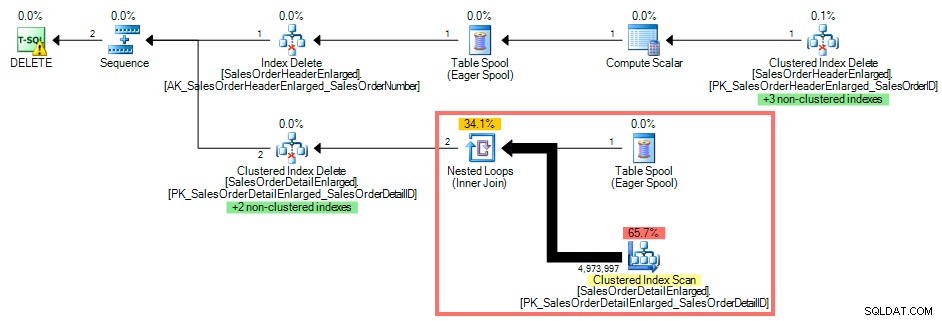
План за заявка без индекс на външния ключ
Неклъстерираният индекс за поддръжка на SalesOrderDetailEnlarged след това беше създаден с помощта на следния израз:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Беше извършено друго изтриване за SalesOrderID който засегна един ред в SalesOrderHeaderEnlarged и 72 реда в SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Статистическите IO и информацията за времето показаха драматично подобрение:
Време за анализиране и компилиране на SQL Server:Време на процесора =0 ms, изминало време =7 ms.
Таблица 'SalesOrderDetailEnlarged'. Брой на сканиране 1, логически четения 48, физически четения 13, четене напред за четене 0, логически четения на лоб 0, физически четения на лоб 0, четене напред в лоб четене 0.
Таблица „Работна маса“. Брой на сканиране 2, логическо четене 7, физическо четене 0, четене напред 0, логически четене на лоб 0, физическо четене на лоб 0, четене напред в лоб четене 0.
Таблица 'SalesOrderHeaderEnlarged'. Брой на сканирането 0, логически четения 15, физически четения 15, четене напред 0, логически четения на лоб 0, физически четения на лоб 0, четене напред за четене 0.
Време за изпълнение на SQL Server:
Време на процесора =0 ms, изминало време =27 ms.
И планът на заявката показа търсене на индекс на неклъстерирания индекс на SalesOrderID , както се очаква:
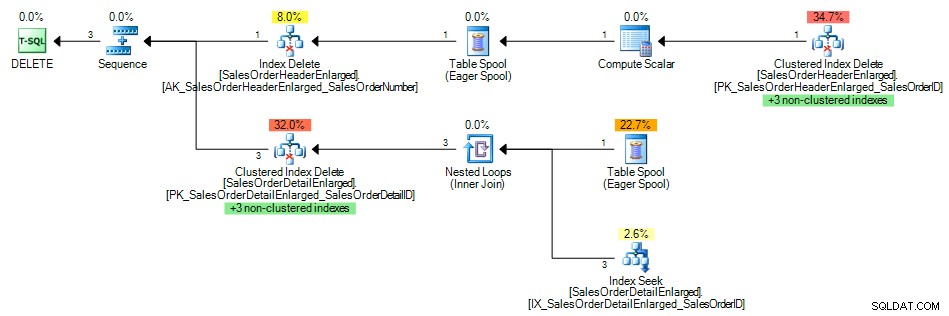
План на заявка с индекс на външния ключ
Времето за изпълнение на заявката спадна от 1898 ms на 27 ms – 98,58% намаление и се чете за SalesOrderDetailEnlarged таблицата намаля от 50647 на 48 – подобрение от 99,9%. Като оставим настрана процентите, помислете само за I/O, генериран от изтриването. SalesOrderDetailEnlarged таблицата е само 500 MB в този пример и за система с 256 GB налична памет, таблица, която заема 500 MB в кеша на буфера, не изглежда като ужасна ситуация. Но таблица от 5 милиона реда е сравнително малка; повечето големи OLTP системи имат таблици със стотици милиони редове. Освен това не е необичайно да съществуват множество препратки към външни ключове за първичен ключ, където изтриването на първичния ключ изисква изтриване от множество свързани таблици. В този случай е възможно да видите удължени срокове за изтривания, което е не само проблем с производителността, но и проблем с блокирането, в зависимост от нивото на изолация.
Заключение
Обикновено се препоръчва да се създаде индекс, който води до колоната(ите) на външния ключ, за да поддържа не само свързвания между първичния и външния ключ, но също и актуализиране и изтриване. Имайте предвид, че това е обща препоръка, тъй като има крайни сценарии, при които допълнителният индекс на външния ключ не е бил използван поради изключително малкия размер на таблицата, а допълнителните актуализации на индекса всъщност са се отразили отрицателно на производителността. Както при всички модификации на схемата, добавянето на индекс трябва да се тества и наблюдава след внедряването. Важно е да се гарантира, че допълнителните индекси дават желаните ефекти и да не влияят отрицателно върху производителността на решението. Също така си струва да се отбележи колко допълнително пространство се изисква от индексите за външните ключове. Това е от съществено значение да се вземе предвид преди създаването на индексите и ако те предоставят полза, трябва да се има предвид при планирането на капацитета занапред.